sklearn中实现随机梯度下降法(多元线性回归)
sklearn中实现随机梯度下降法
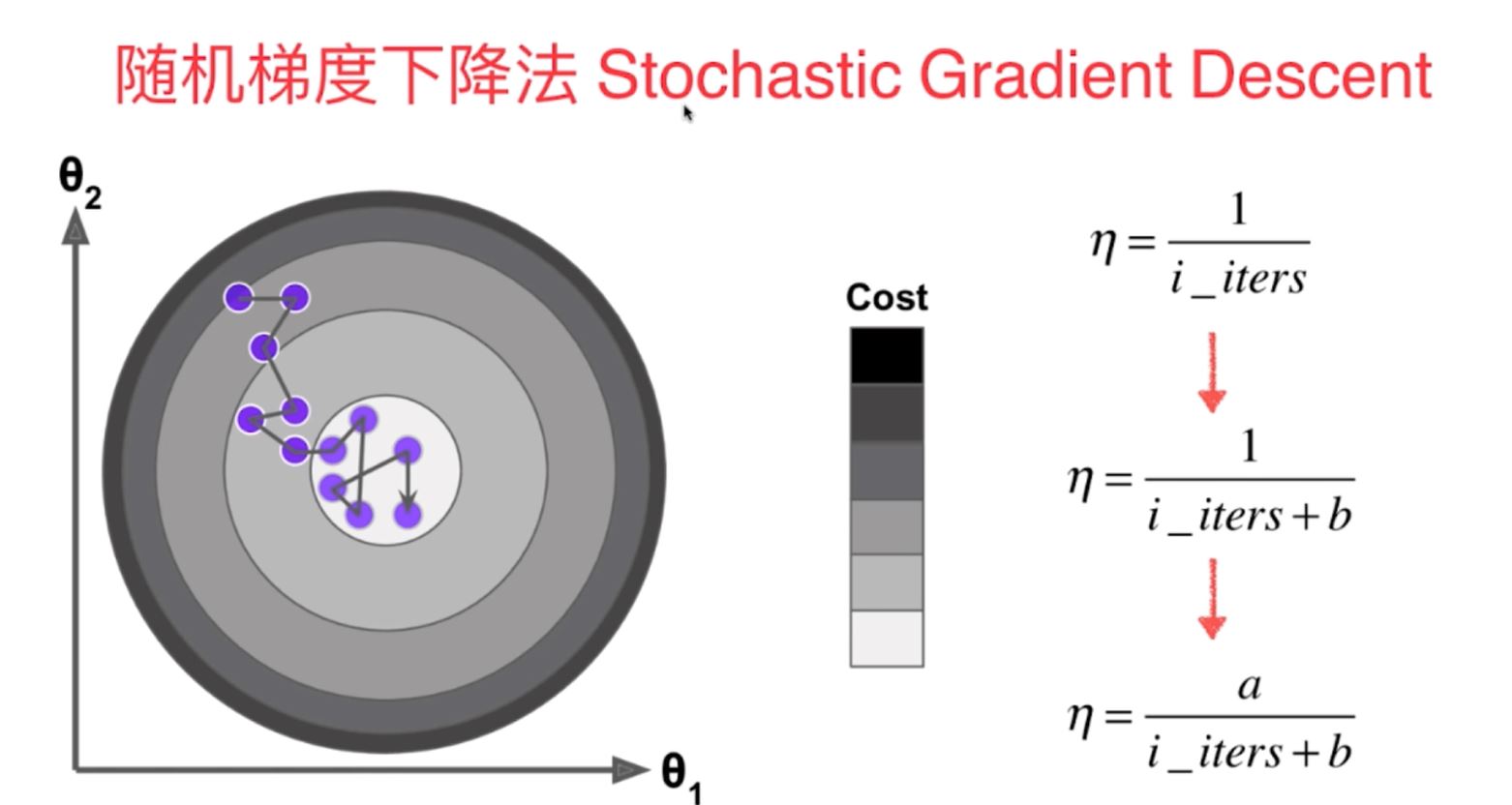
随机梯度下降法是一种根据模拟退火的原理对损失函数进行最小化的一种计算方式,在sklearn中主要用于多元线性回归算法中,是一种比较高效的最优化方法,其中的梯度下降系数(即学习率eta)随着遍历过程的进行在不断地减小。另外,在运用随机梯度下降法之前需要利用sklearn的StandardScaler将数据进行标准化。

#sklearn中实现随机梯度下降多元线性回归
#1-1导入相应的数据模块
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
#1-2导入相应的基础训练数据集
x=np.random.random(size=1000)
y=x*3.0+4+np.random.normal(size=1000)
x=x.reshape(-1,1)
from sklearn import datasets
d=datasets.load_boston()
x=d.data[d.target<50]
y=d.target[d.target<50]
from sklearn.model_selection import train_test_split
x_train1,x_test1,y_train1,y_test1=train_test_split(x,y,random_state=1)
#1-3进行数据的标准化
from sklearn.preprocessing import StandardScaler
stand1=StandardScaler()
stand1.fit(x_train1)
x_train_standard=stand1.transform(x_train1)
x_test_standard=stand1.transform(x_test1)
#1-4导入随机梯度下降法的多元线性回归算法进行数据的训练和预测
from sklearn.linear_model import SGDRegressor
sgd1=SGDRegressor()
sgd1.fit(x_train_standard,y_train1)
print(sgd1.coef_)
print(sgd1.intercept_)
print(sgd1.score(x_test_standard,y_test1))
sgd2=SGDRegressor()
sgd2.fit(x_train1,y_train1)
print(sgd2.coef_)
print(sgd2.intercept_)
print(sgd2.score(x_test1,y_test1)) 注解:对于多元回归的随机梯度下降法需要对数据进行向量化和标准化
sklearn中实现随机梯度下降法(多元线性回归)的更多相关文章
- 机器学习---用python实现最小二乘线性回归算法并用随机梯度下降法求解 (Machine Learning Least Squares Linear Regression Application SGD)
在<机器学习---线性回归(Machine Learning Linear Regression)>一文中,我们主要介绍了最小二乘线性回归算法以及简单地介绍了梯度下降法.现在,让我们来实践 ...
- 线性回归(最小二乘法、批量梯度下降法、随机梯度下降法、局部加权线性回归) C++
We turn next to the task of finding a weight vector w which minimizes the chosen function E(w). Beca ...
- 一种利用 Cumulative Penalty 训练 L1 正则 Log-linear 模型的随机梯度下降法
Log-Linear 模型(也叫做最大熵模型)是 NLP 领域中使用最为广泛的模型之一,其训练常采用最大似然准则,且为防止过拟合,往往在目标函数中加入(可以产生稀疏性的) L1 正则.但对于这种带 L ...
- Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法.其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动.通过柯 ...
- 谷歌机器学习速成课程---降低损失 (Reducing Loss):随机梯度下降法
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数.到目前为止,我们一直假定批量是指整个数据集.就 Google 的规模而言,数据集通常包含数十亿甚至数千亿个样本.此外,Google 数据集 ...
- 1. 批量梯度下降法BGD 2. 随机梯度下降法SGD 3. 小批量梯度下降法MBGD
排版也是醉了见原文:http://www.cnblogs.com/maybe2030/p/5089753.html 在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练.其实,常用的梯度 ...
- 随机梯度下降法(Stochastic gradient descent, SGD)
BGD(Batch gradient descent)批量梯度下降法:每次迭代使用所有的样本(样本量小) Mold 一直在更新 SGD(Stochastic gradientdescent)随机 ...
- Stochastic Gradient Descent 随机梯度下降法-R实现
随机梯度下降法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 批量梯度下降法在权值更新前对所有样本汇总 ...
- sklearn中的随机森林
阅读了Python的sklearn包中随机森林的代码实现,做了一些笔记. sklearn中的随机森林是基于RandomForestClassifier类实现的,它的原型是 class RandomFo ...
随机推荐
- mybatis升级案例之CRUD操作
mybatis升级案例之CRUD操作 一.准备工作 1.新建maven工程,和入门案例一样 主要步骤如下,可参考mybatis入门实例 a.配置pom.xml文件 b.新建实例类User.DAO接口类 ...
- Git fork后如何同步源仓库更新
1. 设置源仓库的远程地址 >> git remote add [新地址名称] [源仓库远程地址] >> git remote add upstream https://git ...
- Python 使用pillow 操作图像
文档:https://pillow.readthedocs.io/en/stable/index.html 计算机图像基础 颜色和RGBA值 计算机程序通常将图像中的颜色表示为 RGBA 值.RGBA ...
- 简单描述MySQL常用引擎的特点及MySQL的逻辑架构
目录 表的分类数据库引擎? 首先得说说mysql的逻辑架构,它整体分为3层: 常用引擎: 补充知识点: 表的分类数据库引擎? 引擎是什么? 引擎就是一个系统最核心的部分,比如汽车的发动机,人的心脏 数 ...
- Java基础 -2.4
字符型char类型 在任何的编程语言之中,字符都可以与int进行互相转换,也就是这个字符中所描述的内容可以通过int获取其内容所在的系统编码 public class ddd { public sta ...
- 科普:为什么 String hashCode 方法选择数字31作为乘子
作者:coolblog 此文章转载自:https://segmentfault.com/a/1190000010799123 1. 背景 某天,我在写代码的时候,无意中点开了 String hashC ...
- kafka 高吞吐量的因素
1.顺序的方式存储数据: 2.批量发送: 3.零拷贝: 来源:咕泡学院
- 利用java反射调用类的的私有方法--转
原文:http://blog.csdn.net/woshinia/article/details/11766567 1,今天和一位朋友谈到父类私有方法的调用问题,本来以为利用反射很轻松就可以实现,因为 ...
- Uber为何会成为共享经济中全球市值最大的独角兽企业?
自5月10日登陆纽交所以来,Uber的股价就像过山车一般起起伏伏,让无数投资者痛并快乐着.不过在经过半个月时间的试探后,如今Uber的股价已经稳定在40美元左右.截至美国东部时间5月24日股市收盘,U ...
- Linux centosVMware Linux集群架构LVS DR模式搭建、keepalived + LVS
一.LVS DR模式搭建 三台机器 分发器,也叫调度器(简写为dir) davery :1.101 rs1 davery01:1.106 rs2 davery02:11.107 vip 133.200 ...