入门大数据---Sqoop简介与安装
一、Sqoop 简介
Sqoop 是一个常用的数据迁移工具,主要用于在不同存储系统之间实现数据的导入与导出:
导入数据:从 MySQL,Oracle 等关系型数据库中导入数据到 HDFS、Hive、HBase 等分布式文件存储系统中;
导出数据:从 分布式文件系统中导出数据到关系数据库中。
其原理是将执行命令转化成 MapReduce 作业来实现数据的迁移,如下图:
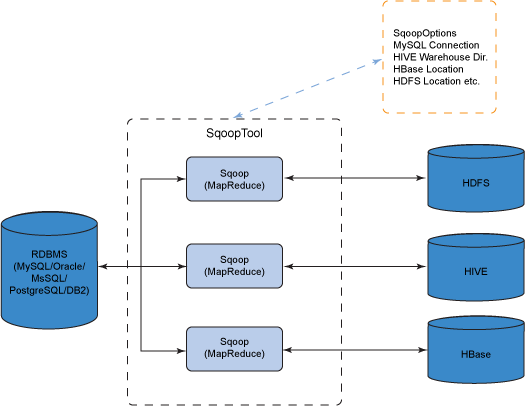
二、安装
版本选择:目前 Sqoop 有 Sqoop 1 和 Sqoop 2 两个版本,但是截至到目前,官方并不推荐使用 Sqoop 2,因为其与 Sqoop 1 并不兼容,且功能还没有完善,所以这里优先推荐使用 Sqoop 1。
2.1 下载并解压
下载所需版本的 Sqoop ,这里我下载的是 CDH 版本的 Sqoop 。下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# 下载后进行解压
tar -zxvf sqoop-1.4.6-cdh5.15.2.tar.gz
2.2 配置环境变量
# vim /etc/profile
添加环境变量:
export SQOOP_HOME=/usr/app/sqoop-1.4.6-cdh5.15.2
export PATH=$SQOOP_HOME/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
2.3 修改配置
进入安装目录下的 conf/ 目录,拷贝 Sqoop 的环境配置模板 sqoop-env.sh.template
# cp sqoop-env-template.sh sqoop-env.sh
修改 sqoop-env.sh,内容如下 (以下配置中 HADOOP_COMMON_HOME 和 HADOOP_MAPRED_HOME 是必选的,其他的是可选的):
# Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
#set the path to where bin/hbase is available
export HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2
#Set the path to where bin/hive is available
export HIVE_HOME=/usr/app/hive-1.1.0-cdh5.15.2
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/usr/app/zookeeper-3.4.13/conf
2.4 拷贝数据库驱动
将 MySQL 驱动包拷贝到 Sqoop 安装目录的 lib 目录下, 驱动包的下载地址为 https://dev.mysql.com/downloads/connector/j/ 。在本仓库的resources 目录下我也上传了一份,有需要的话可以自行下载。

2.5 验证
由于已经将 sqoop 的 bin 目录配置到环境变量,直接使用以下命令验证是否配置成功:
# sqoop version
出现对应的版本信息则代表配置成功:

这里出现的两个 Warning 警告是因为我们本身就没有用到 HCatalog 和 Accumulo,忽略即可。Sqoop 在启动时会去检查环境变量中是否有配置这些软件,如果想去除这些警告,可以修改 bin/configure-sqoop,注释掉不必要的检查。
# Check: If we can't find our dependencies, give up here.
if [ ! -d "${HADOOP_COMMON_HOME}" ]; then
echo "Error: $HADOOP_COMMON_HOME does not exist!"
echo 'Please set $HADOOP_COMMON_HOME to the root of your Hadoop installation.'
exit 1
fi
if [ ! -d "${HADOOP_MAPRED_HOME}" ]; then
echo "Error: $HADOOP_MAPRED_HOME does not exist!"
echo 'Please set $HADOOP_MAPRED_HOME to the root of your Hadoop MapReduce installation.'
exit 1
fi
## Moved to be a runtime check in sqoop.
if [ ! -d "${HBASE_HOME}" ]; then
echo "Warning: $HBASE_HOME does not exist! HBase imports will fail."
echo 'Please set $HBASE_HOME to the root of your HBase installation.'
fi
## Moved to be a runtime check in sqoop.
if [ ! -d "${HCAT_HOME}" ]; then
echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail."
echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
fi
if [ ! -d "${ACCUMULO_HOME}" ]; then
echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail."
echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.'
fi
if [ ! -d "${ZOOKEEPER_HOME}" ]; then
echo "Warning: $ZOOKEEPER_HOME does not exist! Accumulo imports will fail."
echo 'Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.'
fi
入门大数据---Sqoop简介与安装的更多相关文章
- 入门大数据---Flume 简介及基本使用
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- 入门大数据---Sqoop基本使用
一.Sqoop 基本命令 1. 查看所有命令 # sqoop help 2. 查看某条命令的具体使用方法 # sqoop help 命令名 二.Sqoop 与 MySQL 1. 查询MySQL所有数据 ...
- 入门大数据---Kafka简介
一.简介 ApacheKafka 是一个分布式的流处理平台.它具有以下特点: 支持消息的发布和订阅,类似于 RabbtMQ.ActiveMQ 等消息队列: 支持数据实时处理: 能保证消息的可靠性投递: ...
- 入门大数据---Spark简介
一.简介 Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目.相对于 MapRedu ...
- 入门大数据---通过Flume、Sqoop分析日志
一.Flume安装 参考:Flume 简介及基本使用 二.Sqoop安装 参考:Sqoop简介与安装 三.Flume和Sqoop结合使用案例 日志分析系统整体架构图: 3.1配置nginx环境 请参考 ...
- 【大数据之数据仓库】安装部署GreenPlum集群
本篇将向大家介绍如何快捷的安装部署GreenPlum测试集群,大家可以跟着我一块儿实践一把^_^ 1.主机资源 申请2台网易云主机,操作系统必须是RedHat或者CentOS,配置尽量高一点.如果是s ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- Sqoop简介及安装
Hadoop业务的大致开发流程以及Sqoop在业务中的地位: Sqoop概念 Sqoop可以理解为[SQL–to–Hadoop],正如名字所示,Sqoop是一个用来将关系型数据库和Hadoop中的数据 ...
随机推荐
- jQuery-stop方法
1.stop()方法解析 停止所有在指定元素上正在运行的动画 stop(clearQueue,gotoEnd) 这个两个参数可选值是布尔值 stop(flase,flase):不请空动画队列,不立即跳 ...
- 【Storm】与Hadoop的区别
1)Storm用于实时计算,Hadoop用于离线计算. 2)Storm处理的数据保存在内存中,源源不断:Hadoop处理的数据保存在文件系统中,一批一批处 理. 3)Storm的数据通过网络传输进来: ...
- java中ReentrantLock类的详细介绍(详解)
博主如果看到请联系小白,小白记不清地址了 简介 ReentrantLock是一个可重入且独占式的锁,它具有与使用synchronized监视器锁相同的基本行为和语义,但与synchronized关键字 ...
- Java实现 洛谷 P1423 小玉在游泳
import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner in = ...
- java实现海盗比酒量
** 海盗比酒量** 有一群海盗(不多于20人),在船上比拼酒量.过程如下:打开一瓶酒,所有在场的人平分喝下,有几个人倒下了.再打开一瓶酒平分,又有倒下的,再次重复- 直到开了第4瓶酒,坐着的已经所剩 ...
- java实现第四届蓝桥杯逆波兰表达式
逆波兰表达式 正常的表达式称为中缀表达式,运算符在中间,主要是给人阅读的,机器求解并不方便. 例如:3 + 5 * (2 + 6) - 1 而且,常常需要用括号来改变运算次序. 相反,如果使用逆波兰表 ...
- 嵌入式Linux内核开发工程师必须掌握的三十道题
如果你能正确回答以下问题并理解相关知识点原理,那么你就可以算得上是基本合格的Linux内核开发工程师. 1. Linux中主要有哪几种内核锁?(进程同步与互斥) (1)自旋锁:非睡眠锁 (2)信号量: ...
- 五月天的线上演唱会你看了吗?用Python分析网友对这场线上演唱会的看法
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:CDA数据分析师 豆瓣9.4分!这场线上演唱会到底多好看? 首先让我 ...
- Html/css 水平布局居中
如何设置水平居中显示? 一般的方法是设置宽高,然后以margin去控制,比如:DIV居中的经典方法 本章介绍需要宽度自适应时如何水平居中,以及居中失效的几个点 水平自适应居中 比如设置一个列表水平居中 ...
- Maven 在Mac下的配置
1.下载maven 解压到本地目录 官网下载Maven安装文件,如apache-maven-3.2.3-bin.tar.gz,然后解压到本地目录 解压: tar -zxcf apache-maven- ...