python版mapreduce题目实现寻找共同好友
看到一篇不知道是好好玩还是好玩玩童鞋的博客,发现一道好玩的mapreduce题目,地址http://www.cnblogs.com/songhaowan/p/7239578.html
如图
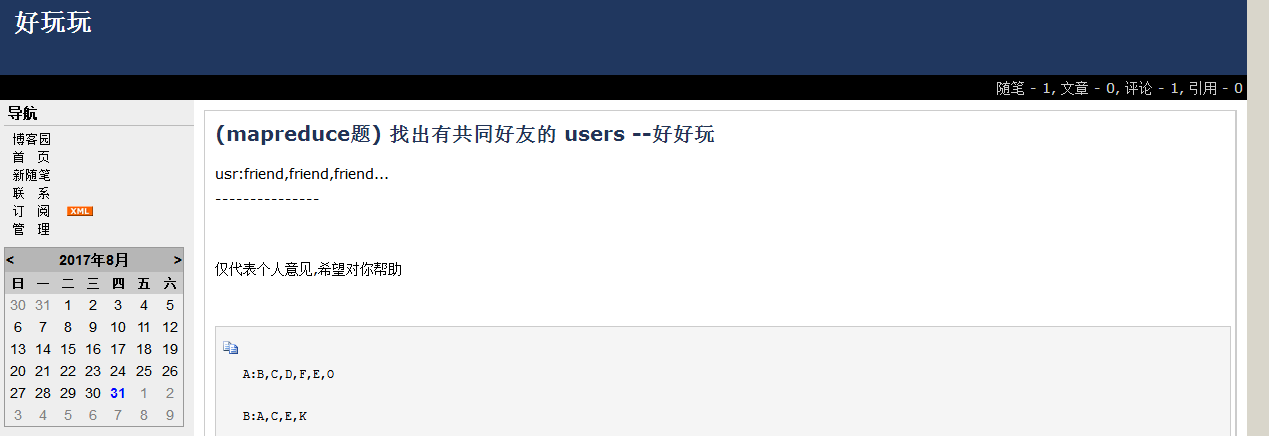
由于自己太笨,看到一大堆java代码就头晕、心慌,所以用python把这个题目研究了一下。
题目:寻找共同好友。比如A的好友中有C,B的好友中有C,那么C就是AB的共同好友。
A:B,C,D,F,E,O B:A,C,E,K C:F,A,D,I D:A,E,F,L E:B,C,D,M,L F:A,B,C,D,E,O,M G:A,C,D,E,F H:A,C,D,E,O I:A,O J:B,O K:A,C,D L:D,E,F M:E,F,G O:A,H,I,J
m.py
#-*-encoding:utf-8-*-
#!/home/hadoop/anaconda2/bin/python
import sys
result = {}
for line in sys.stdin:
line = line.strip()
if len(line)==0:
continue
key,vals = line.split(':')
val = vals.split(',')
result[key] = val
if len(result)==1:
continue
else:
for i in result[key]:
for j in result:
if i in result[j]:
if j<key:
print j+key,i
elif j>key:
print key+j,i
r.py
#-*-encoding:utf-8-*-
import sys
result = {}
for line in sys.stdin:
line = line.strip()
k,v = line.split(' ')
if k in result:
result[k].append(v)
else:
result[k] = [v]
for key,val in result.items():
print key,val
执行的命令
hadoop jar /home/hadoop/hadoop-2.7.2/hadoop-streaming-2.7.2.jar \
-files /home/hadoop/test/m.py,/home/hadoop/test/r.py \
-input GTHY -output GTHYout \
-mapper 'python m.py' -reducer 'python r.py'
执行情况
packageJobJar: [/tmp/hadoop-unjar2310332345933071298/] [] /tmp/streamjob8006362102585628853.jar tmpDir=null
17/08/31 14:47:59 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.228.200:18040
17/08/31 14:48:00 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.228.200:18040
17/08/31 14:48:00 INFO mapred.FileInputFormat: Total input paths to process : 1
17/08/31 14:48:00 INFO mapreduce.JobSubmitter: number of splits:2
17/08/31 14:48:01 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1504148710826_0003
17/08/31 14:48:01 INFO impl.YarnClientImpl: Submitted application application_1504148710826_0003
17/08/31 14:48:01 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1504148710826_0003/
17/08/31 14:48:01 INFO mapreduce.Job: Running job: job_1504148710826_0003
17/08/31 14:48:08 INFO mapreduce.Job: Job job_1504148710826_0003 running in uber mode : false
17/08/31 14:48:08 INFO mapreduce.Job: map 0% reduce 0%
17/08/31 14:48:16 INFO mapreduce.Job: map 100% reduce 0%
17/08/31 14:48:21 INFO mapreduce.Job: map 100% reduce 100%
17/08/31 14:48:21 INFO mapreduce.Job: Job job_1504148710826_0003 completed successfully
17/08/31 14:48:21 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=558
FILE: Number of bytes written=362357
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=462
HDFS: Number of bytes written=510
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=11376
Total time spent by all reduces in occupied slots (ms)=2888
Total time spent by all map tasks (ms)=11376
Total time spent by all reduce tasks (ms)=2888
Total vcore-milliseconds taken by all map tasks=11376
Total vcore-milliseconds taken by all reduce tasks=2888
Total megabyte-milliseconds taken by all map tasks=11649024
Total megabyte-milliseconds taken by all reduce tasks=2957312
Map-Reduce Framework
Map input records=27
Map output records=69
Map output bytes=414
Map output materialized bytes=564
Input split bytes=192
Combine input records=0
Combine output records=0
Reduce input groups=69
Reduce shuffle bytes=564
Reduce input records=69
Reduce output records=33
Spilled Records=138
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=421
CPU time spent (ms)=2890
Physical memory (bytes) snapshot=709611520
Virtual memory (bytes) snapshot=5725220864
Total committed heap usage (bytes)=487063552
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=270
File Output Format Counters
Bytes Written=510
17/08/31 14:48:21 INFO streaming.StreamJob: Output directory: GTHYout
最终结果
hadoop@master:~/test$ hadoop fs -text GTHYout/part-00000
BD ['A', 'E']
BE ['C']
BF ['A', 'C', 'E']
BG ['A', 'C', 'E']
BC ['A']
DF ['A', 'E']
DG ['A', 'E', 'F']
DE ['L']
HJ ['O']
HK ['A', 'C', 'D']
HI ['A', 'O']
HO ['A']
HL ['D', 'E']
FG ['A', 'C', 'D', 'E']
LM ['E', 'F']
KO ['A']
AC ['D', 'F']
AB ['C', 'E']
AE ['B', 'C', 'D']
AD ['E', 'F']
AG ['C', 'D', 'E', 'F']
AF ['B', 'C', 'D', 'E', 'O']
EG ['C', 'D']
EF ['B', 'C', 'D', 'M']
CG ['A', 'D', 'F']
CF ['A', 'D']
CE ['D']
CD ['A', 'F']
IK ['A']
IJ ['O']
IO ['A']
HM ['E']
KL ['D']
突然发现代码中居然一句注释都没有。果然自己还是太辣鸡,还没养成好习惯。
由于刚接触大数据不久,对java不熟悉,摸索地很慢。希望python的轻便能助我在大数据的世界探索更多。
有错的地方还请大佬多多指出~
python版mapreduce题目实现寻找共同好友的更多相关文章
- python版 mapreduce 矩阵相乘
参考张老师的mapreduce 矩阵相乘. 转载请注明:来自chybot的学习笔记http://i.cnblogs.com/EditPosts.aspx?postid=4541939 下面是我用pyt ...
- Han Xin and His Troops(扩展中国剩余定理 Python版)
Han Xin and His Troops(扩展中国剩余定理 Python版) 题目来源:2019牛客暑期多校训练营(第十场) D - Han Xin and His Troops 题意: 看标 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 移动端自动化测试Appium 从入门到项目实战Python版☝☝☝
移动端自动化测试Appium 从入门到项目实战Python版 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 说到APP自动化测试,Appium可是说是非常流 ...
- 数据结构:顺序表(python版)
顺序表python版的实现(部分功能未实现) #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __ini ...
- python版恶俗古风自动生成器.py
python版恶俗古风自动生成器.py """ python版恶俗古风自动生成器.py 模仿自: http://www.jianshu.com/p/f893291674c ...
- LAMP一键安装包(Python版)
去年有出一个python整的LAMP自动安装,不过比较傻,直接调用的yum 去安装了XXX...不过这次一样有用shell..我也想如何不调用shell 来弄一个LAMP自动安装部署啥啥的..不过尼玛 ...
- 编码的秘密(python版)
编码(python版) 最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你. 编码的概念 编码就是将信息从一种 ...
- Zabbix 微信报警Python版(带监控项波动图片)
#!/usr/bin/python # -*- coding: UTF- -*- #Function: 微信报警python版(带波动图) #Environment: python import ur ...
随机推荐
- 如何清除img图片下面有一片空白
最近在做项目突然发现用了img后有个空白区,如下图: 真的很影响美观,那么是什么原因造成的呢? 右键查看元素查看上下文的margin和padding也没有找到这个空白的来源. 只好上网看看别人是怎么说 ...
- Qt中使用CEF(Windows下)
最近项目中要在Qt中使用CEF(Chromium Embedded Framework),在这里总结下其中的几个要点. 下载合适的CEF版本 关于CEF的简介我们这里就不做介绍了,下载CEF可以有2种 ...
- JQuery学习笔记——基础选择器
第一篇博客,现在原生安卓需求不大了.招聘的Android工程师都需要附带更多的其他技术.这也是开启我学习前端之路的开端.前端时间看了HTML.CSS等,在界面渲染这一块,就不多记录博客了.现在学习着J ...
- Python面向对象编程(二)
1.继承与派生 上文我们已经说过,Python中一切皆对象.我们从对象中抽取了共同特征和技能,得到了类的概念.类与类之间也有共同特征,我们可以从有共同特征和技能的类中提取共同的技能和特征,叫做父类. ...
- RxSwift 系列(一) -- Observables
为什么使用RxSwift? 我们编写的代码绝大多数都涉及对外部事件的响应.当用户点击操作时,我们需要编写一个@IBAction事件来响应.我们需要观察通知,以检测键盘何时改变位置.当网络请求响应数据时 ...
- SpringMVC配置实例
一.SpringMVC概述 MVCII模式实现的框架技术 Model--业务模型(Biz,Dao...) View--jsp及相关的jquery框架技术(easyui) Contraller--Dis ...
- 移动端JS事件、移动端框架
一.移动端的操作方式和PC端是不同的,移动端主要是用手指操作,所以有特殊的touch事件,touch事件包括如下几个事件: 1.手指放到屏幕上时触发 touchstart 2.手指放在屏幕上滑动式 ...
- webpack打包编译时,不识别src目录以外的js或css
前端的dva项目开发时,遇到个很郁闷的问题,用es6的语法简单的export一个变量出来,在其他js中import使用,结果就报错了. export写法如下: const enUS = { acc ...
- ETL作业调度工具TASKCTL软件安装乱码问题解决
前两天在安装批量作业调度软件TASKCTL4.5时,将安装介质解压出来后执行安装脚本时,一安装就出现下图乱码. 然后就度娘了一下,发现安装遇到乱码的人还挺多的,大多数解答都说TASKCTL软件里面很多 ...
- 【整理】01. Fiddler 杂记
抓手机包步骤: Tools -- Fiddler Options -- Connections (默认)Fiddler listens on port:8888 (勾选)Allow remote co ...