k近邻法(一)
简介
k近邻法(k-nearest neighbors algorigthm) 是一种最基本的用于分类和回归的方法之一,当没有关于训练数据的分布时,首先最容易想到的就是采用k近邻法。
k近邻法输入为实例的特征向量,输出为实例的类别。算法思想是,给定训练数据集,对应输入空间的各个数据点,要判断一个新的数据点的分类,则取目标数据点最近的k个数据点,
然后统计这k个数据点中每个分类各占多少,并取数量最多的那个分类作为目标数据点的分类。
上面说到的“最近”?那么何为最近?
k近邻法通常采用欧式距离来表征两个数据点的距离,距离越小,这两个数据点越近。
假设数据点x具有n维度(n个特征),
x=[x1,x2, ... , xn]T
数据xi和xj的距离则为
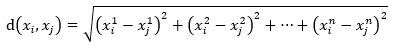
当然,还可以采用Minkowski距离,这是更一般的形式
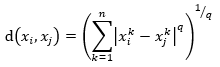
其中,q >= 1.
当q=1,为曼哈顿距离(Manhattan distance)
当q=2,为欧式距离(Euclidean distance)
当q=+∞,为两个点映射到各个坐标距离的最大值
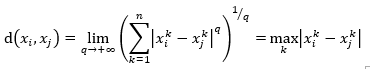
值得注意的是上面所说的距离适用于数据点的特征向量的(行列式)值是连续的,或者说向量各维度的值是连续的。
对于分类变量(categorical variables),则使用汉明距离(Hamming distance),

其中,x是n维向量,每个维度的取值为{0,1},为0或者为1,汉明距离就是统计对应各维度值不等的个数。
k值的选择
如果k值较小,则使用较小的邻域中的数据点进行预测,则近似误差会减小,因为避免了较大邻域可能会有大量其他分类的数据点来干扰预测,
然而邻域也不能选择太小,否则一旦出现数据点是噪声(实际应用中肯定存在),预测同样会受到噪声干扰,此时没有足够的正确的数据点来帮助预测分类。
综上算法就是,计算训练数据集中每个数据点与需要预测的数据点的距离,并找出距离最小的k个数据点,然后将这k个数据点归类,数量最多的那个分类就是预测的数据点分类
然而,由于实际中给定的训练数据集可能比较大,这样每次预测一个数据点时,都要经过上面的过程计算,会耗费很长时间,所以需要想方设法提高计算效率,一个常见的方法如下介绍。
kd树
kd树(k-dimensional tree)是一种空间切分的数据结构,是一种特殊二叉树,很奇怪的是,k维到底是什么含义?唔,我也没有去想搞清楚它,但显然不是指k近邻法中的k,也不是指数据点的维度n,
我这里就把k-d树看成一个整体,名字就要k-d tree, -_-!! 比如使用二维空间的数据集生成2维的k-d tree
kd树应用于多维空间数据的搜索(比如范围搜索和最近邻搜索)。
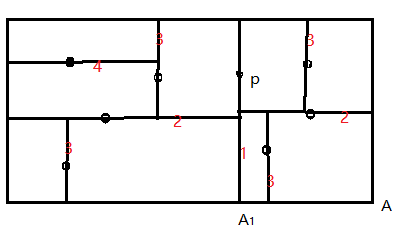
每个非叶节点可以认为隐式地形成一个切分超平面,将空间分为两部分,位于超平面左侧(假定一个超平面法向量,左侧可以认为是法向量的反向,那么右侧是法向量的正向)的数据点则构成这个非叶节点的左子树,
右侧的数据点构成此非叶节点的右子树。超平面的方法这样选择:每个树中节点关联这k维中的一维,对应的超平面垂直于这个维度的轴。举个例子,假设某个超平面经过点p垂直切分某个轴"A"(对应某个维度),切点为A1,
那么在这个维度上,值小于A1的数据点位于这个超平面左侧,而大于A1的数据点位于超平面右侧,如下图就是p有一个共4节点的左子树,有一个共3节点的右子树。另外,为了使生成的二叉树平衡,选择一个节点来形成
切分超平面时,尽量从当前剩余的数据点中使用在某维度上具有中值或者接近中值的数据点

构造kd树
输入:数据集 T = {x1, x2, ... , xN}, y忽略不写,其中x是n维向量
输出:n维 kd树
步骤如下:
- 选择第一个维度1作为坐标轴,在维度1上,选择N个数据点中具有中值或者接近中值(如稍大于中值)的数据点作为根节点,剩下的节点被划分到左右两个子空间(根据此维度上的值与那个中值做比较)
- 由根节点生成深度为d=1的左右两个子节点,这两个子节点的选择方法如下,对于左子空间的数据点,选择d mod n + 1(d=1时,维度为2)维度作为坐标轴,选择左子空间的的中值(或接近中值)的点作为左子节点,右子节点类似,这样分别又生成两个子空间,共四个子空间
- 由深度为d=1的两个节点生成深度d=2的四个子节点,这四个子节点的选择方法类似步骤2,如此递归选择下去,直到每个数据点都对应kd树中的某个节点(到最后时,如果子空间只剩一个数据点,那么就选择这个数据点了作为子节点,也即,叶节点)
如下图,所示,图中数字表明步骤
搜索kd树
先来讨论最近邻搜索
输入:kd树,目标点x,假设维度为n
输出:x的最近邻
步骤:
- 第一次,次数 t = 2,从根结点开始,递归向下访问节点。假设根节点为xi1,选择第一维来比较,如果x此维度坐标值小于根节点坐标值,则访问xi1的左子节点,否则访问右子节点(包括两个坐标值相等的情况),假设为xi2
- 第二次,次数 t = 2,选择维度 t mod n,与上一步中的节点xi2进行选定维度上的坐标值比较,同样地,x 坐标值小于节点的坐标值,则访问这个xi2的左子节点,否则访问右子节点,假设为xi3
- 如此递归下去,直到遇到叶节点,以此叶节点为 “当前最近邻点”xit。
- 然而,这个节点并不一定是真的最近邻,因为我们每次只是比较某一维度,这并不代表距离,所以不一定是最近邻,但即使是使用某一个维度这种片面的比较方法,我们也是尽量的选择距离比较近的点,至于是不是真正的最近邻,还不确定,需要向上回溯,沿搜索路径反向查找是否有距离更近的点。
- 如果向上回溯的过程中,发现有距离更近的点,则以此点作为“当前最近邻点”。具体方法为:在步骤3中找到“当前最近邻点”xit后,令xit的父节点为xip,比较xip与xit谁与目标点x更近,将更近的点重新设为xit,然后以目标点x为球心,x到xit的距离为半径形成一个(超)球体,并查看是否与经过xip的超平面相交,如果相交,则说明xip的另一个子区域可能存在一个更近的点,到另一个子区域继续向下递归找到“当前最近邻点”,然后开始向上回溯。如果球体与超平面不相交,则“当前最近邻”点依然是原来的xit。然后,继续回溯到xip的父节点xio,比较xio与xit谁与目标点x更近,将更近的点重新设为xit,以x为球心,x到这时的xit的距离为半径形成一个超球体,看是否与经过xio的超平面相交,重复前面的过程,判断出此轮“当前最近邻”点xit,并继续回溯到xio的父节点,直到回溯到根节点并作这一轮判断后,结束搜索,根节点这一轮获得的“当前最近邻”就是最终真正的最近邻点。
总结一下,用更简洁的语言描述为:
- 从root节点开始,DFS搜索直到叶子节点,同时在stack中顺序存储已经访问的节点。
- 如果搜索到叶子节点,当前的叶子节点被设为最近邻节点。
- 然后通过stack回溯:如果当前点的距离比最近邻点距离近,更新最近邻节点.然后检查以最近距离为半径的圆是否和父节点的超平面相交.如果相交,则必须到父节点的另外一侧,用同样的DFS搜索法,开始检查最近邻节点,同样,需要将已访问的节点存储到stack中。如果不相交,则继续往上回溯,而父节点的另一侧子节点都被淘汰,不再考虑的范围中.
- 当搜索回到root节点时,搜索完成,得到最近邻节点。
最后,给出kd树相关的代码说明,注意,代码未经测试,不保证一定能运行,且代码书写简便,未考虑性能优化,仅帮助理解kd树构建和查询过程
public class Point
{
/// <summary>
/// 数据点的实数空间特征向量
/// </summary>
public double[] vector;
public Point(double[] vector)
{
this.vector = vector;
} /// <summary>
/// 计算两个点之间的欧式距离
/// </summary>
/// <param name="other"></param>
/// <returns></returns>
public double Distance(Point other)
{
if (this.vector.Length != other.vector.Length) throw new Exception(""); double squareSum = 0;
for(int i = 0; i < vector.Length; i++)
{
squareSum += Math.Pow((vector[i] - other.vector[i]), 2);
}
return Math.Sqrt(squareSum);
} public bool EqualsTo(Point other)
{
if (vector.Length != other.vector.Length) return false;
for(int i = 0; i < vector.Length; i++)
{
if (vector[i] != other.vector[i])
return false;
}
return true;
}
} public class Range
{
public double[,] boundaries; public static Range CreateInf(int dim)
{
var r = new Range(dim);
for(int i = 0; i < dim; i++)
{
r.boundaries[i, 0] = double.MinValue;
r.boundaries[i, 1] = double.MaxValue;
}
return r;
}
public Range(int dim)
{
boundaries = new double[dim,2];
} public Range(double[,] boundaries)
{
this.boundaries = boundaries;
} public Range Intersect(Range r)
{
if (r.boundaries.Length != this.boundaries.Length) throw new Exception(""); var range = new Range(this.boundaries.Length);
for(int i = 0; i < this.boundaries.Length; i++)
{
var leftMax = this.boundaries[i,0] > r.boundaries[i,0] ? this.boundaries[i, 0] : r.boundaries[i, 0];
var rightMin = this.boundaries[i, 1] < r.boundaries[i, 1] ? this.boundaries[i, 1] : r.boundaries[i, 1];
range.boundaries[i, 0] = leftMax;
range.boundaries[i, 1] = rightMin;
}
return range;
} /// <summary>
/// 经过点并垂直于坐标轴切割空间,并获取左侧(轴上较小值)空间
/// </summary>
/// <param name="p"></param>
/// <param name="axis">轴标号,从0开始</param>
/// <returns></returns>
public static Range LeftRange(Point p, int axis)
{
if (axis >= p.vector.Length) throw new Exception(""); var range = CreateInf(p.vector.Length);
range.boundaries[axis, 1] = p.vector[axis];
return range;
}
public static Range RightRange(Point p, int axis)
{
if (axis >= p.vector.Length) throw new Exception(""); var range = CreateInf(p.vector.Length);
range.boundaries[axis, 0] = p.vector[axis];
return range;
}
} public class TreeNode
{
/// <summary>
/// related point
/// </summary>
public Point point;
/// <summary>
/// perpendicular on which axis the splitted hyperplane is
/// </summary>
public int axis; public TreeNode parent;
public TreeNode left;
public TreeNode right; public Range range;
public bool isVisited;
public bool isLeftVisited;
}
public class KDTree
{
/// <summary>
/// root of this K-D tree
/// </summary>
public TreeNode root;
/// <summary>
/// dimension
/// </summary>
public int dim;
/// <summary>
/// Constructor according to a given list of trainning points
/// </summary>
/// <param name="points"></param>
public KDTree(List<Point> points)
{
dim = points[0].vector.Length;
root = new TreeNode() { range = Range.CreateInf(dim) }; RecursivelyConstruct(root, points, 0);
} /// <summary>
/// 递归构造K-D树,直到所有数据点被分配完成
/// </summary>
/// <param name="node">当前需要确定对应哪个数据点的节点</param>
/// <param name="points">当前未分配的数据点</param>
/// <param name="depth">当前节点的深度(root为0)</param>
private void RecursivelyConstruct(TreeNode node, List<Point> points, int depth)
{
if(points.Count == 1)
{
node.point = points[0];
return;
} var axis = GetAxis4SplitByVar(points);
var m = GetMedianIndex(points, axis);
node.axis = axis;
node.point = points[m]; if (m > 0) // has left subregion
{
var t = CreateChildNode(node, true, m, axis, points);
RecursivelyConstruct(t.Item1, t.Item2, depth + 1);
}
if(m < points.Count - 1) // has right subregion
{
var t = CreateChildNode(node, false, m, axis, points);
RecursivelyConstruct(t.Item1, t.Item2, depth + 1);
}
} /// <summary>
/// 搜索与给定点最近的点
/// </summary>
/// <param name="p"></param>
/// <returns></returns>
public Point SearchNearestNode(Point p)
{
var stack = new Stack<TreeNode>(); // to store those visited nodes
DownRecurseSearch(p, root, stack); var leaf = stack.Pop();
var node = Traceback(p, leaf, stack);
return node.point;
} /// <summary>
/// 向下递归访问节点直到遇到叶节点
/// 考虑了某一个子节点为空的情况
/// </summary>
/// <param name="p"></param>
/// <param name="n"></param>
/// <param name="stack"></param>
private void DownRecurseSearch(Point p, TreeNode n, Stack<TreeNode> stack)
{
stack.Push(n);
n.isVisited = true;
if (n.left == null && n.right == null) return; // leaf reached if (GoDownLeftFirst(p, n)) // go down left as soon as posssible
{
if(n.left != null && !n.left.isVisited)
DownRecurseSearch(p, n.left, stack);
else if(n.right != null && !n.right.isVisited)
DownRecurseSearch(p, n.right, stack);
}
else // go down right as soon as posssible
{
if (n.left != null && !n.left.isVisited)
DownRecurseSearch(p, n.left, stack);
else if (n.right != null && !n.right.isVisited)
DownRecurseSearch(p, n.right, stack);
}
} /// <summary>
/// 继续向下访问节点的子节点,true -> left child node; false -> right child node
/// </summary>
/// <param name="p"></param>
/// <param name="n"></param>
/// <returns></returns>
private bool GoDownLeftFirst(Point p, TreeNode n)
{
var axis = n.axis;
return p.vector[axis] < n.point.vector[axis];
} /// <summary>
/// 向上回溯查找最近邻点
/// </summary>
/// <param name="p">目标点</param>
/// <param name="n">当前最近邻点</param>
/// <param name="stack">已访问过的节点</param>
/// <returns></returns>
private TreeNode Traceback(Point p, TreeNode n, Stack<TreeNode> stack)
{
if (stack.Count == 0) { n.isVisited = false; return n; } var parent = stack.Pop(); // parent node of the current node n // check current node and its parent which is nearer to destination p?
var dn = p.Distance(n.point); // distance between n and p, and let it be the currently nearest distance
var dp = p.Distance(parent.point); // distance between parent and p
if (dp < dn)
{
dn = dp; // update the currently nearest distance
n = parent; // update the currently nearest node
} if (Intersect(p, dn, parent)) // 如果p为球心,当前最短距离为半径的超球体与父节点的切割超平明相交,则有必要去父节点的另一个空间向下递归查找最近邻点
{
// 当前父节点的另一个子空间,考虑了另一个子空间可能不存在数据点的情况
TreeNode other = null;
if (parent.left != null && !parent.left.isVisited)
other = parent.left;
else if (parent.right != null && !parent.right.isVisited)
other = parent.right;
if(other != null)
{
var localStack = new Stack<TreeNode>();
DownRecurseSearch(p, other, localStack);
var localNode = Traceback(p, localStack.Pop(), localStack); // get the nearest node in this local sub region
// update the min distance and nearest node if needed
var localDist = p.Distance(localNode.point);
if(localDist < dn)
{
dn = localDist;
n = localNode;
}
}
}
n.isVisited = false; // 离开当前节点前,重置其访问状态,因为其状态在本地搜索最近邻中已不再用到
// go on up-traceback
return Traceback(p, n, stack);
} /// <summary>
/// 以p为球心,radis为半径的超球体,是否与经过点n且与垂直于n的axis的超平面(切割超平面)相交
/// </summary>
/// <param name="p">目标点</param>
/// <param name="radis">当前的最近距离</param>
/// <param name="n">被考察的节点</param>
/// <returns></returns>
private bool Intersect(Point p, double radis, TreeNode n)
{
var axis = n.axis;
return Math.Abs(p.vector[axis] - n.point.vector[axis]) < radis;
} /// <summary>
/// 创建子节点
/// </summary>
/// <param name="parent">父节点</param>
/// <param name="isLeft">是否为左子节点</param>
/// <param name="m">父节点对应空间的数据集中位数索引</param>
/// <param name="axis">作用维度</param>
/// <param name="points">父节点对应空间的数据集</param>
/// <returns></returns>
private Tuple<TreeNode, List<Point>> CreateChildNode(TreeNode parent, bool isLeft, int m, int axis, List<Point> points)
{
var subRegion = isLeft ? points.Take(m).ToList() : points.Skip(m + 1).ToList();
var node = new TreeNode();
node.parent = node;
var range = isLeft ? Range.LeftRange(points[m], axis) : Range.RightRange(points[m], axis);
node.range = parent.range.Intersect(range);
if (isLeft)
parent.left = node;
else
parent.right = node;
return new Tuple<TreeNode, List<Point>>(node, subRegion);
}
/// <summary>
/// 选择方差最大的那个维度
/// </summary>
/// <param name="points"></param>
/// <returns></returns>
private int GetAxis4SplitByVar(List<Point> points)
{
var dim = points[0].vector.Length;
var aves = new double[dim]; double max = 0;
int axis = 0;
for(int i = 0; i < dim; i++)
{
aves[i] = points.Sum(p => p.vector[i]) / dim;
var variance = points.Sum(p => Math.Pow((p.vector[i] - aves[i]), 2)) / dim;
if (max < variance)
{
max = variance;
axis = i;
}
}
return axis;
} /// <summary>
/// 根据深度,轮选维度
/// </summary>
/// <param name="depth"></param>
/// <param name="dim"></param>
/// <returns></returns>
private int GetAxis4SplitByDep(int depth, int dim) => depth % dim; /// <summary>
/// Given a list of points and the concerned axis, get the index at which the point has a median on the concerned axis
/// </summary>
/// <param name="points"></param>
/// <param name="axis"></param>
/// <returns></returns>
private int GetMedianIndex(List<Point> points, int axis)
{
QuickSort(points, 0, points.Count - 1, axis);
return points.Count / 2;
}
private void QuickSort(List<Point> points, int start, int end, int axis)
{
if(start < end)
{
int s = start;
int e = end;
var pivot_i = (start + end) / 2;
var pivot_v = points[pivot_i].vector[axis];
while (s < e)
{
while (s < e && points[s].vector[axis] <= pivot_v)
{
s++;
}
while (e > s && points[e].vector[axis] >= pivot_v)
{
e--;
}
if (s < e)
{
var temp = points[s];
points[s] = points[e];
points[e--] = temp;
}
}
QuickSort(points, start, s - 1, axis);
QuickSort(points, s + 1, end, axis);
}
}
}
k近邻法(一)的更多相关文章
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- scikit-learn K近邻法类库使用小结
在K近邻法(KNN)原理小结这篇文章,我们讨论了KNN的原理和优缺点,这里我们就从实践出发,对scikit-learn 中KNN相关的类库使用做一个小结.主要关注于类库调参时的一个经验总结. 1. s ...
- 学习笔记——k近邻法
对新的输入实例,在训练数据集中找到与该实例最邻近的\(k\)个实例,这\(k\)个实例的多数属于某个类,就把该输入实例分给这个类. \(k\) 近邻法(\(k\)-nearest neighbor, ...
- 机器学习PR:k近邻法分类
k近邻法是一种基本分类与回归方法.本章只讨论k近邻分类,回归方法将在随后专题中进行. 它可以进行多类分类,分类时根据在样本集合中其k个最近邻点的类别,通过多数表决等方式进行预测,因此不具有显式的学习过 ...
- k近邻法
k近邻法(k nearest neighbor algorithm,k-NN)是机器学习中最基本的分类算法,在训练数据集中找到k个最近邻的实例,类别由这k个近邻中占最多的实例的类别来决定,当k=1时, ...
- 机器学习中 K近邻法(knn)与k-means的区别
简介 K近邻法(knn)是一种基本的分类与回归方法.k-means是一种简单而有效的聚类方法.虽然两者用途不同.解决的问题不同,但是在算法上有很多相似性,于是将二者放在一起,这样能够更好地对比二者的异 ...
- 《统计学习方法》笔记三 k近邻法
本系列笔记内容参考来源为李航<统计学习方法> k近邻是一种基本分类与回归方法,书中只讨论分类情况.输入为实例的特征向量,输出为实例的类别.k值的选择.距离度量及分类决策规则是k近邻法的三个 ...
- k近邻法(kNN)
<统计学习方法>(第二版)第3章 3 分类问题中的k近邻法 k近邻法不具有显式的学习过程. 3.1 算法(k近邻法) 根据给定的距离度量,在训练集\(T\)中找出与\(x\)最邻近的\(k ...
- 统计学习方法与Python实现(二)——k近邻法
统计学习方法与Python实现(二)——k近邻法 iwehdio的博客园:https://www.cnblogs.com/iwehdio/ 1.定义 k近邻法假设给定一个训练数据集,其中的实例类别已定 ...
- 《统计学习方法(李航)》讲义 第03章 k近邻法
k 近邻法(k-nearest neighbor,k-NN) 是一种基本分类与回归方法.本书只讨论分类问题中的k近邻法.k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类 ...
随机推荐
- 简单网络编程如何用python来实现
对于网络编程,通信模式是后台必备技能,先用最基础代码实现,理解一些 API 的含义,在深入学习. 总是有读者问过我关于 Python 后台开发相关,如果想走 Python 后台方向,对于 Python ...
- numpy basic sheatsheet
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.NumPy 通常与 SciPy(Scien ...
- tp5--数据库查询的常用操作
首先,我们要先明确,我们平时经常使用那些操作,我看了开发手册,主要是连贯操作比较多. 连贯操作有: field, order, limit, page, GROUP, HAVING, cache, 其 ...
- python学习10字典
'''''''''字典(Dict)是python语言的一个最大的特征1.定义:是可变的无序集合,以键值对为基本元素,可以存储各种数据类型2.表示:{} 列表:[] 元组 () 字符串 ‘’ “” ‘‘ ...
- diskpart 分区,挂载,和移除
list disk select disk 1 clean Create partition primary size=102400 active format quick list volume a ...
- Codeforces Round #632 (Div. 2) 题解
空山新雨后,天气晚来秋. 明月松间照,清泉石上流. 竹喧归浣女,莲动下渔舟. 随意春芳歇,王孙自可留.--王维 A. Little Artem 网址:https://codeforces.com/co ...
- QT踩坑记录1-Q_OBJECT编译问题
QT踩坑记录1-Q_OBJECT编译问题 QTC++Bugs 错误输出 Q_OBJECT 宏错误的地方会编译出现这样的错误, 无法找到.... 由于自己不想再看到这个错误, 此处 复制自 参考连接1, ...
- Android程序中Acticity间传递数据
在Android开发过程中,在不同的Acitivity之间传递数据的情况是非常常见的.我花费了一点时间来总结Acitivity之间的数据传递,记录下来. 1.简单传递键值对 这种传递方式非常简单,只需 ...
- Silverlight Tools Beta2更新了中文语言支持
1,似乎是微软偷偷摸摸更新的......刚才无意间发现,已经下载安装并测试,已在中文版的VS2008安装成功.注意下载页面的安装说明: http://www.microsoft.com/downloa ...
- 交换机上的MAC地址表
拓扑图: 1.首先在R1上的配置: R1(config)#int R1(config)#interface g R1(config)#interface gigabitEthernet 0/0 R1( ...