Elasticsearch构建全文搜索系统
前言
Elasticsearch 是一个分布式、可扩展、实时的搜索与数据分析引擎,通过它我们可以构建出一个强大的全文搜索系统,解决诸如文章检索慢,商品检索慢、MySQL的like查询慢这样的问题。
Elasticsearch是基于hadoop创始人道哥的另一杰作Lucene实现的,速度非常快,核心是使用了倒排索引这样的结构。关于倒排索引是什么,可以参考搜索引擎中的倒排索引是什么
接下来,就以这篇倒排索引中的例子,演示一下ElasticSearch的使用
假设我们有海量文章,如下
| 页码 | 内容 |
|---|---|
| 1 | 生命在于运动 |
| 2 | 运动是生命的源泉 |
| 3 | 日复一日地坚持练下去吧,只有活动适量才能保持训练的热情和提高运动的技能.——塞涅卡 |
| 4 | 活动是生活的基础!——歌德 |
| 5 | 人的健全,不但靠饮食,尤靠运动 |
| 6 | 奥林匹克的格言是“更高,更快,更强” |
| 7 | 身体的健康因静止不动而破坏,因运动练习而长期保持.——苏格拉底 |
| 8 | chenqionghe喜欢运动,绳命是如此的精彩,绳命是如此的辉煌 |
我们想像这是千万级别的表,最后需要实现传入关键字,返回相应的文章
例如:搜索运动返回页码1,2,3,5,7,8对应的文章、搜索chenqionghe返回页码为8的文章
一、安装
1.安装es
查看官网地址,直接下载安装就行了,我用的是mac直接下了mac版本的,另外也可以使用dokcer安装
解压后长这样
es依赖java环境,需要指定jdk版本,我们加入一下java相关环境变量
export JAVA_HOME=/Users/chenqionghe/web/elk/elasticsearch-7.6.1/jdk.app/Contents/Home/
export PATH=$JAVA_HOME/bin:$PATH
启动一下看看
./bin/elasticsearch
看到启动报错
uncaught exception in thread [main]
ElasticsearchException[Failure running machine learning native code. This could be due to running on an unsupported OS or distribution, missing OS libraries, or a problem with the temp directory. To bypass this problem by running Elasticsearch without machine learning functionality set [xpack.ml.enabled: false].]
解决办法,修改./config/elasticsearch.yml添加
xpack.ml.enabled: false
再次启动,成功运行,画风如下
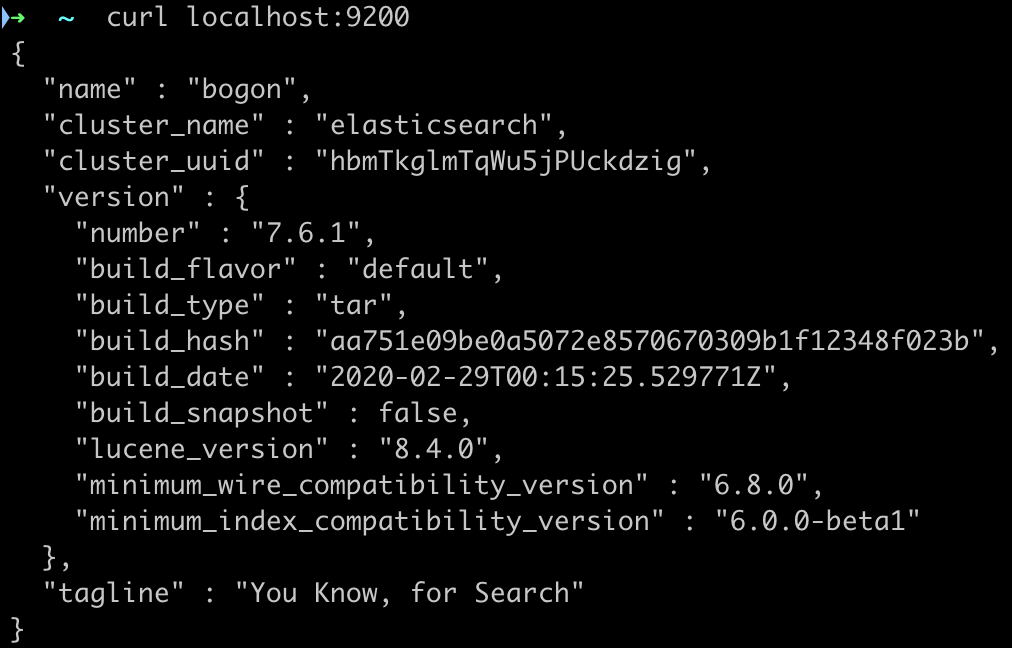
默认启动的是9200端口,我们来测试一下
➜ ~ curl localhost:9200
可以看到,es可以正常运行起来了
2.启动集群
一般es都是以集群的方式存在,接下我们演示一下启动集群。
编辑./config/elasticsearch.yml,指定集群名称,集群名称我指定成了chenqionghe
cluster.name: chenqionghe
指定节点名称
ode.name: chenqionghe-1
设置初始化的节点
cluster.initial_master_nodes: ["chenqionghe-1"]
设置监听的端口,这里不限定ip,指定为0.0.0.0
network.host: 0.0.0.0
端口默认9200
http.port: 9200
添加支持elasticsearch-head界面参数
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: "X-Requested-With, Content-Type, Content-Length, X-User"
再次启动
./bin/elasticsearch
3.安装管理界面
elasticsearch-head可以很方便的查看es集群状态,查看官网地址:elasticsearch-head
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
打开http://localhost:9100/,如下

4.安装分词插件
插件我们使用的是elasticsearch-analysis-ik,参考地址:elasticsearch-analysis-ik/
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch-analysis-ik-7.6.1.zip
验证一下分插件
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d '{ "analyzer": "ik_smart", "text": "chenqionghe徒手健身" }'
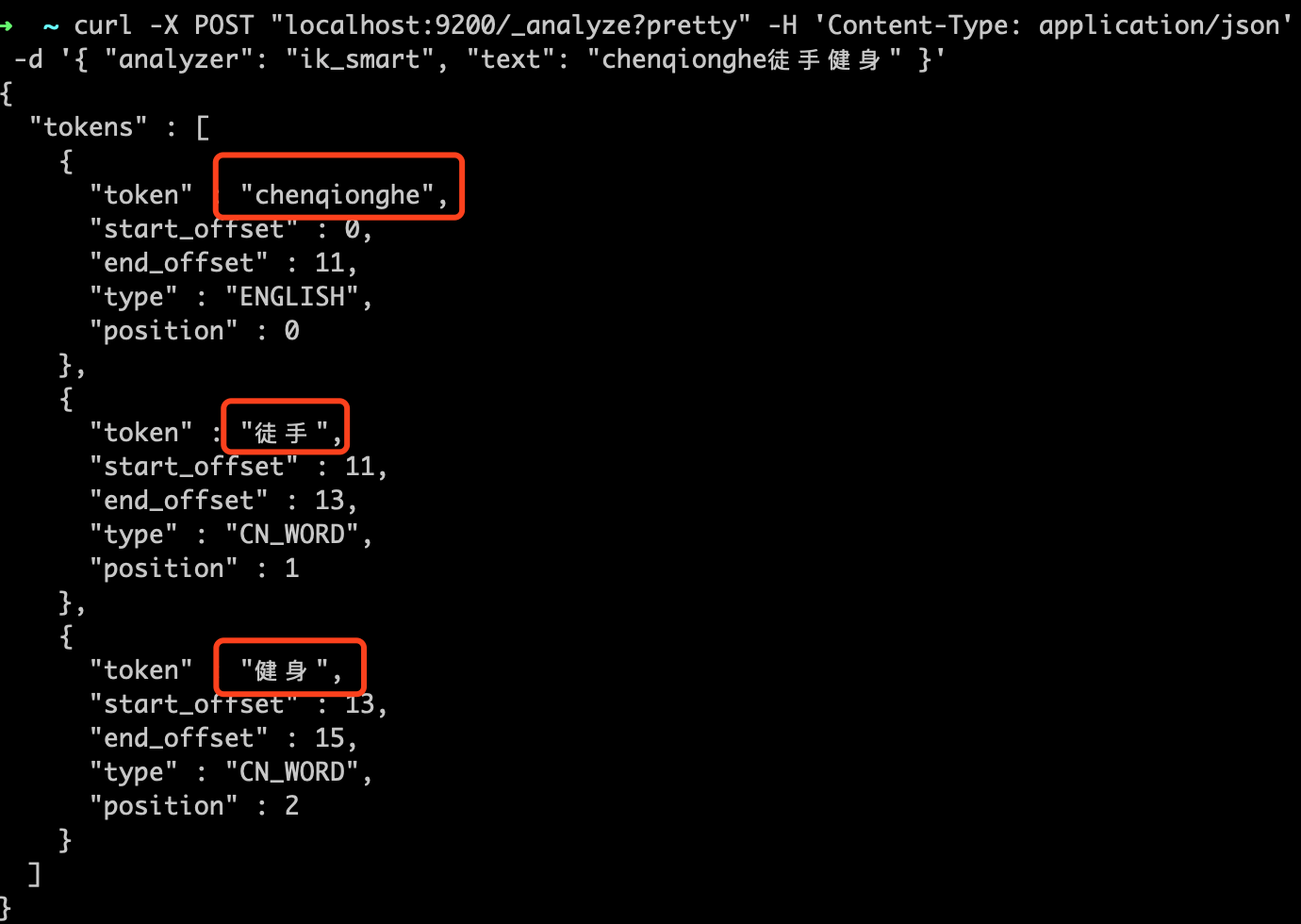
可以看到,已经可以分词了,oh yeah~
二、使用
ES中有index、document、filed、mapping这样的概念,我们以MySQL的结构为参考对照一下,如下
| ElasticSearch | MySQL |
|---|---|
| index | 表 |
| document | 行 |
| field | 列 |
| mapping | 表结构 |
Elasticsearch主要还是使用API,具体使用请参考:Document APIs
1.创建索引
这里index我取名叫book
➜ ~ curl -X PUT "localhost:9200/book" -H 'Content-Type: application/json' -d '{
"mappings": {
"properties": {
"page": {
"type": "long"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}'
{"acknowledged":true,"shards_acknowledged":true,"index":"book"}
创建成功,但是查看head界面,但是这个黄色不怎么优雅呀,原因是虽然启用了集群,但是还是单节点运行的,群集无法放置副本。
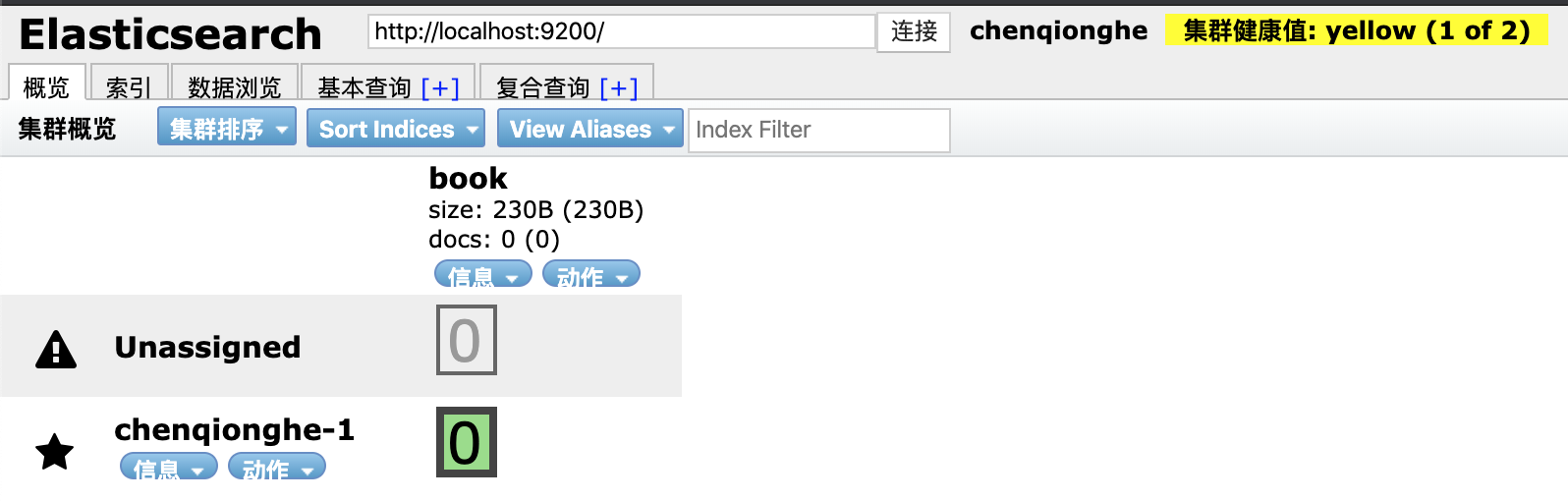
集群的健康状况为 yellow 则表示全部主分片(number_of_shards)都正常运行,但是副本分片没有全部处在正常状态,单节点无论有多少个副本分片(number_of_replicas)都是 unassigned ,它们都没有被分配到任何节点。
在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。
我们需要把这个副本设置为0,因为索引一旦建立,分片数量不能变,我们需要删除再重新建立一下索引
curl -XDELETE http://localhost:9200/book
curl -X PUT "localhost:9200/book" -H 'Content-Type: application/json' -d '{
"settings":{
"number_of_shards": "1",
"number_of_replicas": "0"
},
"mappings": {
"properties": {
"page": {
"type": "long"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}'
再次查看,健康了

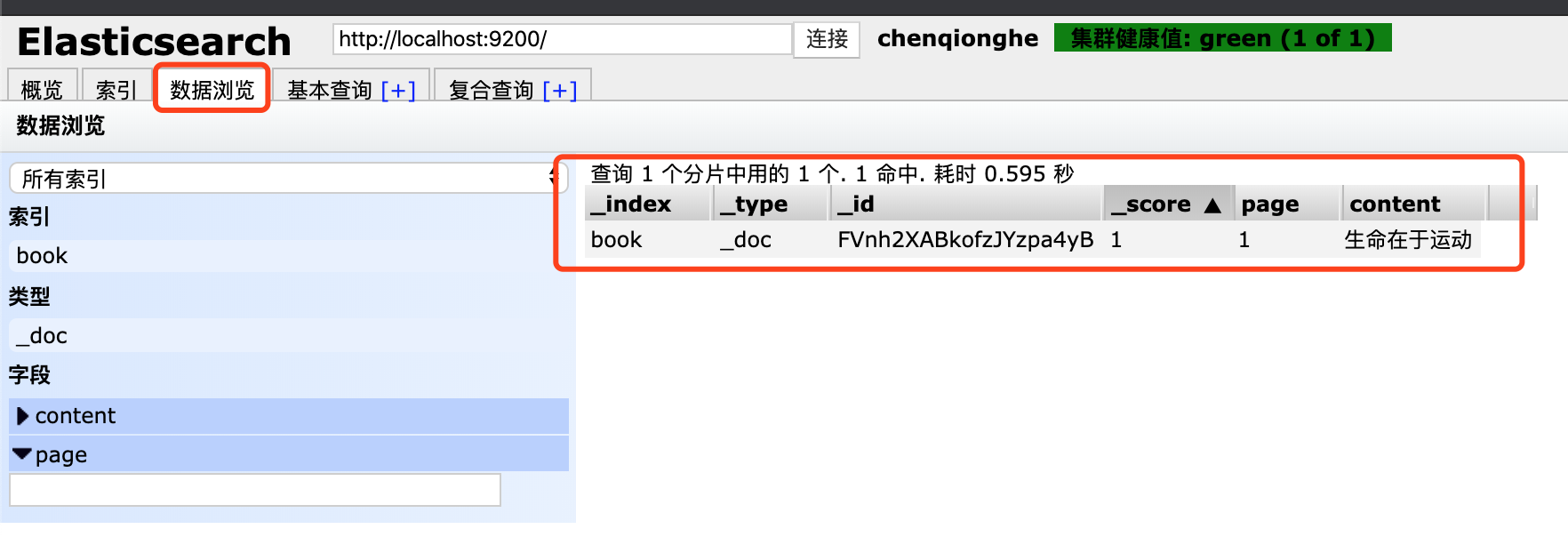
2.插入数据
curl -X POST "localhost:9200/book/_doc/" -H 'Content-Type: application/json' -d '{
"page":1,
"content": "生命在于运动"
}'
我们可以看到已经成功插入一条数据
3.批量插入数据
curl -X POST "localhost:9200/book/_doc/_bulk?pretty" -H 'Content-Type: application/json' -d'
{ "index":{} }
{ "page":2 , "content": "运动是生命的源泉"}
{ "index":{} }
{ "page":3 , "content": "日复一日地坚持练下去吧,只有活动适量才能保持训练的热情和提高运动的技能.——塞涅卡"}
{ "index":{} }
{ "page":4 , "content": "活动是生活的基础!——歌德"}
{ "index":{} }
{ "page":5 , "content": "人的健全,不但靠饮食,尤靠运动"}
{ "index":{} }
{ "page":6 , "content": "奥林匹克的格言是“更高,更快,更强”"}
{ "index":{} }
{ "page":7 , "content": "身体的健康因静止不动而破坏,因运动练习而长期保持.——苏格拉底"}
{ "index":{} }
{ "page":8 , "content": "chenqionghe喜欢运动,绳命是如此的精彩,绳命是如此的辉煌"}
'
可以看到成功批量插入

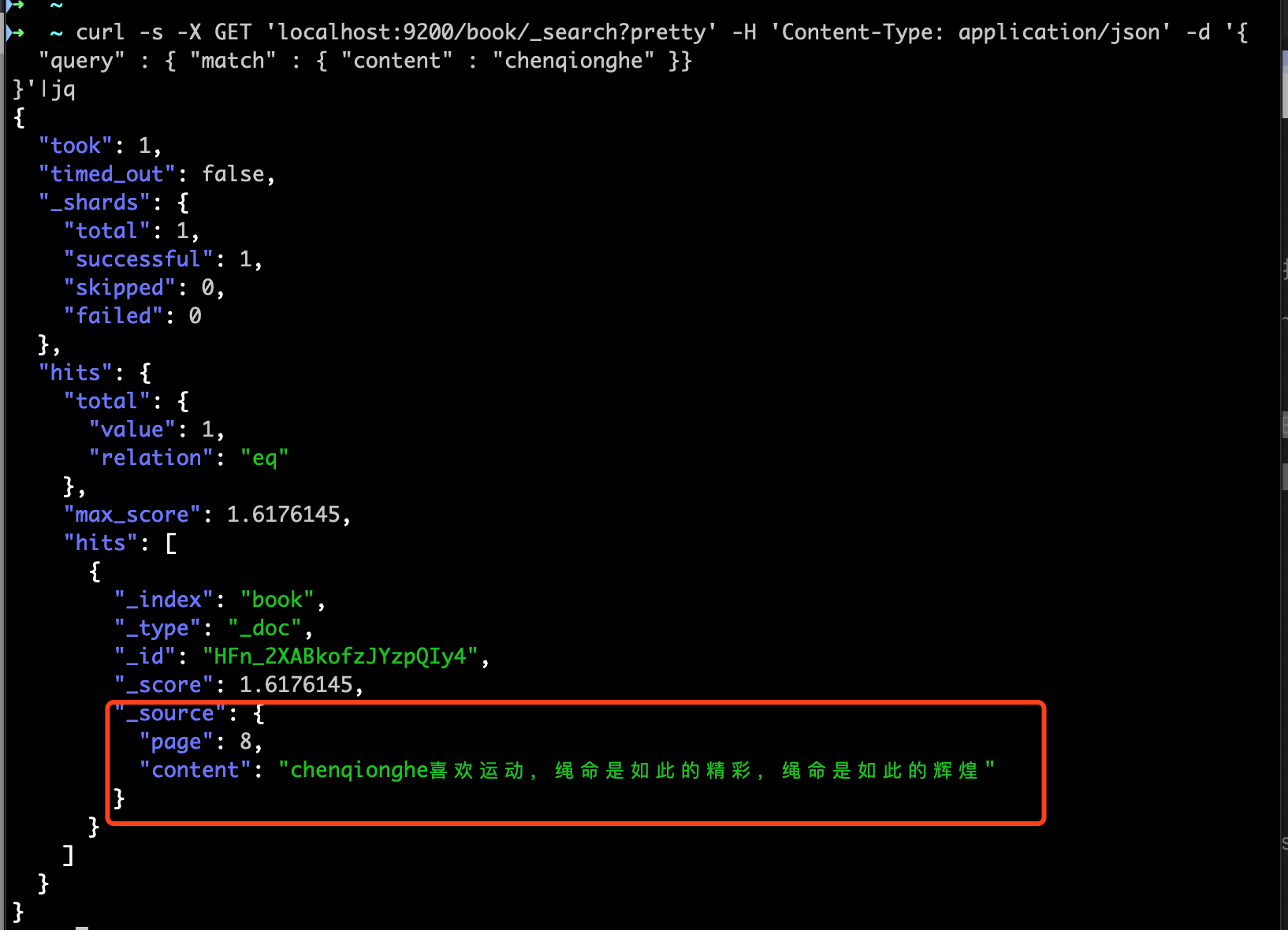
4.查询数据
- 搜索
chenqionghe
curl -s -X GET 'localhost:9200/book/_search?pretty' -H 'Content-Type: application/json' -d '{
"query" : { "match" : { "content" : "chenqionghe" }}
}'|jq
可以看到匹配到了
- 搜索
运动,应该是会返回1,2,3,5,7,8这几条
curl -s -XGET 'localhost:9200/book/_search?pretty' -H 'Content-Type: application/json' -d '{
"query" : { "match" : { "content" : "运动" }}
}'|jq .hits.hits|jq '.[]._source'
可以看到,验证通过

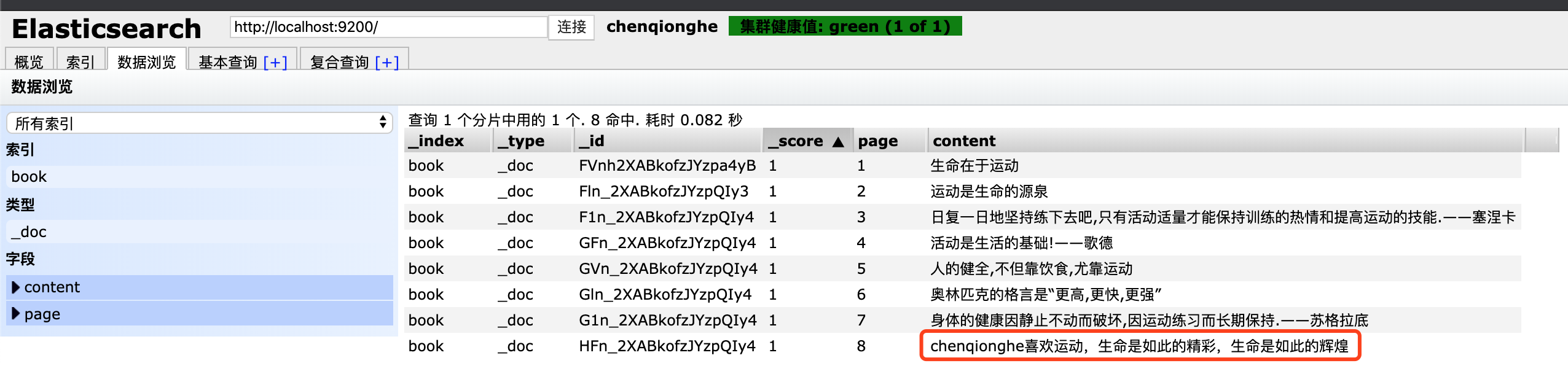
5.修改数据
拉下来,我们将chenqionghe这条记录的绳命改为生命,
curl -X POST "localhost:9200/book/_doc/HFn_2XABkofzJYzpQIy4" -H 'Content-Type: application/json' -d '{
"page":8,
"content": "chenqionghe喜欢运动,生命是如此的精彩,生命是如此的辉煌"
}'
可以看到,更新成功
6.删除数据
- 根据id删除
curl -X DELETE "localhost:9200/book/_doc/GFn_2XABkofzJYzpQIy4"
- 根据条件删除
curl -X POST "localhost:9200/book/_delete_by_query?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"content": "chenqionghe"
}
}
}
'
7.索引关闭和开启
如果关闭了一个索引,就无法通过ES来读取和写入其中的数据,直到道再次打开它
# 关闭
curl -XPOST 'localhost:9200/book/_close'
# 开启
curl -XPOST 'localhost:9200/book/_open'
总结
通过Elasticsearch,我们可以快速构建出一个强大的全文搜索系统,安装简单,通过API使用也简单。
倒排索引为搜索而生,先对需要索引的字段进行分词,再通过词直接匹配出文档,速度非常快,这是优点。但是,相比数据库采用的 B 树索引,它的写入和更新性能都比较差,因此倒排索引也只是适合全文搜索,不适合更新频繁的交易类数据。
总之,安装使用Elasticsearch其实就是这么简单,惊不惊喜,意不意外呀,light weight baby!
更多资料请参考 :Eelasticsearch权威指南
Elasticsearch构建全文搜索系统的更多相关文章
- Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索 作者:白宁超 2019年5月24日17:22:41 导读:件开发最大的麻烦事之一就是环境配置,操作系统设置,各种库和组件的安装.只有它们都正 ...
- 笔记13:Python 和 Elasticsearch 构建简易搜索
Python 和 Elasticsearch 构建简易搜索 1 ES基本介绍 概念介绍 Elasticsearch是一个基于Lucene库的搜索引擎.它提供了一个分布式.支持多租户的全文搜索引擎,它可 ...
- Flask 教程 第十六章:全文搜索
本文翻译自The Flask Mega-Tutorial Part XVI: Full-Text Search 这是Flask Mega-Tutorial系列的第十六部分,我将在其中为Microblo ...
- Nlpir Parser智能语义平台全文搜索
全文索引用于处理大文本集合,利用它人们可以在海量文本中快速获取需要的信息.全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统.一般来说,全文检索需要具备建立索引和提供查询的基本功能 ...
- 在 Laravel 项目中使用 Elasticsearch 做引擎,scout 全文搜索(小白出品, 绝对白话)
项目中需要搜索, 所以从零开始学习大家都在用的搜索神器 elasiticsearch. 刚开始 google 的时候, 搜到好多经验贴和视频(中文的, 英文的), 但是由于是第一次接触, 一点概念都没 ...
- 可以执行全文搜索的原因 Elasticsearch full-text search Kibana RESTful API with JSON over HTTP elasticsearch_action es 模糊查询
https://www.elastic.co/guide/en/elasticsearch/guide/current/getting-started.html Elasticsearch is a ...
- 使用elasticsearch搭建自己的搜索系统
什么是elasticsearch Elasticsearch 是一个开源的高度可扩展的全文搜索和分析引擎,拥有查询近实时的超强性能. 大名鼎鼎的Lucene 搜索引擎被广泛用于搜索领域,但是操作复杂繁 ...
- Nebula 基于 ElasticSearch 的全文搜索引擎的文本搜索
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践. 1 背景 Nebula 2.0 中已经支持了基于外部全文搜索引擎的文本查 ...
- 分布式搜索ElasticSearch构建集群与简单搜索实例应用
分布式搜索ElasticSearch构建集群与简单搜索实例应用 关于ElasticSearch不介绍了,直接说应用. 分布式ElasticSearch集群构建的方法. 1.通过在程序中创建一个嵌入es ...
随机推荐
- Node.js //TODO
目录 技术背景 开发环境 学习过程 参考资料 结束语 技术背景 开发环境 学习过程 参考资料 结束语
- mycat(读写分离、负载均衡、主从切换)
博主本人平和谦逊,热爱学习,读者阅读过程中发现错误的地方,请帮忙指出,感激不尽 1.环境准备 1.1新增两台虚拟机 mycat01:192.168.247.81 mycat02:192.168.247 ...
- 浙江省第十六届大学生ACM程序设计竞赛部分题解
E .Sequence in the Pocket sol:将数组copy一份,然后sort一下,找寻后面最多多少个元素在原数组中保持有序,用总个数减去已经有序的就是我们需要移动的次数. 思维题 #i ...
- linux一些基本操作-防火墙操作
防火墙操作 一.service方式 查看防火墙状态: [root@centos6 ~]# service iptables status iptables:未运行防火墙. 开启防火墙: [root@c ...
- numpy中的ndarray与pandas中的series、dataframe的转换
一个ndarray是一个多维同类数据容器.每一个数组有一个dtype属性,用来描述数组的数据类型. Series是一种一维数组型对象,包含了一个值序列,并且包含了数据标签----索引(index). ...
- keep pace with |sixes and sevens.|Three dozen of |setting out|in despite of|appetite for|brought up|.turn to|leave behind|As can be seen|every
Heavy but not excessive: network capacity seems to have done little more than keep pace with economi ...
- revit安装未完成,某些产品无法安装的解决方法
revit提示安装未完成,某些产品无法安装该怎样解决呢?,一些朋友在win7或者win10系统下安装revit失败提示revit安装未完成,某些产品无法安装,也有时候想重新安装revit的时候会出现本 ...
- 吴裕雄--天生自然python学习笔记:Python3 OS 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录.常用的方法如下表所示: 序号 方法及描述 1 os.access(path, mode) 检验权限模式 2 os.chdir(path) 改变当前工作 ...
- 吴裕雄--天生自然HTML学习笔记:HTML 速查列表
HTML 基本文档 <!DOCTYPE html> <html> <head> <title>文档标题</title> </head& ...
- 用数组实现队列(C++)
#include <iostream> using namespace std; template<typename T, int size = 0> class Queue ...