cs231n笔记:最优化
本节是cs231学习笔记:最优化,并介绍了梯度下降方法,然后应用到逻辑回归中
引言
在上一节线性分类器中提到,分类方法主要有两部分组成:1.基于参数的评分函数。能够将样本映射到类别的分值。2.损失函数。用来衡量预测标签和真是标签的一致性程度。这一节介绍第三个重要部分:最优化(optimization)。损失函数能让我们定量的评估得到的权重W的好坏,而最优化的目标就是找到一个W,使得损失函数最小。工作流程如下图:
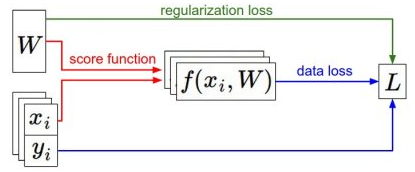
(x,y)是给定的数据集,W是权重矩阵,通过初始化得到。向前传递到评分函数中得到类别的评分值并存储在向量f中。损失函数计算评分函数值f与类标签y的差值,正则化损失只是一个关于权重的函数。在梯度下降过程中,我们计算权重的梯度,然后使用梯度更新权重。一旦理解了这三个部分的关系,我们可以用更加复杂的评分函数来代替线性映射,比如神经网络、甚至卷积神经网络等,而损失函数和优化过程这两部分则相对保持不变。
梯度下降
梯度下降的思想是:要寻找某函数的最值,最好的方法就是沿着函数的梯度方向寻找,移动量的大小称为步长。梯度下降的公式如下:
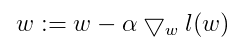
我们常常听说过梯度上升、梯度下降,那么两者的区别又是什么呢?其实这两者是一样的,只是公式中的减法变成加法,因此公式为:
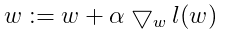
梯度上升是用来求函数的最大值,而梯度下降是用来求最小值。普通的梯度下降版本如下:
# 普通的梯度下降
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 进行梯度更新
其中的evaluate_gradient是用来计算梯度的,data是训练样本集,weights是权重,step_size是下降的步长。梯度下降方法对神经网络的损失函数优化中最常用的方法,核心思想就是一直沿着梯度方向走,直到结果不变为止。梯度下降每次更新权重W时都需要遍历整个数据集,当训练数据达到百万级别的时候,上面的方法将会十分的耗时,一种改进的方法是:
小批量数据梯度下降(Mini-batch gradient descent):这种方法一次仅用一个或一部分数据来更新权重,例如在目前最先进的卷及神经网络中,训练集有一百而是多万,一个小批量中包含256个样本。小批量梯度下降的版本:
# 普通的小批量数据梯度下降
while True:
data_batch = sample_training_data(data, 256) # 256个数据
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 参数更新
这种方法之所以效果不错,是因为训练集中存在相关的样本。要理解这一点,可以想想一种极端情况,在ILSVRC中,120W个图像是1000张不同的图片,每张复制1200份得到,对比这120W张图片的损失均值应该和这1000张子集损失值一样。实际数据集中,不会包含这么多重复图像,所以小批量梯度下降方法是对整个数据集梯度的一个近似。因此小批量梯度下降方法能够更快的收敛,并更加频繁的更新参数。
小批量数据梯度下降方法有一个极端情况,那就是小批量中只有1个数据样本,这种方法被称作随机梯度下降(SGD,Stochastic Gradient Descent)或者被成为在线(on-line)梯度下降,这种方法在实际操作中使用的并不多,因为使用向量化的代码计算包含100个样本的梯度效率要比计算100次1个样本梯度的效率高的多。但SGD常常被用来指代MGD,或者当看到“使用SGD”,我们就假定使用的是MGD。小批量数据集的大小是一个超参数,但是不需要通过交叉验证来调参,依赖存储器的大小。
实例
下面引用《机器学习实战》中对logistics regression求参数的例子来帮助理解梯度优化算法,下面是梯度上升代码:
def gradAscent(raw_data,label):
#转化为矩阵类型
train_X = np.mat(raw_data)
train_Y = np.mat(label).T
m,n = train_X.shape
weights = np.ones((n,1))
alpha = 0.001
for i in xrange(500):
h = sigmoid(train_X * weights)
error = (train_Y - h)
weights += alpha*train_X.T*error
return weights
其中for循环是整个数据集的迭代次数,weights是一个向量,长度为数据集维度的个数。需要注意的是h、error是一个列向量,元素的个数为数据集的大小。其中weights += alpha*train_X.T*error为逻辑回归损失函数梯度迭代公式。可以看出每次迭代都需要对整个数据集进行计算。下面给出随机梯度上升的代码,一次仅用一个样本来更新权重。
def stocGradAscent(train_X,train_Y):
train_X = np.array(train_X)
m,n = train_X.shape
alpha = 0.01
weights = np.ones(n)
for i in range(m):
h = sigmoid(sum(train_X[i] * weights))
error = int(train_Y[i]) - h
weights += alpha * error * train_X[i]
return weights
与上面的代码不同的是,for循环迭代的次数是数据集的大小,每次选取一个样本用来更新权重,其中的h和error不再是向量而是一个数值。
上面两个方法使用的学习率为0.01,学习率代表算法学习速度的快慢。学习率、迭代次数与损失函数的关系如下图:
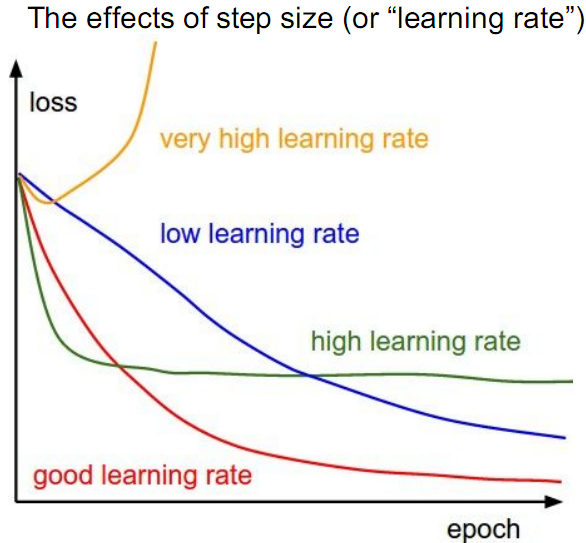
除了梯度下降(上升)算法之外,还有一些最小化损失函数的算法,这些算法更加的复杂和优越,通常也不需要人工选择学习率例如:共轭梯度(Conjugate Gradient)、局部优化法(Broyden Fletcher goldfard shann,BFGS)等等,这些方法等遇到了再来补充,有兴趣的可以自行查阅资料。(完)
cs231n笔记:最优化的更多相关文章
- 【cs231n】最优化笔记
): W = np.random.randn(10, 3073) * 0.0001 # generate random parameters loss = L(X_train, Y_train, W) ...
- cs231n笔记:线性分类器
cs231n线性分类器学习笔记,非完全翻译,根据自己的学习情况总结出的内容: 线性分类 本节介绍线性分类器,该方法可以自然延伸到神经网络和卷积神经网络中,这类方法主要有两部分组成,一个是评分函数(sc ...
- cs231n笔记(二) 最优化方法
回顾上一节中,介绍了图像分类任务中的两个要点: 假设函数.该函数将原始图像像素映射为分类评分值. 损失函数.该函数根据分类评分和训练集图像数据实际分类的一致性,衡量某个具体参数集的质量好坏. 现在介绍 ...
- cs231n笔记 (一) 线性分类器
Liner classifier 线性分类器用作图像分类主要有两部分组成:一个是假设函数, 它是原始图像数据到类别的映射.另一个是损失函数,该方法可转化为一个最优化问题,在最优化过程中,将通过更新假设 ...
- 【cs231n笔记】assignment1之KNN
k-Nearest Neighbor (kNN) 练习 这篇博文是对cs231n课程assignment1的第一个问题KNN算法的完成,参考了一些网上的博客,不具有什么创造性,以个人学习笔记为目的发布 ...
- 卷积神经网络经验-CS231n笔记
课程note中讲了一些工程经验,感觉很有用,记下来供自己以后查阅 相比于大的滤波器,小滤波器更受青睐.小滤波器参数更少.计算量更小.能够表达更多的特征,做反向传播时需要的内存更少. 通常不会考虑创建一 ...
- CS231n笔记列表
课程基础1:Numpy Tutorial 课程基础2:Scipy Matplotlib 1.1 图像分类和Nearest Neighbor分类器 1.2 k-Nearest Neighbor分类器 1 ...
- CS231n笔记 Lecture 5 Convolutional Neural Networks
一些ConvNets的应用 Face recognition 输入人脸,推测是谁 Video classfication Recognition 识别身体的部位, 医学图像, 星空, 标志牌, 鲸.. ...
- CS231n笔记 Lecture 4 Introduction to Neural Networks
这一讲主要介绍了神经网络,基本内容之前如果学习过Andrew的Machine learning应该也都有所了解了.不过这次听完这一讲后还是有了新的一些认识. 计算图 Computational gra ...
随机推荐
- android开发 兵器
spring for android andriod anotatons 按android原生的方式写代码,会导致冗余,代码丑陋,开发效率低下. 最近对项目代码进行一些梳理和改进.
- 多个radiobutton选定一个
asp.net中怎么判断其中一个radiobutton被选中后登录的是一个窗体,另一个被选中后登录的是另一个窗体. 页面设置两按钮的GroupName为同一组值: <asp:RadioButto ...
- 基于Jforum开源项目的论坛网站
基于Jforum开源项目的论坛网站 开发原因: 刚完成了以wordpress及其插件simple-press为基础的论坛网站,因为一直从事java方面开发, 所以尝试一下使用java开源项目Jforu ...
- Redis并发锁控制
为了防止用户在页面上重复点击或者同时发起多次请求,请求处理需要操作redis缓存,这个时候需要对并发边界进行并发锁控制,实现思路: 由于每个页面发起的请求带的token具备唯一性,可以将token作为 ...
- ADO.NET与ORM的比较:NHibernate实现CRUD(转)
原文地址 http://blog.csdn.net/zhoufoxcn/article/details/5402511 说明:个人感觉在Java领域大型开发都离不了ORM的身影,所谓的SSH就是Spr ...
- cookie 保存上次访问url方法
if (Session[Enums.UserInfoSeesion] == null) { HttpCookie cookie = Request.Cookies[Enums.UserLastAcce ...
- 关于mongoldb 启动时显示 add already in use
1 .不要在国内网上查找 浪费时间 2. stack over flow 是个不错的选择 进入正题. 终端输入: ps wuax | grep mongo 会看到: 随后:kill 447
- SQL高级查询——50句查询(含答案) ---参考别人的,感觉很好就记录下来留着自己看。
--一个题目涉及到的50个Sql语句 --(下面表的结构以给出,自己在数据库中建立表.并且添加相应的数据,数据要全面些. 其中Student表中,SId为学生的ID) ---------------- ...
- Linux下使用NMON监控、分析系统性能
一.下载nmon. 根据CPU的类型选择下载相应的版本:http://nmon.sourceforge.net/pmwiki.php?n=Site.Downloadwget http://source ...
- Python学习路程day20
本节内容: 项目:开发一个简单的BBS论坛 需求: 整体参考“抽屉新热榜” + “虎嗅网” 实现不同论坛版块 帖子列表展示 帖子评论数.点赞数展示 在线用户展示 允许登录用户发贴.评论.点赞 允许上传 ...