Python: Pandas的DataFrame如何按指定list排序
本文首发于微信公众号“Python数据之道”(ID:PyDataRoad)
前言
写这篇文章的起由是有一天微信上一位朋友问到一个问题,问题大体意思概述如下:
现在有一个pandas的Series和一个python的list,想让Series按指定的list进行排序,如何实现?
这个问题的需求用流程图描述如下:
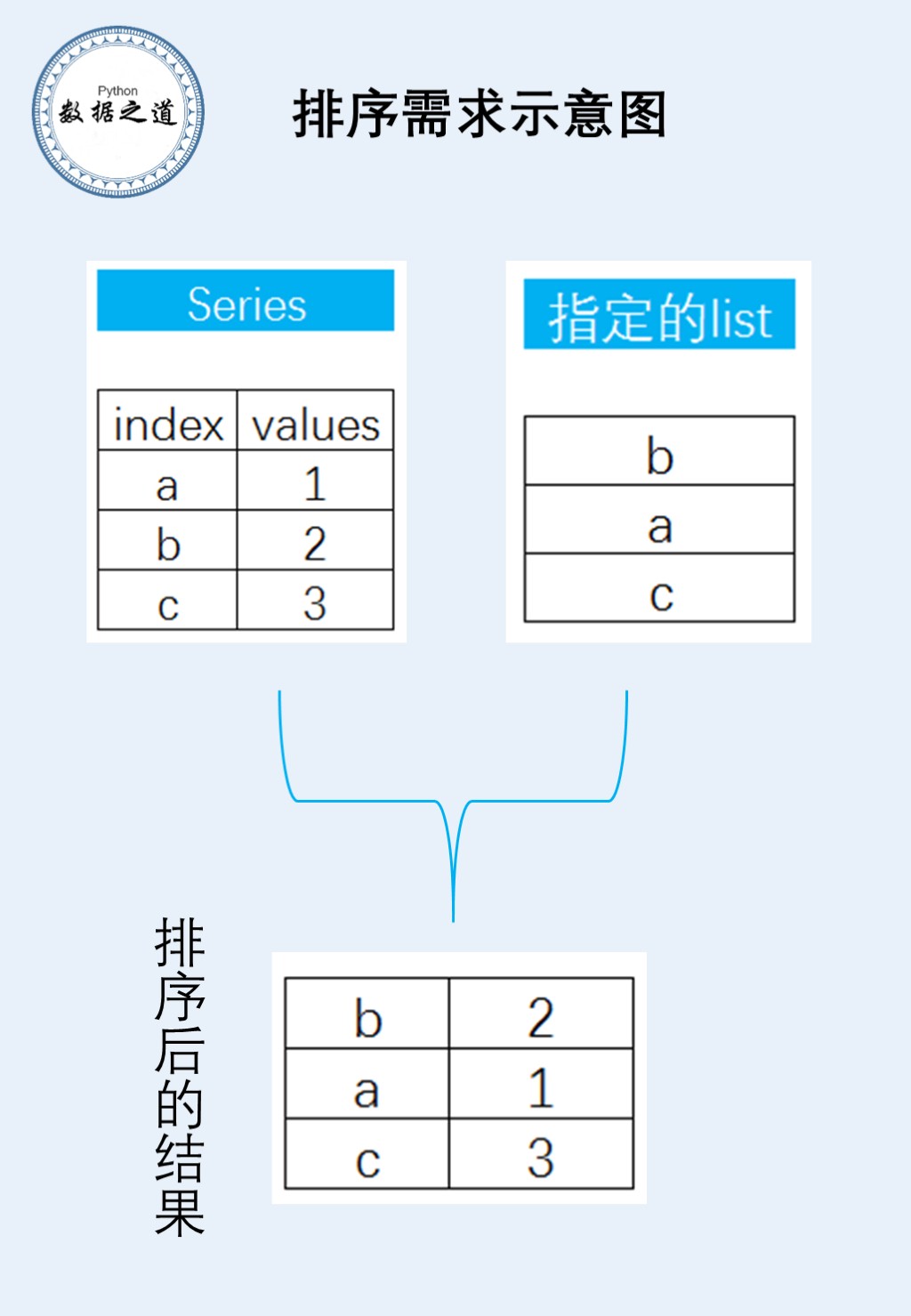
我思考了一下,这个问题解决的核心是引入pandas的数据类型“category”,从而进行排序。
在具体的分析过程中,先将pandas的Series转换成为DataFrame,然后设置数据类型,再进行排序。思路用流程图表示如下:
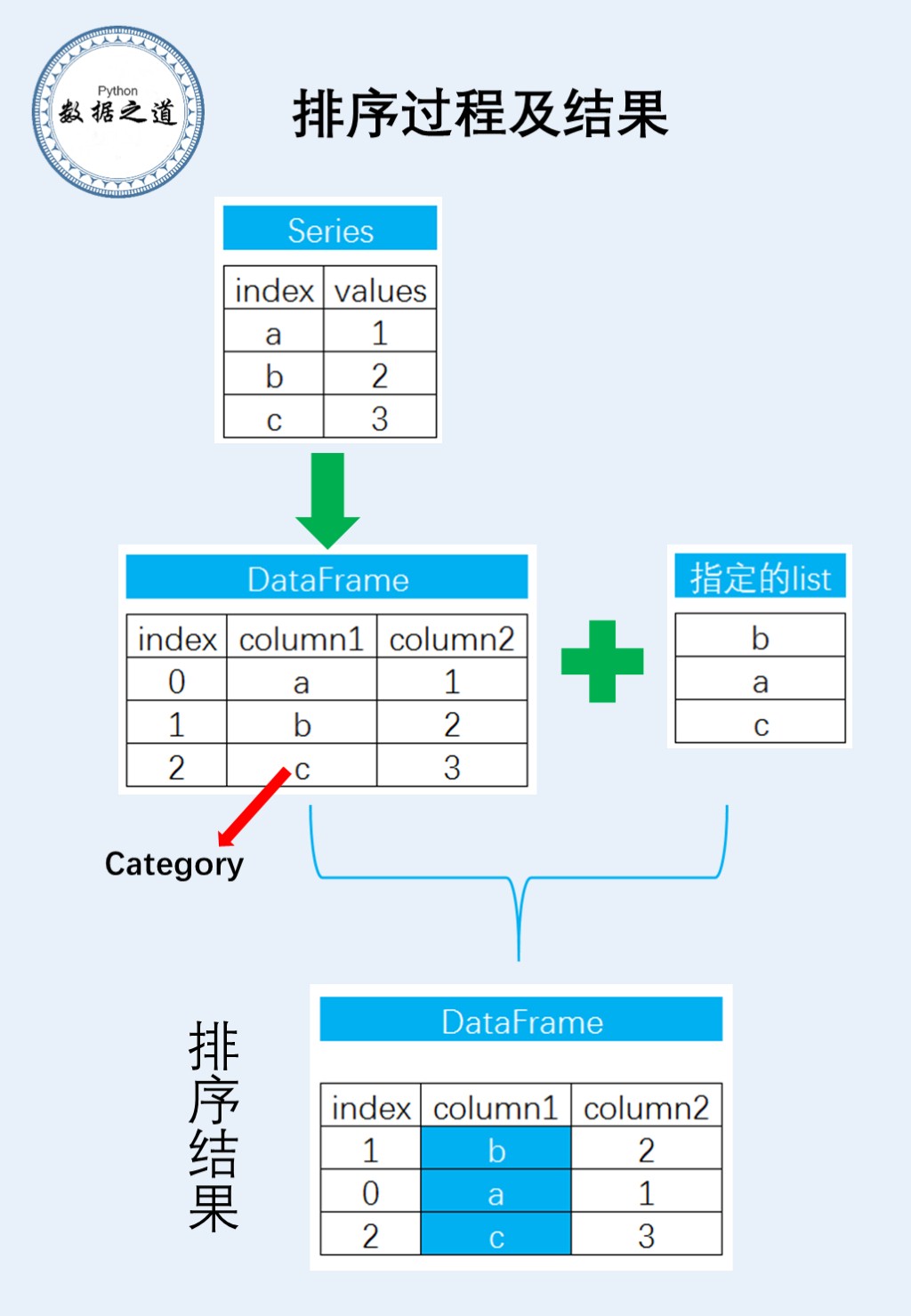
分析过程
- 引入pandas库
import pandas as pd
- 构造Series数据
s = pd.Series({'a':1,'b':2,'c':3})
s
a 1
b 2
c 3
dtype: int64
s.index
Index(['a', 'b', 'c'], dtype='object')
- 指定的list,后续按指定list的元素顺序进行排序
list_custom = ['b', 'a', 'c']
list_custom
['b', 'a', 'c']
- 将Series转换成DataFrame
df = pd.DataFrame(s)
df = df.reset_index()
df.columns = ['words', 'number']
df
| words | number | |
|---|---|---|
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
设置成“category”数据类型
# 设置成“category”数据类型
df['words'] = df['words'].astype('category')
# inplace = True,使 recorder_categories生效
df['words'].cat.reorder_categories(list_custom, inplace=True)
# inplace = True,使 df生效
df.sort_values('words', inplace=True)
df
| words | number | |
|---|---|---|
| 1 | b | 2 |
| 0 | a | 1 |
| 2 | c | 3 |
指定list元素多的情况:
若指定的list所包含元素比Dataframe中需要排序的列的元素多,怎么办?
- reorder_catgories()方法不能继续使用,因为该方法使用时要求新的categories和dataframe中的categories的元素个数和内容必须一致,只是顺序不同。
- 这种情况下,可以使用 set_categories()方法来实现。新的list可以比dataframe中元素多。
list_custom_new = ['d', 'c', 'b','a','e']
dict_new = {'e':1, 'b':2, 'c':3}
df_new = pd.DataFrame(list(dict_new.items()), columns=['words', 'value'])
print(list_custom_new)
df_new.sort_values('words', inplace=True)
df_new
['d', 'c', 'b', 'a', 'e']
| words | value | |
|---|---|---|
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
df_new['words'] = df_new['words'].astype('category')
# inplace = True,使 set_categories生效
df_new['words'].cat.set_categories(list_custom_new, inplace=True)
df_new.sort_values('words', ascending=True)
| words | value | |
|---|---|---|
| 1 | c | 3 |
| 0 | b | 2 |
| 2 | e | 1 |
指定list元素少的情况:
若指定的list所包含元素比Dataframe中需要排序的列的元素少,怎么办?
- 这种情况下,set_categories()方法还是可以使用的,只是没有的元素会以NaN表示
注意下面的list中没有元素“b”
list_custom_new = ['d', 'c','a','e']
dict_new = {'e':1, 'b':2, 'c':3}
df_new = pd.DataFrame(list(dict_new.items()), columns=['words', 'value'])
print(list_custom_new)
df_new.sort_values('words', inplace=True)
df_new
['d', 'c', 'a', 'e']
| words | value | |
|---|---|---|
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
df_new['words'] = df_new['words'].astype('category')
# inplace = True,使 set_categories生效
df_new['words'].cat.set_categories(list_custom_new, inplace=True)
df_new.sort_values('words', ascending=True)
| words | value | |
|---|---|---|
| 0 | NaN | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
总结
根据指定的list所包含元素比Dataframe中需要排序的列的元素的多或少,可以分为三种情况:
- 相等的情况下,可以使用 reorder_categories和 set_categories方法;
- list的元素比较多的情况下, 可以使用set_categories方法;
- list的元素比较少的情况下, 也可以使用set_categories方法,但list中没有的元素会在DataFrame中以NaN表示。
源代码
需要的童鞋可在微信公众号“Python数据之道”(ID:PyDataRoad)后台回复关键字获取视频,关键字如下:
“2017-025”(不含引号)
Python: Pandas的DataFrame如何按指定list排序的更多相关文章
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
- python pandas.Series&&DataFrame&& set_index&reset_index
参考CookBook :http://pandas.pydata.org/pandas-docs/stable/cookbook.html Pandas set_index&reset_ind ...
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的, 导入如下: from panda ...
- 吴裕雄--天生自然python学习笔记:pandas模块DataFrame 数据的修改及排序
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]] ...
- python基础:如何使用python pandas将DataFrame转换为dict
之前在知乎上看到有网友提问,如何将DataFrame转换为dict,专门研究了一下,pandas在0.21.0版本中是提供了这个方法的.下面一起学习一下,通过调用help方法,该方法只需传入一个参数, ...
- python学习笔记—DataFrame和Series的排序
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> ################################### 排序 ################## ...
- python 数据处理学习pandas之DataFrame
请原谅没有一次写完,本文是自己学习过程中的记录,完善pandas的学习知识,对于现有网上资料的缺少和利用python进行数据分析这本书部分知识的过时,只好以记录的形势来写这篇文章.最如果后续工作定下来 ...
- oracle数据据 Python+Pandas 获取Oracle数据库并加入DataFrame
import pandas as pd import sys import imp imp.reload(sys) from sqlalchemy import create_engine impor ...
- 【跟着stackoverflow学Pandas】 - Adding new column to existing DataFrame in Python pandas - Pandas 添加列
最近做一个系列博客,跟着stackoverflow学Pandas. 以 pandas作为关键词,在stackoverflow中进行搜索,随后安照 votes 数目进行排序: https://stack ...
随机推荐
- xmlplus 组件设计系列之四 - 列表
列表组件是极其常用的一类组件,是许多视图组件系统的必须包含的.列表可以做的很简单,只显示简洁的内容.列表也可以做的很复杂,用于展示非常丰富的内容. 组成元素 列表离不开列表项以及包含列表项的容器.下面 ...
- jquery的ajax与spring mvc对接注意事项
昨天一直纠结这么一个问题,应用场景是这样的: 这里登陆是通过jquery的ajax传输数据到后台controller类相应的映射mapping接收.本来是想,在后台验证成功之后返回一个视图modelA ...
- OC继承以及实例变量修饰符
这里基本上跟java一样 所以就简单写几点要注意的: 1)OC与java一样都只支持单继承可以多层继承(java单继承多实现) 2) OC中的实例变量修饰符前要加 @ 例如 @private 例如下面 ...
- innobackup全备与恢复
前提:xtrabackup.mysql安装完成,建立测试库reading.测试表test,并插入三条数据. 1.全备: innobackupex --user=root --password ...
- 智能指针剖析(下)boost::shared_ptr&其他
1. boost::shared_ptr 前面我已经讲解了两个比较简单的智能指针,它们都有各自的优缺点.由于 boost::scoped_ptr 独享所有权,当我们真真需要复制智能指针时,需求便满足不 ...
- [刷题]算法竞赛入门经典(第2版) 5-14/UVa1598 - Exchange
题意:模拟买卖,当出售价bid等于或低于出售价ask,则交易. 代码:(Accepted,0.330s) //UVa1598 - Exchange //Accepted 0.330s //#defin ...
- SpringData系列四 @Query注解及@Modifying注解
@Query注解查询适用于所查询的数据无法通过关键字查询得到结果的查询.这种查询可以摆脱像关键字查询那样的约束,将查询直接在相应的接口方法中声明,结构更为清晰,这是Spring Data的特有实现. ...
- 通过vmware 启动cloudera-quickstart-vm-5.10.0-0-vmware.zip镜像无法启动。
解压cloudera-quickstart-vm-5.10.0-0-vmware.zip中找到cloudera-quickstart-vm-5.10.0-0-vmware.vmx文件打开注释点#msg ...
- Natas Wargame Level 16 Writeup(Content-based Blind SQL Injection)
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAqwAAADhCAYAAAANm+erAAAABHNCSVQICAgIfAhkiAAAIABJREFUeF
- 实时语音视频技术webrtc的编译总结
webrtc编译教程 一.安装depot_tools工具 首先你的电脑上安装了git 1) 下载depot_tools cd到下载的目录下 git clone https://chromium. ...