sklearn中实现随机梯度下降法(多元线性回归)
sklearn中实现随机梯度下降法
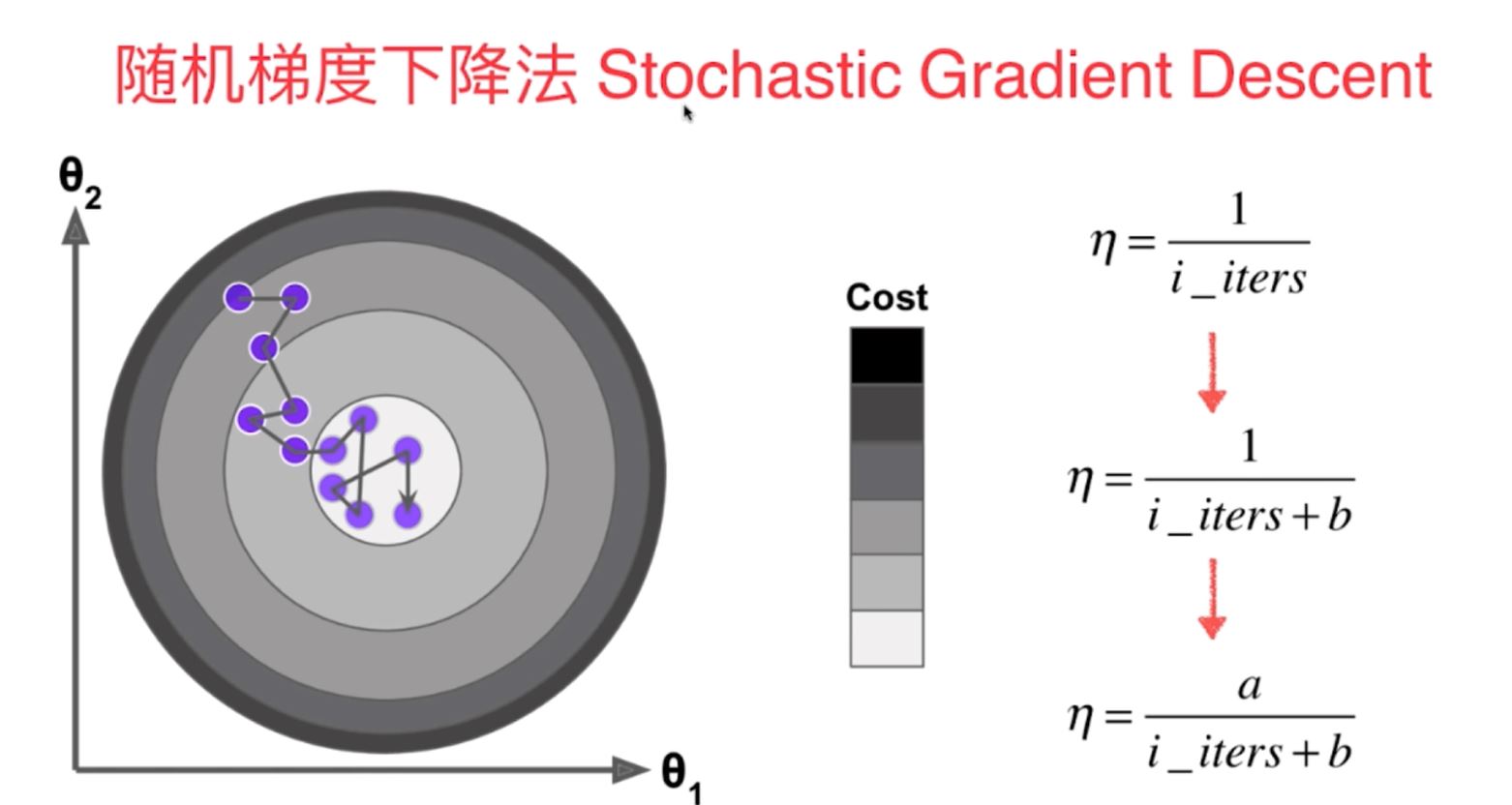
随机梯度下降法是一种根据模拟退火的原理对损失函数进行最小化的一种计算方式,在sklearn中主要用于多元线性回归算法中,是一种比较高效的最优化方法,其中的梯度下降系数(即学习率eta)随着遍历过程的进行在不断地减小。另外,在运用随机梯度下降法之前需要利用sklearn的StandardScaler将数据进行标准化。

#sklearn中实现随机梯度下降多元线性回归
#1-1导入相应的数据模块
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
#1-2导入相应的基础训练数据集
x=np.random.random(size=1000)
y=x*3.0+4+np.random.normal(size=1000)
x=x.reshape(-1,1)
from sklearn import datasets
d=datasets.load_boston()
x=d.data[d.target<50]
y=d.target[d.target<50]
from sklearn.model_selection import train_test_split
x_train1,x_test1,y_train1,y_test1=train_test_split(x,y,random_state=1)
#1-3进行数据的标准化
from sklearn.preprocessing import StandardScaler
stand1=StandardScaler()
stand1.fit(x_train1)
x_train_standard=stand1.transform(x_train1)
x_test_standard=stand1.transform(x_test1)
#1-4导入随机梯度下降法的多元线性回归算法进行数据的训练和预测
from sklearn.linear_model import SGDRegressor
sgd1=SGDRegressor()
sgd1.fit(x_train_standard,y_train1)
print(sgd1.coef_)
print(sgd1.intercept_)
print(sgd1.score(x_test_standard,y_test1))
sgd2=SGDRegressor()
sgd2.fit(x_train1,y_train1)
print(sgd2.coef_)
print(sgd2.intercept_)
print(sgd2.score(x_test1,y_test1)) 注解:对于多元回归的随机梯度下降法需要对数据进行向量化和标准化
sklearn中实现随机梯度下降法(多元线性回归)的更多相关文章
- 机器学习---用python实现最小二乘线性回归算法并用随机梯度下降法求解 (Machine Learning Least Squares Linear Regression Application SGD)
在<机器学习---线性回归(Machine Learning Linear Regression)>一文中,我们主要介绍了最小二乘线性回归算法以及简单地介绍了梯度下降法.现在,让我们来实践 ...
- 线性回归(最小二乘法、批量梯度下降法、随机梯度下降法、局部加权线性回归) C++
We turn next to the task of finding a weight vector w which minimizes the chosen function E(w). Beca ...
- 一种利用 Cumulative Penalty 训练 L1 正则 Log-linear 模型的随机梯度下降法
Log-Linear 模型(也叫做最大熵模型)是 NLP 领域中使用最为广泛的模型之一,其训练常采用最大似然准则,且为防止过拟合,往往在目标函数中加入(可以产生稀疏性的) L1 正则.但对于这种带 L ...
- Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法.其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动.通过柯 ...
- 谷歌机器学习速成课程---降低损失 (Reducing Loss):随机梯度下降法
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数.到目前为止,我们一直假定批量是指整个数据集.就 Google 的规模而言,数据集通常包含数十亿甚至数千亿个样本.此外,Google 数据集 ...
- 1. 批量梯度下降法BGD 2. 随机梯度下降法SGD 3. 小批量梯度下降法MBGD
排版也是醉了见原文:http://www.cnblogs.com/maybe2030/p/5089753.html 在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练.其实,常用的梯度 ...
- 随机梯度下降法(Stochastic gradient descent, SGD)
BGD(Batch gradient descent)批量梯度下降法:每次迭代使用所有的样本(样本量小) Mold 一直在更新 SGD(Stochastic gradientdescent)随机 ...
- Stochastic Gradient Descent 随机梯度下降法-R实现
随机梯度下降法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 批量梯度下降法在权值更新前对所有样本汇总 ...
- sklearn中的随机森林
阅读了Python的sklearn包中随机森林的代码实现,做了一些笔记. sklearn中的随机森林是基于RandomForestClassifier类实现的,它的原型是 class RandomFo ...
随机推荐
- Cisco Umbrella WLAN
Cisco Umbrella WLAN在域名系统(DNS)级别提供云交付网络安全服务,可自动检测已知和紧急威胁. 此功能允许您在实际恶意攻击之前阻止托管恶意软件,僵尸网络和网络钓鱼的站点. Cisco ...
- OPENTSDB: Request failed: Internal Server Error net.opentsdb.core.IllegalDataException
今天Opentsdb补传历史数据的时候,出现了如下的错误: Request failed: Internal Server Error net.opentsdb.core.IllegalDataExc ...
- JavaScript判断两个对象内容是否相等
ES6中有一个方法判断两个对象是否相等,这个方法判断是两个对象引用地址是否一致 let obj1= { a: 1 } let obj2 = { a: 1 } console.log(Object.is ...
- 重新理解业务里程碑----HHR计划----以太一堂第二课
---- 理解业务背后的逻辑,抓住创业重点. 第一课:开始学习 1,FA : financial advisor.财务顾问. 2,本节课的目的:抓住创业的重点. 3,预热思考题: (1) 如果把你的整 ...
- bootstrap帮助文档
概览 深入了解 Bootstrap 底层结构的关键部分,包括我们让 web 开发变得更好.更快.更强壮的最佳实践. HTML5 文档类型 Bootstrap 使用到的某些 HTML 元素和 CSS 属 ...
- 使用pandas读取excel
使用pandas读取excel Excel是微软的经典之作,在这里我们介绍使用Python的pandas数据分析包来解决此问题. pd.read_excel(io, sheet_name = 0, h ...
- P1017进制转化
P1017进制转化 也不知道为啥,这么简单的题困扰了我这么长时间 #include<cstdio> using namespace std; int m; //被除数= 除数*商 + 余数 ...
- WPS 2019文档编辑 技巧
wps2019文档怎么设置粘贴时自动匹配当前的格式: 菜单栏 文件 -- 选项 -- 编辑 -- 默认粘贴方式 设置为 匹配当前格式. 在编辑文档左侧或右侧显示/隐藏 目录/书签: 视图 -- 导航窗 ...
- 3_03_MSSQL课程_Ado.Net_登录复习和ExcuteScalar
SQL注入 ->登陆窗体破解 ->配置文件 ->首先在 app.Config文件中添加 节点,如下: <connectionStrings> <add name=& ...
- Markdown 语法使用
Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式.Markdown的语法简洁明了.学习容易,而且功能比纯文本更强,被广泛的应用在博客写 ...