06.深入浅出 Spring Boot - 数据访问之Druid
- 代码下载:https://github.com/Jackson0714/study-spring-boot.git
- 05. 深入浅出 Spring Boot - 数据访问之JDBC(源码分析+代码下载)
- 06. 深入浅出 Spring Boot - 数据访问之Druid(附代码下载)
一、Druid是什么?
1、Druid是数据库连接池,功能、性能、扩展性方面都算不错。最大的亮点是为监控而生的数据库连接池。
2、数据库、数据源、数据库连接池、JDBC、JDBC实现是什么关系?
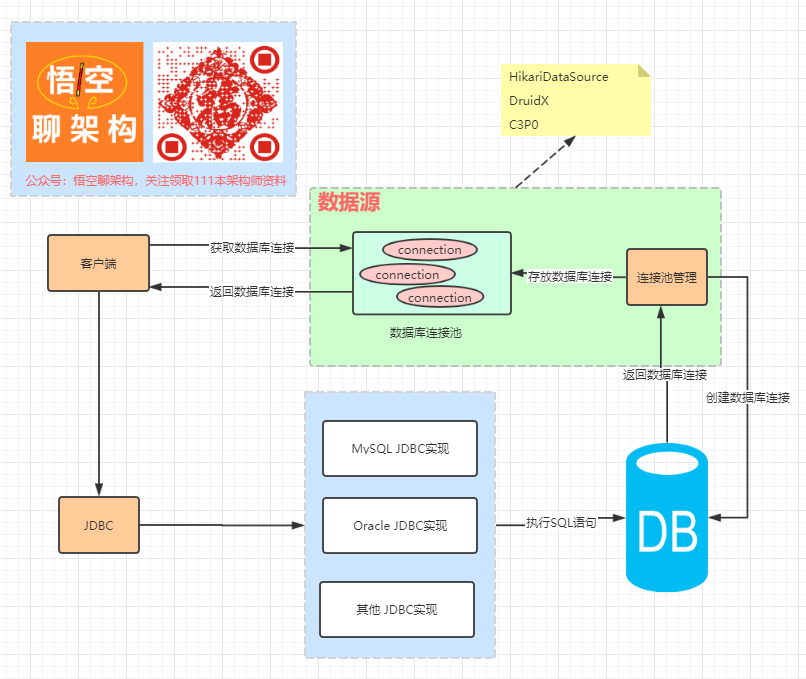
- JDBC:Java和关系型数据库的桥梁,是一个规范,不是实现。不同类型的数据库需要有自己的JDBC实现
- 数据源:包含数据库连接池,连接池管理。常见的有C3P0、HikariDataSoiurce、Druid等
- 连接池:预先创建一些数据库连接,放到连接池里面,用的时候从连接池里面取,用完后放回连接池
- 连接池管理:创建数据库连接,管理数据库连接
- JDBC实现:MySQL JDBC实现、Oracle JDBC实现等其他实现
二、使用Druid数据源
1. 从Maven仓库找到Druid数据源
https://mvnrepository.com/search?q=druid
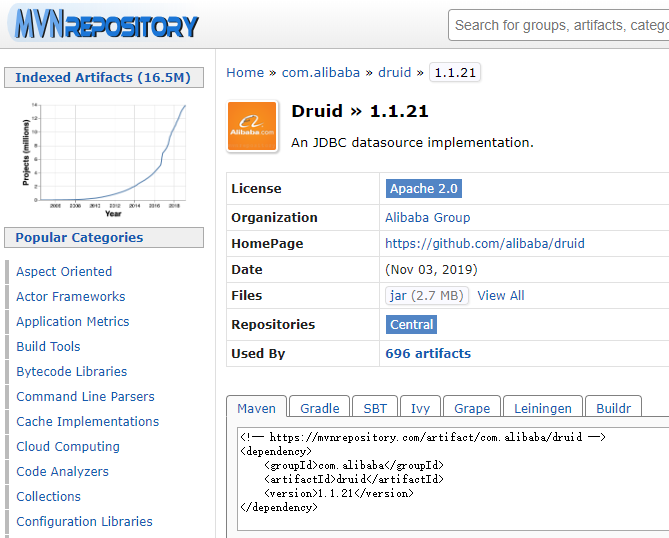
2. 引入druid依赖
<!-- Druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
3. 修改数据源
修改application.yml文件,增加type属性
type: com.alibaba.druid.pool.DruidDataSource
数据源:class com.alibaba.druid.pool.DruidDataSource
数据库连接:com.mysql.cj.jdbc.ConnectionImpl@202898d7
4. 设置属性
- 修改application.yml文件,增加数据源配置
# druid 配置
dbType: mysql # 指定数据库类型 mysql
initialSize: 5 # 启动初始化连接数量
minIdle: 5 # 最小空闲连接
maxActive: 20 # 最大连接数量(包含使用中的和空闲的)
maxWait: 60000 # 最大连接等待时间 ,超出时间报错
timeBetweenEvictionRunsMillis: 60000 # 设置执行一次连接回收器的时间
minEvictableIdleTimeMillis: 300000 # 设置时间: 该时间内没有任何操作的空闲连接会被回收
validationQuery: select 'x' # 验证连接有效性的sql
testWhileIdle: true # 空闲时校验
testOnBorrow: false # 使用中是否校验有效性
testOnReturn: false # 归还连接池时是否校验
poolPreparedStatements: false # mysql 不推荐打开预处理连接池
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j # 设置过滤器 stat用于接收状态,wall防止sql注入,logback说明使用logback进行日志输出
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true # 统计所有数据源状态
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500 # sql合并统计 设置慢sql时间为500,超过500 会有记录提示
- 添加DruidConfig.java文件,使上面的属性生效
package com.jackson0714.springboot.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid() {
return new DruidDataSource();
}
// 配置Durid监控
// 1、配置一个管理后台的Servlet
@Bean
public ServletRegistrationBean statViewServlet() {
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
Map<String, String> servletInitParams = new HashMap<>();
servletInitParams.put("loginUserName", "Admin");
servletInitParams.put("loginPassword", "abc123");
servletInitParams.put("deny","192.168.10.160"); // 拒绝访问
servletInitParams.put("allow",""); // 默认允许所有
servletRegistrationBean.setInitParameters(servletInitParams);
return servletRegistrationBean;
}
// 2、配置一个web监控的filter
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(new WebStatFilter());
Map<String, String> filterInitParams = new HashMap<>();
filterInitParams.put("exclusions", "*.js,*.css,/druid/*");// 不拦截js、css文件请求,不拦截/druid/*的请求
filterRegistrationBean.setInitParameters(filterInitParams);
filterRegistrationBean.setUrlPatterns(Arrays.asList("/*")); // 拦截所有请求
return filterRegistrationBean;
}
}
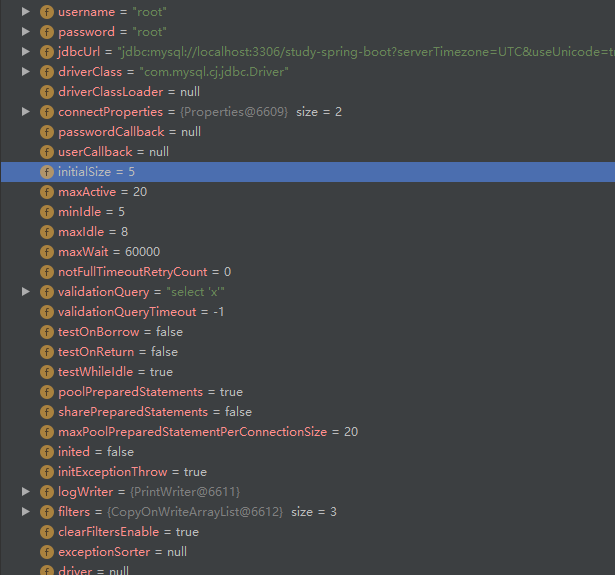
运行测试程序,可以看到DataSource中的属性值已经与配置文件中的相同
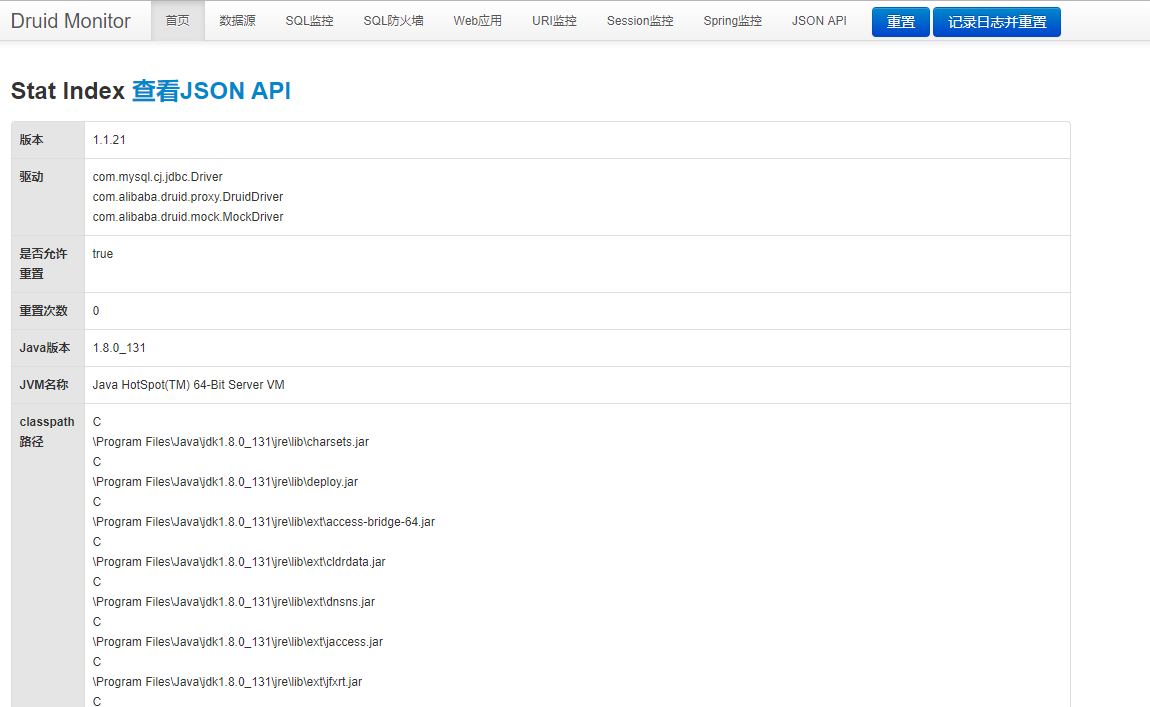
5. Druid监控
- 先用ip地址访问druid后台
http://192.168.10.160:8082/druid
会提示没有权限访问该后台

- 正常进入后可以看到监控后台
- 执行SQL语句
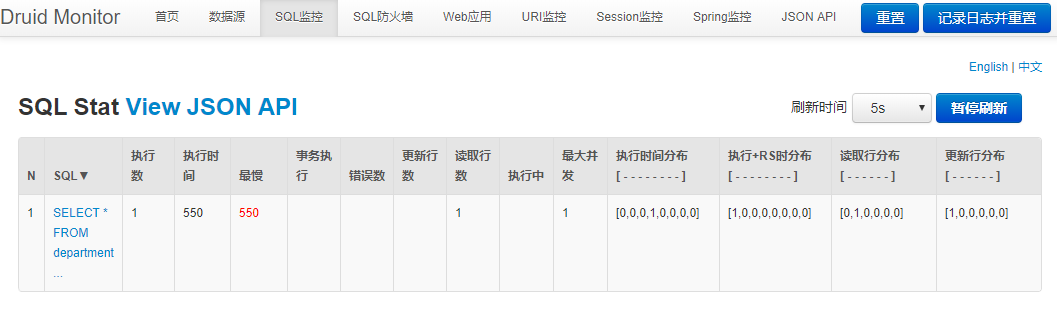
查看监控:
有一条查询请求的记录
三、技术问题
1. 报错 Failed to bind properties under 'spring.datasource' to javax.sql.DataSource:
***************************
APPLICATION FAILED TO START
***************************
Description:
Failed to bind properties under 'spring.datasource' to javax.sql.DataSource:
Property: spring.datasource.filters
Value: stat,wall,log4j
Origin: class path resource [application.yml]:23:14
Reason: org.apache.log4j.Logger
Action:
Update your application's configuration
Process finished with exit code 1
解决方案:pom.xml文件中添加log4j的配置
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2. Druid设置了登录账号和密码但是没有进入登录页面
servletInitParams.put("loginUsername", "Admin");
servletInitParams.put("loginPassword", "abc123");

未找到解决方案
下一篇我们来讲Spring Boot 整合 MyBatis
关注公众号:悟空聊架构,回复pmp,领取pmp资料!回复悟空,领取架构师资料!

关注我,带你每天进步一点点!
06.深入浅出 Spring Boot - 数据访问之Druid的更多相关文章
- 07.深入浅出 Spring Boot - 数据访问之Mybatis(附代码下载)
MyBatis 在Spring Boot应用非常广,非常强大的一个半自动的ORM框架. 代码下载:https://github.com/Jackson0714/study-spring-boot.gi ...
- Spring Boot数据访问之Druid连接池的配置
在Spring Boot数据访问之数据源自动配置 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中数据源连接池方式缺省(type)情况下默认使用HikariCP,那不缺省如何配置呢?我们 ...
- Spring Boot数据访问之多数据源配置及数据源动态切换
如果一个数据库数据量过大,考虑到分库分表和读写分离需要动态的切换到相应的数据库进行相关操作,这样就会有多个数据源.对于一个数据源的配置在Spring Boot数据访问之数据源自动配置 - 池塘里洗澡的 ...
- Spring Boot数据访问之动态数据源切换之使用注解式AOP优化
在Spring Boot数据访问之多数据源配置及数据源动态切换 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中详述了如何配置多数据源及多数据源之间的动态切换.但是需要读数据库的地方,就 ...
- Spring Boot数据访问之整合Mybatis
在Mybatis整合Spring - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中谈到了Spring和Mybatis整合需要整合的点在哪些方面,需要将Mybatis中数据库连接池等相关对 ...
- Spring Boot 数据访问集成 MyBatis 与事物配置
对于软件系统而言,持久化数据到数据库是至关重要的一部分.在 Java 领域,有很多的实现了数据持久化层的工具和框架(ORM).ORM 框架的本质是简化编程中操作数据库的繁琐性,比如可以根据对象生成 S ...
- Spring Boot数据访问之数据源自动配置
Spring Boot提供自动配置的数据访问,首先体验下,Spring Boot使用2.5.5版本: 1)导入坐标: 2.5.25版本支持8.0.26mysql数据库驱动.spring-boot-st ...
- SpringBoot数据访问之Druid数据源的使用
数据访问之Druid数据源的使用 说明:该数据源Druid,使用自定义方式实现,后面文章使用start启动器实现,学习思路为主. 为什么要使用数据源: 数据源是提高数据库连接性能的常规手段,数据源 ...
- SpringBoot数据访问之Druid启动器的使用
数据访问之Druid启动器的使用 承接上文:SpringBoot数据访问之Druid数据源的自定义使用 官方文档: Druid Spring Boot Starter 首先在在 Spring Boot ...
随机推荐
- jenkins_2
1.jenkins pipline:一些列jenkins插件将整个CD(持续交付过程)用解释性代码Jenkinsfile来描述(之前的都是通过配置设置的,这次是通过file) 2.创建一个流水线任务 ...
- Elasticsearch-URL查询实例解析
ES(elasticsearch),以下简称ES ES的查询有query.URL两种方式,而URL是比较简洁的一种,本文主要以实例探讨和总结URL的查询方式 1.语法 curl [ -s][ -g][ ...
- git 学习系列(一)
目录 git 简介 git的升级 建立仓库 克隆仓库 查看主机名 查看仓库初始状态 将文件提交到暂存区 查看修改详情 提交修改 查看修改记录 查看个人配置信息(在 .gitconfig 文件中) 查看 ...
- [LC] 23. Merge k Sorted Lists
Merge k sorted linked lists and return it as one sorted list. Analyze and describe its complexity. E ...
- 单独安装jenkins-没有tomcat
这里讲解war包的安装:windows的msi版安装很简单,双击即可,不用讲 1.官网下载 2. 3.把war包放到java目录下 4. 5.安装完成后打开:127.0.0.1:8080 输入密码后会 ...
- kafka spark steam 写入elasticsearch的部分问题
应用版本 elasticsearch 5.5 spark 2.2.0 hadoop 2.7 依赖包版本 docker cp /Users/cclient/.ivy2/cache/org.elastic ...
- seek for|contrary to|lag behind|take up|take advantage of|be confident of|allow for |
There are signs ________ restaurants are becoming more popular with families. A. that B. which C. ...
- python3下应用pymysql(第二卷)
上一卷讲述的是单条插入数据,现在要多条插入数据: 随意定义了一批数据 去数据库查询一下: 下面试一下查询语句: 获取游标里的数据,结果如下: 下面更改下返回数据类型,如果想用字典类型: 结果如下: 在 ...
- Java编程风格节选
3.3 import语句 3.3.1 import不要使用通配符 即,不要出现类似这样的import语句:import java.util.*; 3.3.2 不要换行 import语句不换行,列限制( ...
- Zabbix 监控进程参考
1)zabbix自动发现占用内存最大top10进程并监控资源 http://blog.csdn.net/ybx13218464908/article/details/47819401