ORM常用字段及查询
ORM常用字段及参数
我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(如增、删、改、查),而一旦谈到数据的管理操作,就需要用到数据库管理软件,例如mysql、oracle、Microsoft SQL Server等。
为了解决上述问题,django引入了ORM的概念
ORM全称Object Relational Mapping,即对象关系映射
是在pymysq之上又进行了一层封装,对于数据的操作,我们无需再去编写原生sql
取代代之的是基于面向对象的思想去编写类、对象、调用相应的方法等,ORM会将其转换/映射成原生SQL然后交给pymysql执行
创建表
class Employee(models.Model): # 必须是models.Model的子类
id=models.AutoField(primary_key=True)
name=models.CharField(max_length=16)
gender=models.BooleanField(default=1)
birth=models.DateField()
department=models.CharField(max_length=30)
salary=models.DecimalField(max_digits=10,decimal_places=1)
django的orm支持多种数据库,如果想将上述模型转为mysql数据库中的表,需要settings.py中
DATABASES = {
'default': {
# 'ENGINE': 'django.db.backends.mysql',
'ENGINE': 'django.db.backends.mysql',
'NAME': 'day53',
'HOST': '127.0.0.1',
'PORT': 3306,
'USER': 'root',
'PASSWORD': '123123',
'CHARSET': 'utf8'
}
}
在链接mysql数据库前,必须先创建好数据库
修改django的orm默认操作数据库的模块为pymysql
在_init_.py文件下加入这个
import pymysql
pymysql.install_as_MySQLdb()
ORM常用字段
AutoField
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField
一个整数类型,范围在 -2147483648 to 2147483647。(一般不用它来存手机号(位数也不够),直接用字符串存,)
CharField
字符类型,必须提供max_length参数, max_length表示字符长度。
这里需要知道的是Django中的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段
DateField
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
BooleanField()
给字段传布尔值,会对应成0/1
TextField()
文本类型
FileField()
字符串,路径保存在数据库,文件上传到指定目录,只存文件路径
upload_to = '指定文件路径'
给该字段传文件对象 文件会自动保存到upload_to指定的文件夹下,然后将路径保存到数据库
DecimalField(Field)
1、10进制小数 2、参数: max_digits,小数总长度 decimal_places,小数位长度
字段合集(争取记忆)
AutoField(Field)
- int自增列,必须填入参数 primary_key=True
BigAutoField(AutoField)
- bigint自增列,必须填入参数 primary_key=True
注:当model中如果没有自增列,则自动会创建一个列名为id的列
from django.db import models
class UserInfo(models.Model):
# 自动创建一个列名为id的且为自增的整数列
username = models.CharField(max_length=32)
class Group(models.Model):
# 自定义自增列
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
SmallIntegerField(IntegerField):
- 小整数 -32768 ~ 32767
PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正小整数 0 ~ 32767
IntegerField(Field)
- 整数列(有符号的) -2147483648 ~ 2147483647
PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正整数 0 ~ 2147483647
BigIntegerField(IntegerField):
- 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807
BooleanField(Field)
- 布尔值类型
NullBooleanField(Field):
- 可以为空的布尔值
CharField(Field)
- 字符类型
- 必须提供max_length参数, max_length表示字符长度
TextField(Field)
- 文本类型
EmailField(CharField):
- 字符串类型,Django Admin以及ModelForm中提供验证机制
IPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制
GenericIPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
- 参数:
protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both"
URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL
SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号)
CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字
UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证
FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹
FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)
DateTimeField(DateField)
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]
DateField(DateTimeCheckMixin, Field)
- 日期格式 YYYY-MM-DD
TimeField(DateTimeCheckMixin, Field)
- 时间格式 HH:MM[:ss[.uuuuuu]]
DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型
FloatField(Field)
- 浮点型
DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度
BinaryField(Field)
- 二进制类型
字段合集
</code></pre>
</details>
ORM字段与MySQL字段对应关系
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
ORM字段参数
null
用于表示某个字段可以为空。
unique
如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index
如果db_index=True 则代表着为此字段设置索引。
default
为该字段设置默认值。
DateField和DateTimeField
auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
ORM表关系创建
ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
示例
class Book(models.Model):
# id是自动创建的,可以不用写
title = models.CharField(max_length=64)
# price为小数字段 总共8位小数位占2位
price = models.DecimalField(max_digits=8,decimal_places=2)
# 书籍与出版社 是一对多外键关系
publish = models.ForeignKey(to='Publish') # 默认关联字段就是出版社表的主键字段
# publish = models.ForeignKey(to=Publish)
# to后面也可以直接写表的变量名 但是需要保证该变量名在当前位置的上方出现
字段参数
to 设置要关联的表
to_field 设置要关联的表的字段
on_delete 当删除关联表中的数据时,当前表与其关联的行的行为
models.CASCADE 删除关联数据,与之关联也删除
db_constraint 是否在数据库中创建外键约束,默认为True。
OneToOneField
一对一字段
通常一对一字段用来扩展已有字段。(通俗的说就是一个人的所有信息不是放在一张表里面的,简单的信息一张表,隐私的信息另一张表,之间通过一对一外键关联)
示例
class Author(models.Model):
name = models.CharField(max_length=32)
phone = models.BigIntegerField()
# 一对一外键关系建立
author_detail = models.OneToOneField(to='AuthorDetail')
class AuthorDetail(models.Model):
age = models.IntegerField()
addr = models.CharField(max_length=255)
字段参数
to 设置要关联的表
to_field 设置要关联的字段
on_delete 当删除关联表中的数据时,当前表与其关联的行的行为
ManyToManyField
用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系。
示例
class Book(models.Model):
# id是自动创建的,可以不用写
title = models.CharField(max_length=64)
# price为小数字段 总共8位小数位占2位
price = models.DecimalField(max_digits=8,decimal_places=2)
# 书籍与出版社 是一对多外键关系
publish = models.ForeignKey(to='Publish') # 默认关联字段就是出版社表的主键字段
# publish = models.ForeignKey(to=Publish)
# to后面也可以直接写表的变量名 但是需要保证该变量名在当前位置的上方出现
# 图书与作者 是多对多外键关系
authors = models.ManyToManyField(to='Author') # 书籍和作者是多对多关系
# authors字段是一个虚拟字段 不会真正的在表中创建出来
# 只是用来告诉django orm 需要创建书籍和作者的第三张关系表
### 多对多三种创建方式
1 全自动(较为常用)
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
# orm就会自动帮你创建第三张表
class Author(models.Model):
name = models.CharField(max_length=32)
"""
好处:第三张表自动创建
不足之处:第三张表无法扩展额外的字段
2 纯手动(了解)
class Book(models.Model):
title = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
create_time = models.DateField(auto_now_add=True)
"""
好处在于第三表可以扩展额外的字段
不足之处:orm查询的时候会带来不便
"""
3 半自动(推荐)
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',through='Book2Author',through_fields=('book','author'))
class Author(models.Model):
name = models.CharField(max_length=32)
books = models.ManyToManyField(to='Author',through='Book2Author',through_fields=('author','book'))
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
create_time = models.DateField(auto_now_add=True)
"""
好处在于第三步可以扩展任意的额外字段 还可以利用orm 正反向查询
不足之处:无法利用
add
set
remove
clear
虽然无法使用了 但是你还可以自己直接操作第三表
"""
# 单表查询
**在python脚本中调用Django环境**
在进行一般操作时先配置一下参数,使得我们可以直接在Django页面中运行我们的测试脚本
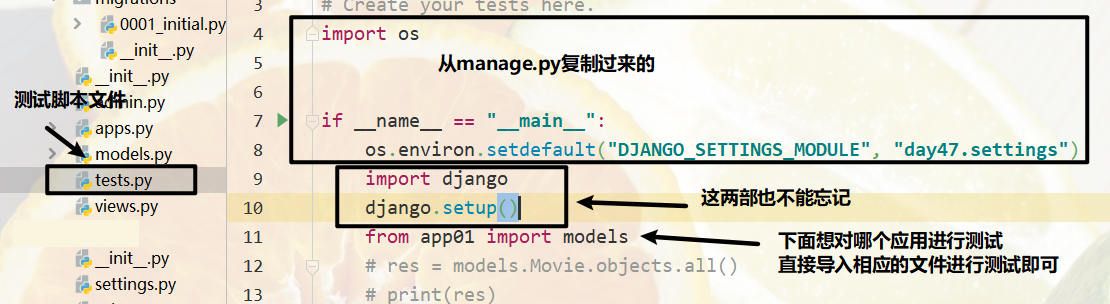
这样就可以直接运行你的test.py文件来运行测试
Django终端daySQL语句
如果你想知道你对数据库进行操作时,Django内部到底是怎么执行它的sql语句时可以加下面的配置来查看
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上
补充:
除了配置外,还可以通过一点.query即可查看查询语句,具体操作如下:

SELECT `app01_book`.`id`, `app01_book`.`title`, `app01_book`.`price`, `app01_book`.`publish_time`, `app01_book`.`publish_id` FROM `app01_book`
queryset和objects对象
queryset是查询集,就是传到服务器上的url里面的内容。Django会对查询返回的结果集QerySet进行缓存,这里是为了提高查询效率。
也就是说,在你创建一个QuerySet对象的时候,Django并不会立即向数据库发出查询命令,只有在你需要用到这个QuerySet的时候才回去数据库查询。
Objects是django实现的mvc框架中的数据层(model)m,django中的模型类都有一个objects对象,它是一个django中定义的QuerySet类型的对象,
它包含了模型对象的实例。简单的说,objects是单个对象,queryset是许多对象。
QuerySet 可以被构造,过滤,切片,做为参数传递,这些行为都不会对数据库进行操作。只要你查询的时候才真正的操作数据库。
循环(Iteration):QuerySet 是可迭代的,在你遍历对象时就会执行数据库操作
for book_obj in Book.objects.all():
print(book_obj.title)
必知必会的16条
1 create()
返回值就是当前被创建数据的对象本身
res = models.Movie.objects.all()
from datetime import date # 日期也可以手动给(2020-01-08)
ctime = date.today()
models.Movie.objects.create(title='双子杀手', price=99, publish_time=ctime)
2 all()
res = models.Movie.objects.all()
# <Movie: 双子杀手>]>
3 filter()
直接获取对象本身,当查询条件不存在的时候直接报错
res = models.Movie.objects.filter(pk=1)
# <QuerySet [<Movie: 双子杀手>]>
4 get()
res = models.Movie.objects.get(pk=1)
# 泰囧2 直接获取对象本身,不推荐使用,当查询条件不存在的时候直接报错
5 values()
获取指定字段对的数据
res = models.Movie.objects.values('title', 'price')
# <QuerySet [{'title': '泰囧2', 'price': Decimal('99.00')}, {'title': '双子杀手', 'price': Decimal('99.00')}]>
6 values_list()
获取指定字段对的数据,无标题版的
res = models.Movie.objects.values_list('title','price')
# <QuerySet [('泰囧2', Decimal('99.00')), ('双子杀手', Decimal('99.00'))]>
7 first()
取第一个元素对象
res = models.Movie.objects.filter().first()
# 泰囧2
8 last()
取最后一个元素对象
res = models.Movie.objects.last()
# 双子杀手
9 update()
更新数据
res = models.Movie.objects.filter(pk=1).update(title='当怪物来敲门', price=22)
# 1 返回值是受影响的行数
10 delete()
删除数据
res = models.Movie.objects.filter(pk=1).delete()
# (1, {'app01.Movie': 1}) 受影响的表及行数
11 count()
统计数据条数
res = models.Movie.objects.count()
12 order_by()
按照指定字段排序
res = models.Movie.objects.order_by('price') # 默认是升序
res = models.Movie.objects.order_by('-price') # 减号就是降序
13 exclude()
排除什么什么之外
res = models.Movie.objects.exclude(pk=1)
14 exists()
返回的是布尔值 判断前面的对象是否有数据 了解即可
res = models.Movie.objects.filter(pk=1000).exists()
15 reverse()
反转
res = models.Movie.objects.order_by('price').reverse()
16 distinct()
去重:去重的前提 必须是由完全一样的数据的才可以
res = models.Movie.objects.values('title','price').distinct()
双下划线查询
语法:字段名__方法名
使用:一般作为filter()的过滤条件
下表中示例语句,省略models.Books.objects.
方法
说明
示例
__gt
大于
filter(price__gt=500
__lt
小于
filter(price__lt=400)
__gte
大于等于
filter(price__gte=500)
__lte
小于等于
filter(price__lte=500)
__in
在...中
filter(price__in=[222,444,500])
__range
在某区间内,参数为[],包含两端
filter(price__range=(200,800))
__year
是某年
filter(publish_date__year='2019')
__month
是某月
filter(publish_date__month='1')
模糊查询
语法:字段名__方法名
使用:一般作为filter()参数
以下示例,省略models.Books.objects.
方法
说明
示例
__startswith
以某字符串开头
filter(title__startswith='三')
__endswith
以某字符串结束
filter(title__endswith='1')
__contains
包含某字符串
filter(title__contains='双')
__icontains
包含某字符串,但忽略大小写
filter(title__icontains='p')
多表查询
外键字段增删改查
models代码
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
publish_time = models.DateField(auto_now_add=True) # 该字段新增数据自动添加 无需考虑
# 出版社 一对多 外键字段建在多的一方
publish = models.ForeignKey(to='Publish')
# 作者 多对多 外键字段建在任意一方均可 推荐你建在查询频率较高的表
authors = models.ManyToManyField(to='Author')
# 库存数
# kucun = models.BigIntegerField(default=1000)
# # 卖出数
# maichu = models.BigIntegerField(default=1000)
def __str__(self):
return self.title
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 作者详情 一对一 外键字段建在任意一方均可 推荐你建在查询频率较高的表
author_detail = models.OneToOneField(to='AuthorDetail')
class AuthorDetail(models.Model):
phone = models.BigIntegerField()
addr = models.CharField(max_length=32)
一对多
增
一对多
# 1 直接写实际的表字段 publish_id
models.Book.objects.create(title='蜡笔小新',price=88,publish_id=2)
#2 传虚拟字段
# 先查询关联的数据对象
publish_obj = models.Publish.objects.get(pk=1)
# 再将对象作为参数传给外键(定义中写到的外键,是一个虚拟字段)
models.Book.objects.create(title='蜡笔小新1',price=88,publish=publish_obj)
改
#1 把Book表里pk为5的publish_id改为1
models.Book.objects.filter(pk=5).update(publish_id=1)
# 2 传虚拟字段
publist_obj = models.Publish.objects.get(pk=1)
models.Book.objects.filter(pk=5).update(publish=publist_obj)
删
models.Book.objects.filter(pk=6).delete()
外键字段在1.X版本中默认就是级联更新级联删除的
2.X版本中,则需要你自己手动指定
多对多
增add()
add专门给第三张关系表添加数据
括号内即可以传数字也可以传对象 并且都支持传多个
# 给书籍绑定作者关系
# 书籍和作者的关系是由第三张表组成,也就意味着你需要操作第三张表
# 书籍对象点虚拟字段authors就类似于已经跨到书籍和作者的第三张关系表中
# 1 传数字
book_obj = models.Book.objects.filter(pk=5).first()
# print(book_obj.authors)
book_obj.authors.add(4) # 给书籍绑定一个主键为4的作者
book_obj.authors.add(3,4)
# 2 传对象
book_obj = models.Book.objects.filter(pk=5).first()
author_obj = models.Author.objects.get(pk=3)
book_obj.authors.add(author_obj)
删除remove()
移除书籍与作者的绑定关系
remove专门给第三张关系表移除数据
括号内即可以传数字也可以传对象 并且都支持传多个
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.remove(3,4)
# 传对象
book_obj = models.Book.objects.filter(pk=5).first()
author_obj = models.Author.objects.get(pk=3)
book_obj.authors.remove(author_obj)
修改set()
set 修改书籍与作者的关系
括号内支持传数字和对象 但是需要是可迭代对象
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.set((3,)) #注意,这里需要传可迭代对象,数字加上括号加上逗号即可
# 传对象
book_obj = models.Book.objects.filter(pk=5).first()
author_obj = models.Author.objects.get(pk=4)
book_obj.authors.set((author_obj,))
清空clear()
清空书籍与作者关系,不需要任何参数
book_obj = models.Book.objects.filter(pk=5).first()
book_obj.authors.clear() # 去第三张表中清空书籍为5的所有数据
跨表查询
# 当以Book为基表时,称之为正向查询
Book(基表)-------正向---------->Publish
外键字段是否在当前数据对象中,如果在,查询另外一张关系表,叫正向
# 当以Publish为基表时,称之为反向查询
Book<-------反向----------Publish(基表)
外键字段是否在当前数据对象中,如果不在,查询另外一张关系表,叫反向
口诀
正向查询按外键字段
反向查询按表名小写
使用原生sql进行多表关联查询时无非两种方式:子查询、join连表查询,ORM里同样有两种查询方式(严格依赖正向、反向的概念)
基于对象的跨表查询(子查询)
正向查询 :对象.外键
book_obj = models.Book.objects.filter(pk=5).first() #查询书籍pk为5的出版社名称
print(book_obj.publish) # 对象.外键即可得到关联的对象
book_obj = models.Book.objects.filter(pk=5).first() #查询书籍pk为5的所有作者的姓名
print(book_obj.authors.all())
author_list = book_obj.authors.all()
for author_obj in author_list:
print(author_obj.name)
author_obj = models.Author.objects.filter(pk=3).first() # 查询作者pk为3的电话号码
print(author_obj.author_detail)
print(author_obj.author_detail.phone)
正向查询的时候 当外键字段对应的数据可以有多个的时候需要加.all()
否则点外键字典即可获取到对应的数据对象
基于对象的反向查询,表名是否需要加 _set.all()
一对多和多对多的时候需要加
一对一不需要
基于双下划线跨表查询(链表查询)
反向查询 :对象.关联的表名小写 + _set
查询书籍pk为5的出版社名称
# 正向查询
res = models.Book.objects.filter(pk=5).values('publish__name') # 写外键字段 就意味着你已经在外键字段管理的那张表中
# 反向查询
res = models.Publish.objects.filter(book__pk=5) # 拿出版过pk为1的书籍对应的出版社
# res = models.Publish.objects.filter(bool__pk=1).values('name')
查询书籍pk为5的作者姓名和年龄
#正向查询
res = models.Book.objects.filter(pk=5).values('title', 'authors__name', 'authors__age')
# 反向查询
res = models.Author.objects.filter(book__pk=1) # 拿出出版过书籍pk为1的作者
#res = models.Author.objects.filter(bool_pk=5).values('name', 'age', 'book__title')
查询作者是kai的年龄和手机号
#正向查询
res = models.Author.objects.filter(name='kai').values('age','author_detail__phone')
#反向查询
res = models.AuthorDetail.objects.filter(author__name='kai') # 拿到jason的个人详情
#res=models.AuthorDetail.objects.filter(author__name='kai').values('phone','author__age')
只要表之间有关系,你就可以通过正向的外键字段 或者 反向的表名小写,连续跨表操作
聚合查询(分组查询)
# 需先导入模块
from django.db.models import Max,Min,Avg,Count,Sum
1、关键字:annotate
2、关键语法:QuerSet对象.annotate(聚合函数)
# 1.统计每一本书的作者个数
res = models.Book.objects.annotate(author_num=Count('authors')).values('title','author_num')
# 2.统计出每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price','book__title')
# 3.统计不止一个作者的图书
res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title')
# print(res)
# 4.查询各个作者出的书的总价格
res = models.Author.objects.annotate(price_sum=Sum('book__price')).values('name','price_sum')
# 5.如何按照表中的某一个指定字段分组
res = models.Book.objects.values('price').annotate() 就是以价格分组
F与Q
F() 的用法
F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值>
# 需要导入模块
from django.db.models import F, Q
# 1.查询库存数大于卖出数的书籍
res = models.Book.objects.filter(kucun__gt=F('maichu'))
# 2.将所有书的价格提高100
res = models.Book.objects.update(price=F('price') + 100)
帮你获取到表中某个字段对应的值
Q() 的用法
filter() 等方法中逗号隔开的条件是与的关系
如果你需要执行更复杂的查询(例如OR语句),你可以使用Q对象
查询书的名字是python入门或者价格是1000的书籍
res = models.Book.objects.filter(Q(title='python入门'),Q(price=1000)) # 逗号是and关系
res = models.Book.objects.filter(Q(title='python入门')|Q(price=1000)) # |是or关系
res = models.Book.objects.filter(~Q(title='python入门')|Q(price=1000)) # ~是not关系
Q() 的高级用法
q = Q()
q.connector = 'or' # q对象默认也是and关系 可以通过connector改变or
q.children.append(('title','python入门'))
q.children.append(('price',1000))
res = models.Book.objects.filter(q) #~q取反
print(res)
# 特殊参数choices
1、定义字段时,指定参数choices
2、choices的值为元组套元组(事先定义好,一般在该表类中定义该字段之前定义)
3、每一个元组存放两个元素,形成一种对应关系
4、往数据库中存值时,该字段的值存为元组第一个元素即可
5、通过方式对象.get_字段名_display()获取对应的元组第二个元素值,当没有对应关系时,返回的是它本身
class Userinfo(models.Model):
username = models.CharField(max_length=32)
gender_choices = (
(1,'男'),
(2,'女'),
(3,'其他'),
)
gender = models.IntegerField(choices=gender_choices)
# 该字段还是存数字 并且可以匹配关系之外的数字
record_choices = (('checked', "已签到"),
('vacate', "请假"),
('late', "迟到"),
('noshow', "缺勤"),
('leave_early', "早退"),
)
record = models.CharField("上课纪录", choices=record_choices, default="checked", max_length=64)
user_obj = models.Userinfo.objects.get(pk=1)
print(user_obj.username)
print(user_obj.gender)
# 针对choices参数字段 取值的时候 get_xxx_display()
print(user_obj.get_gender_display())
# 针对没有注释信息的数据 get_xxx_display()获取到的还是数字本身
user_obj = models.Userinfo.objects.get(pk=4)
print(user_obj.gender)
print(user_obj.get_gender_display())
数据库查询优化
减少对数据库的操作,减轻数据库的压力
only与defer
orm惰性查询
orm内所有的sql查询语句,都是惰性操作,即当你需要使用查询结果时,才会真正去执行sql语句访问数据库,否则是不会执行查询的
可使用代码验证:
1、配置settings文件,使得当执行sql语句时,在终端打印sql命令
2、验证
# 只查询,不使用查询结果
models.User.objects.all()
# 将查询结果赋值给变量res
res = models.User.object.all()
# 分别执行,查看终端的打印结果
only与defer
only查询:指定查询某字段是,将全部结果一次性取出来,以后再访问该字段数据时,直接从内存中拿即可,不需要再操作数据库
defer查询:指的是一次性获取指定字段之外的所有字段数据,封装到对象中,以后再访问这些字段数据时,直接从内存中拿即可,不需要再操作数据库
# 同样,可以配置settings,在终端中打印被执行的sql命令
# all()查询
res = models.User.objects.all() # 访问一次数据库,打印一条sql命令,获取所有的User表中的数据到内存
# only查询
res = models.User.objects.only(username) # 访问一次数据库,打印一条sql命令,仅仅获取username的所有数据到内存
for user_obj in res:
print(user_obj.username) # 直接从内存中获取,不访问数据库,不打印sql命令
print(user_obj.gender) # 每执行一次,就访问一次数据库,打印一次sql命令
# defer 查询
res = models.User.objects.defer(usernmae) # 访问一次数据库,打印一条sql命令,获取除了username之外的所有数据到内存
for user_obj in res:
print(user_obj.username) # 每执行一次,访问一次数据库,打印一条sql命令
print(user_obj.gender) # 直接从内存中获取,不访问数据库,不打印sql命令
select_related与prefetch_related
当表中有外键时,使用方法减轻数据库的压力
select_related:指定外键,将本表与该外键关联的表拼成一张表(inner join),并获取所有数据到内存,不能指定多对多关系的外键
prefetch_related:指定外键,先查询本表所有数据,再根据外键查询对应的数据表所有数据,相当于子查询,可以指定多个外键,即多个子查询
Django中如何开启事务
Django框架本身提供了两种事务操作的用法。(针对mysql)
启用事务用法1:
from django.db import transaction
from rest_framework.views import APIView
class OrderAPIView(APIView):
@transaction.atomic # 开启事务,当方法执行完以后,自动提交事务
def post(self, request):
pass #
启用事务用法2:
from django.db import transaction
from rest_framework.views import APIView
class OrderAPIView(APIView):
def post(self,request):
....
with transation.atomic(): # 开启事务,当with语句执行完成以后,自动提交事务
pass # 数据库操作
在使用事务过程中,有时候会出现异常,当出现异常的时候,我们需要让程序停下来,同时回滚事务。
from django.db import transaction
from rest_framework.views import APIView
class OrderAPIView(APIView):
def post(self,request):
....
with transation.atomic():
# 设置事务回滚的标记点
sid = transation.savepoint()
....
try:
....
except:
transation.savepoint_rallback(sid)
ORM常用字段及查询的更多相关文章
- Django框架之第六篇(模型层)--单表查询和必知必会13条、单表查询之双下划线、Django ORM常用字段和参数、关系字段
单表查询 补充一个知识点:在models.py建表是 create_time = models.DateField() 关键字参数: 1.auto_now:每次操作数据,都会自动刷新当前操作的时间 2 ...
- 06 ORM常用字段 关系字段 数据库优化查询
一.Django ORM 常用字段和参数 1.常用字段 models中所有的字段类型其实本质就那几种,整形varchar什么的,都没有实际的约束作用,虽然在models中没有任何限制作用,但是还是要分 ...
- ORM常用字段介绍
Django中的ORM Django项目使用MySQL数据库 1. 在Django项目的settings.py文件中,配置数据库连接信息: DATABASES = { "default&qu ...
- Django(ORM常用字段)
day68 参考:http://www.cnblogs.com/liwenzhou/p/8688919.html 1. Django ORM常用字段: 1. AutoField ...
- Django框架 之 ORM 常用字段和参数
Django框架 之 ORM 常用字段和参数 浏览目录 常用字段 字段合集 自定义字段 字段参数 DateField和DateTimeField 关系字段 ForeignKey OneToOneFie ...
- python 之 Django框架(ORM常用字段和字段参数、关系字段和和字段参数)
12.324 Django ORM常用字段 .id = models.AutoField(primary_key=True):int自增列,必须填入参数 primary_key=True.当model ...
- Django中ORM常用字段及字段参数
Object Relational Mapping(ORM) ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据 ...
- Django orm常用字段和字段参数
1.Object Relational Mapping(ORM) 1.1ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象 ...
- ORM常用字段及方式
创建小型数据库 模型层 ORM常用字段 AutoField int自增列,必须填入参数 primary_key=True.当model中如果没有自增列,则自动会创建一个列名为id的列. Integer ...
随机推荐
- Navicat连接两个不同机子上的mysql数据库,端口用换吗?--不用
经过了上一篇的努力,成功的连上了远程的mysql数据库 dos 命令行下的成功连接 在用Navicat连接的时候要注意: 端口仍然是3306,而不用去更改,并不会和上面的本机的Mysql连接使用的端口 ...
- PHP POST请求 字符串和数组传值的区别
最近工作中需要请求一个API,由于之前接过类似的就直接拿来写好的函数使用.但数据死活就是传不过去,一只返回err. 代码如下: function post_params($url, $params,$ ...
- 2.1.FastDFS-单机拆分版-单机版安装配置
Centos610系列配置 1.什么是FastDFS? FastDFS是一个开源的分布式文件系统,她对文件进行管理,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负 ...
- sort的使用
sort主要是用来排序的,可以用自定义的函数进行比较,也可以用系统的4中函数进行比较,即less(),greater(),less_equal(),greater_equal().但是我试了一下,发现 ...
- C++学会STL
1.1 泛型程序设计简介 泛型程序设计,简单地说就是使用模板的程序设计法.将一些常用的数据结构(比如链表,数组,二叉树)和算法(比如排序,查找)写成模板,以后则不论数据结构里放的是什么对象,算法针对什 ...
- spring data flow
spring data flow相当于一个快速发布应用的平台.并可以通过消息队列(kafa,rabbitMQ)把多个应用链接在一起进行链式处理数据.支持的平台是: Cloud Foundry Apac ...
- Springboot学习:介绍与HelloWorld
1. 什么是 Spring boot Spring Boot来简化Spring应用开发,约定大于配置,去繁从简,just run就能创建一个独立的,产品级别的应用 整个Spring技术栈的一个大整合 ...
- Shell编程WEB界面展示实践
操作系统:win7 虚拟机:Virtual box with Ubuntu13.10 WEB服务器: Nginx WEB服务器发布目录:/usr/local/nginx/html/c 测试文件:lis ...
- 重新梳理IT知识之java-03循环
引用变量时要给变量赋值,如果循环进不去就会报错. 一.循环结构的四要素 1.初始化条件 2.循环条件 ---> 是Boolean类型 3.循环体 4.迭代条件 说明:通常情况下,循环结束都是因为 ...
- bootstrap-suggest-plugin input可选可输(表单) 好用的前端插件
bootstrap-suggest-plugin DEMO下载 1.准备:页面引入(点击下载) <link rel="stylesheet" href=&q ...