mutex和CRITICAL_SECTION,互斥和临界区
本文不没有任何知识可讲,只是帖上自己测试的结果。
想看底层原理的可以直接关闭。
不过对于急着要选方案的人,倒提供一些帮助。
先说一些无关紧要的废话:
====================================================================================================================================================
先说说为什么会有这篇文章。
我在做练习的时候,参考一些老代码,发现了CRITICAL_SECTION这个类型。以前没有用过。查了一下,三个要点:windows使用;互斥效果;比mutex快。
后来又翻了些网页查看两者的一些简介。很统一的结果,CRITICAL_SECTION比mutex快,而且Linux上没有类似的接口(注:可能是我搜索的方式不对,加上本人对Linux研究不多,所以没有找到)。
对于刚打算使用c++11制作全新技术接口版本的服务器的我来说,很遗憾啊,Linux没有。难道我只能用这种慢速的锁?而我又不想写太多差异化的代码,能用标准库最好,等到真的某个模块成为新能瓶颈的时候再针对某个模块在Linux上做差异处理。
所以我还是想使用标准库来完成这个事情。
于是,我搜索“CRITICAL_SECTION c++11”。
两篇很重要的文章出现在了搜索结果里,是因为这两篇文章而产生了本文。
https://stackoverflow.com/questions/23519630/are-there-c11-critical-sections
https://stackoverflow.com/questions/9997473/stdmutex-performance-compared-to-win32-critical-section
====================================================================================================================================================
第一篇文章的精要在:
虽然Linux上没有临界区这样的接口,而mutex又是需要陷入内核去处理的东西。但是呢这些都是规定,仅仅是为了兼容POSIX协议做的。而mutex慢主要是POSIX需要跨进程。但是呢,在不同的系统和版本上面,就可以有私人定制,就如同windows上的CRITICAL_SECTION。一旦我不再兼容POSIX,就可以做一些自己的花活。而同时在兼容POSIX的平台上,继续遵循POSIX的规定。
以上精要,你可以在第一个连接的第一个回复里面的追问里面得到。
这给我提供了一个很重要的信息:c++11是没有临界区这样的用法。而且mutex的跨进程也不是所有的系统和版本都需要的,仅仅是某些版本需要。在不需要的版本上std::mutex可能是有特殊的用法和优化可以媲美临界区。
总之,mutex和mutex不一样
有了这个想法,我决定自己写代码试试。
然而不幸的是,当我准备写的时候,我想,这种问题应该也会有其他人这样想吧,说不定能搜到呢?
在搜索结果里,我就看到了第二篇。
第二篇文章的精要在:
std::mutex慢。CRITICAL_SECTION更快。但是如果采用合理的方式来分割任务,两者可以达到几乎相同的效果。
第二篇文章是含有两个人的测试代码的。第一个人的测试代码是直接比对两种用法的时间差异。但是很遗憾,他使用的是vs2012。这个版本对c++11的支持并不算完美。第二个人的测试代码是将任务做了分割,分给不同的cpu,又延长了执行间隔,减少访问冲突。使用的是vs2013,这一传说中对c++11支持很完善的版本
看到这里,我有些冷,就不太想写测试代码了。原因是开发工具,人家已经更新到了一个合理的版本,其次在结构上进行了划分,而划分之后才打个平手。
似乎所有的结果都是唯一的。
但是!中间好几年了。万一有变化呢?即使没有,自己测试一下总归实在一些。所以还是自己做了个测试。结果很意外。
先说思路:
在同一进程中,开启4个线程,2个用std::mutext去抢,两个用CRITICAL_SECTION去抢;
两组方式各自使用自己组的变量;
只记录计算次数,不做结果正确判断;
以下是测试代码
#include <iostream>
#include <mutex>
#include <thread>
#include <Windows.h>
#include <chrono> using namespace std; mutex g_Mutex_Lock, g_Mutex_finish;
CRITICAL_SECTION g_CS_Lock, g_CS_finish;
uint64_t g_Mutext_Num = -;
uint64_t g_CS_Num = -;
const int32_t g_Count = ;
once_flag g_Mutex_flag, g_CS_flag;
chrono::time_point<chrono::system_clock> g_Mutex_StartTime, g_CS_StartTime;
int32_t g_Mutex_Complete = ;
int32_t g_CS_Complete = ; uint64_t Calculate(uint64_t num, int index)
{
if (index % )
{
return (num / 0x5555) * 0xaaaa;
}
else
{
return (num / 0x6666) * 0x9999;
}
} void mutexTimeStart()
{
g_Mutex_StartTime = chrono::system_clock::now();
} void mutexCalculate()
{
call_once(g_Mutex_flag, mutexTimeStart); for (int i = ; i < g_Count; ++i)
{
g_Mutex_Lock.lock();
g_Mutext_Num = Calculate(g_Mutext_Num, i);
g_Mutex_Lock.unlock();
}
g_Mutex_finish.lock();
++g_Mutex_Complete;
if ( == g_Mutex_Complete)
{
chrono::duration<double> elapsed_seconds = chrono::system_clock::now() - g_Mutex_StartTime;
printf("mutex finished use: %f\n", elapsed_seconds.count());
}
g_Mutex_finish.unlock();
} void csTimeStart()
{
g_CS_StartTime = chrono::system_clock::now();
} void csCalculate()
{
call_once(g_CS_flag, csTimeStart);
for (int i = ; i < g_Count; ++i)
{
EnterCriticalSection(&g_CS_Lock);
g_CS_Num = Calculate(g_CS_Num, i);
LeaveCriticalSection(&g_CS_Lock);
}
EnterCriticalSection(&g_CS_finish);
++g_CS_Complete;
if ( == g_CS_Complete)
{
chrono::duration<double> elapsed_seconds = chrono::system_clock::now() - g_CS_StartTime;
printf("cs finished use: %f\n", elapsed_seconds.count());
}
LeaveCriticalSection(&g_CS_finish);
} void main()
{
InitializeCriticalSection(&g_CS_Lock);
InitializeCriticalSection(&g_CS_finish); thread t3(csCalculate);
t3.detach();
thread t4(csCalculate);
t4.detach(); thread t1(mutexCalculate);
t1.detach();
thread t2(mutexCalculate);
t2.detach(); int tStop;
cin >> tStop;
}
main.cpp
测试环境:win10企业版(已经更新到最新)+vs2015企业版+i7-6700HQ(2.6G×8)
64位release版结果:

图中除最后一个外,都是循环1千万次的结果。最后一个是10亿次的结果。
再上一个64位debug版的1亿次的截图(原谅我没有等带10亿次的结果,你们不知道,我测试1千万的结果是n秒。然后头绕一热直接跳了两级,一运行,发现没出结果,然后一算,就傻了,关掉减个0)。
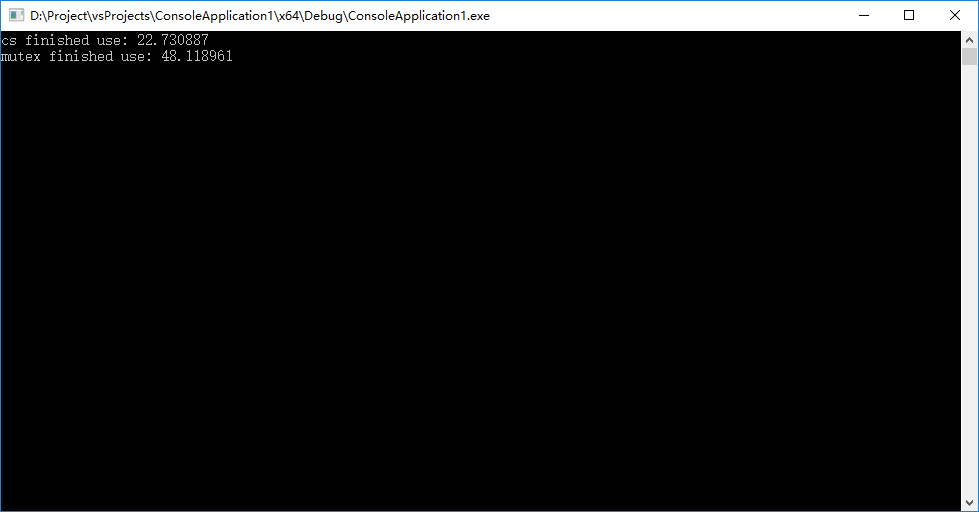
无论前面有多少经历,无论多少推测。结果胜过一切,我可以继续安心的、开心的使用std继续进行我的练习了。
本次测试结果:
1、性能不是瓶颈,不要考虑太多。优化都是在原有的基础上逐步修改改出来的成果,不是动手的时候,脑子就有现成的方案。何况性能并没有走到瓶颈。
2、没有什么比电脑跑出来的结果更靠谱。毕竟电脑才是所有理论知识最终产物的执行者。
3、随时间的推移,技术在改良。使用通用的接口,每次技术更替,你也在享受免费的红利。
最后,如果有朋友发现我的代码中存在影响测试结果的错误,请留言指出。我不想自己错了,还误导别人。
mutex和CRITICAL_SECTION,互斥和临界区的更多相关文章
- pthread mutex 进程间互斥锁实例
共享标志 定义 名称 描述 0 PTHREAD_PROCESS_PRIVATE 进程内互斥锁 仅可当前进程内共享 1 PTHREAD_PROCESS_SHARED 进程间互斥锁 多个进程间共享 第一个 ...
- Mutex 进程间互斥
学习Mutex的心得,不一定对,先记录一下. 同步技术分为两大类,锁定和信号同步. 锁定分为:Lock.Monitor 信号同步分为:AutoResetEvent.ManualResetEvent.S ...
- Linux内核互斥锁--mutex
一.定义: /linux/include/linux/mutex.h 二.作用及访问规则: 互斥锁主要用于实现内核中的互斥访问功能.内核互斥锁是在原子 API 之上实现的,但这对于内核用户是不可见 ...
- [Go] golang互斥锁mutex
1.互斥锁用于在代码上创建一个临界区,保证同一时间只有一个goroutine可以执行这个临界区代码2.Lock()和Unlock()定义临界区 package main import ( " ...
- 十二 windows临界区,其他各种mutex
一.windows临界区 类似于互斥量 == 临界区. 二.多次进入临界区 进入临界区(加锁): 离开临界区(解锁): 同一个线程中windows中相同临界区变量代表的临界区进入(entercirti ...
- 互斥量mutex简介
互斥量又称互斥锁.互斥量是一个可以处于两态之一的变量:解锁和加锁. 简介 编辑 如果不需要信号量的计数能力,有时可以使用信号量的一个简化版本,称为互斥量(mutex).互斥量仅仅适用于管理共享资源或一 ...
- Linux的线程同步对象:互斥量Mutex,读写锁,条件变量
进程是Linux资源分配的对象,Linux会为进程分配虚拟内存(4G)和文件句柄等 资源,是一个静态的概念.线程是CPU调度的对象,是一个动态的概念.一个进程之中至少包含有一个或者多个线程.这 ...
- Go 标准库 —— sync.Mutex 互斥锁
Mutex 是一个互斥锁,可以创建为其他结构体的字段:零值为解锁状态.Mutex 类型的锁和线程无关,可以由不同的线程加锁和解锁. 方法 func (*Mutex) Lock func (m *Mut ...
- C++多线程同步之Mutex(互斥量)
原文链接: http://blog.csdn.net/olansefengye1/article/details/53086141 一.互斥量Mutex同步多线程 1.Win32平台 相关函数和头文件 ...
随机推荐
- MyBatis源码解析【6】SqlSession运行
前言 这个分类比较连续,如果这里看不懂,或者第一次看,请回顾之前的博客 http://www.cnblogs.com/linkstar/category/1027239.html 经过之前的学习我们知 ...
- 在Jekyll博客添加评论系统:gitment篇
最近在Github Pages上使用Jekyll搭建了个人博客( jacobpan3g.github.io/cn ), 当需要添加评论系统时,找了一下国内的几个第三方评论系统,如"多说&qu ...
- (转)log4j(六)——log4j.properties简单配置样例说明
一:测试环境与log4j(一)——为什么要使用log4j?一样,这里不再重述 1 老规矩,先来个栗子,然后再聊聊感受 (1)使用配文件的方式,是不是感觉非常的清爽,如果不在程序中读取配置文件就更加的清 ...
- HTML5 开发APP(MUI的一些特性)
先附mui文档地址:http://dev.dcloud.net.cn/mui/ui/ .mui的UI组件比较简单而且在文档中很好找就不过多说了. 1 在app开发中,使用HTML5+的api,必须m ...
- Android 内存检查
Android 内存检查 本文简单介绍了如何使用 DDMS 和 MAT 工具来对 android 进行内存检查,了解 android 内存的具体占用情况. 步骤1. 使用 DDMS 观察内存的使用情况 ...
- CentOS安装配置MySql数据库
CentOS版本7.2,MySql版本5.7 1.下载MySql安装源 wget https://dev.mysql.com/get/mysql57-community-release-el7 ...
- ORACLE - 管理重做日志文件
ORACLE重做日志文件用于在数据库崩溃等情况下用于恢复数据,默认情况下为三个文件redo01.log/redo02.log/redo03.log,文件组循环使用,在录入与更新操作比较多的应用中,日志 ...
- Redux源码分析之combineReducers
Redux源码分析之基本概念 Redux源码分析之createStore Redux源码分析之bindActionCreators Redux源码分析之combineReducers Redux源码分 ...
- java_final修饰符
1.修饰变量时,表示该变量一旦获得初始值就不可改变 final修饰的成员变量必须由程序员显示地指定初始值,系统不会进行隐式初始化 类变量:必须在初始化块中指定初始值或声明该类变量时指定初始值 实例变量 ...
- HDU 6043 KazaQ's Socks (规律)
Description KazaQ wears socks everyday. At the beginning, he has nn pairs of socks numbered from 11 ...