(数据科学学习手札48)Scala中的函数式编程
一、简介
Scala作为一门函数式编程与面向对象完美结合的语言,函数式编程部分也有其独到之处,本文就将针对Scala中关于函数式编程的一些常用基本内容进行介绍;
二、在Scala中定义函数
2.1 定义函数
和Python相似,Scala中函数的定义和方法(类中的函数称为方法)都以关键词def开始,后面再跟随函数名、函数参数以及参数类型、返回值类型以及函数执行体部分,这是Scala中最常规的函数的定义方法,下面是一个简单的例子:
object main{
def main(args: Array[String]): Unit = {
//定义函数
def plus(a:Double,b:Double):Double={
a + b
}
var result:Double = 0
//调用函数计算结果
result = plus(5,4)
println(result)
}
}
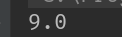
上例中,我们以def关键字开头,定义了一个函数名为plus,传入参数为Double型的a,Double型的b,传出类型为Double型的函数用于计算两个数字之和,运行上述代码,得到对应的结果:
我们也可以定义不含输入参数和返回值的函数:
object main{
def main(args: Array[String]): Unit = {
//定义函数
def demo():Unit={
println("这是个演示函数")
}
demo()
}
}
这时返回值的类型就变为Unit,即无类型,运行结果如下:

当函数执行体部分只有一条语句时,可以直接省略花括号来定义函数,如下面这个例子:
object main{
def compare(a:Double,b:Double)=if(a > b) a else b
def main(args: Array[String]): Unit = {
println("更大的数是"+compare(3,4))
}
}
更特别的,在Scala中我们可以对类中的方法进行条件限制,即先决条件,使用在类中定义方法同等层次下,定义require(表达式内容),来对使用到require中表达式限制的参数进行限制,只有满足条件才会运行对应函数,下面是一个简单的例子:
object main{
class Demo(a:Double,b:Double){
require(a != b)
def compare(): Double ={
if(a > b) a else b
}
}
def main(args: Array[String]): Unit = {
//满足条件地调用
val demo1 = new Demo(a=4,b=3)
println(demo1.compare())
//不满足条件的调用
try{
val demo2 = new Demo(a=4,b=4)
println(demo2.compare())
}catch {
case ex:Exception => println(ex)
}
}
}
可以看出,第一次调用Demo中的compare函数,传入的参数满足 a!=b,因此函数顺利得到执行,而第二次调用时未满足条件,使得程序报错,被错误处理机制所捕获,运行结果如下;

2.2 本地函数
有时候为了函数名之间不发生重名的冲突,我们会在Scala中使用本地函数的机制,顾名思义,本地函数指的是只可以在某部分作用域内调用的函数,如下面这个简单的例子:
object main{
def main(args: Array[String]): Unit = {
def X(): Unit ={
//在常规函数内部定义本地函数
def Y(): Unit ={
println("这是本地函数Y")
}
//在常规函数内部调用本地函数
Y()
}
def Y(): Unit ={
println("这是非本地函数Y")
}
//分别调用X,Y
X()
Y()
}
}
如上,我们定义了两个函数名均为Y的函数,第一个Y是函数X内部的本地函数,第二个Y是常规函数,当我们在常规函数X中调用其拥有的本地函数Y时,便不会引起与外部同名Y函数之间的冲突,运行结果如下:

2.3 匿名函数
在Scala中也有匿名函数的机制,使得我们只需要书写简单的语句就可以在程序中嵌入需要实现的函数功能,下面是一个简单的例子:
object main{
def main(args: Array[String]): Unit = {
//在List的定义过程中使用匿名函数和map方法来转换所有值
var listDemo = List(1,2,3).map((x:Int) => x+1)
println(listDemo)
}
}
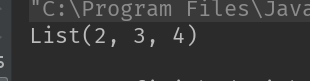
在上例中,我们在一个List的定义过程中,利用map方法,将匿名函数 (x:Int) => x+1 广播到List中所有元素之上,运行结果如下:
在Scala中,我们可以将匿名函数作为值进行传递,这称为函数字面量,在函数编译函数字面量的时候才将其实例化为函数值,有些类似类,下面是一个简单的例子:
object main{
def main(args: Array[String]): Unit = {
//定义一个匿名函数并将它传递给变量MyFunction
var MyFunction = (x:Int,n:Int) => {
var result = x
for(i <- 1 until n){
result *= x
}
result
}
//调用保存匿名函数字面量的变量
var TestValue = MyFunction(2,10)
println(TestValue)
}
}
在上例中,我们定义了一个用于求一个整数若干次方的函数,并将其传递给变量MyFunction,接着调用MyFunction来传入计算结果,作为新变量的值。
2.4 高阶函数
高阶函数是Scala的函数式编程中十分有趣的一部分,它的基本特点是将其他函数作为当前函数的参数来传入,下面是一个简单的关于高阶函数部分特性的例子:
object main{
def main(args: Array[String]): Unit = {
//定义函数字面量并赋值
var func1 = (x:Int, n:Int) => {
var result = x
for(i <- 1 until n){
result *= x
}
result
}
//定义高阶函数
def func2(MyFunction:(Int,Int)=>Int,x:Int,n:Int): Int ={
MyFunction(x,n)
}
//调用高阶函数,传入函数字面量并打印结果
println(func2(func1,2,10))
}
}
在上例中我们定义了函数字面量并传递给func1,接着定义了函数func2,设置func2的第一个传入参数为接受两个Int型输入,输出Int型数据的函数,设置func2的2、3个参数为Int型,以对应第一个参数中的函数需要传入的参数,接着我们将函数字面量func1、2,、10作为func2的参数传入func1中,得到了对应的结果。
以上就是Scala中函数式编程的一些基本内容,如有笔误,望指出。
(数据科学学习手札48)Scala中的函数式编程的更多相关文章
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
随机推荐
- recycle bin tip
if you have a question about recycle bin that can look the follow link; http://www.dba-oracle.com/t_ ...
- 沉淀再出发:ElasticSearch的中文分词器ik
沉淀再出发:ElasticSearch的中文分词器ik 一.前言 为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了 ...
- 【心得体会】我考完MOS我明白了…
[心得体会]我考完MOS我明白了… 原创 2017-11-10 MSP-李桑榆 MSPrecious成长荟 MOS备考 这篇文章写给还没有考或者准备考MOS的同学 网上有很多介绍MOS考试的 http ...
- 【RabbitMQ】4、三种Exchange模式——订阅、路由、通配符模式
前两篇博客介绍了两种队列模式,这篇博客介绍订阅.路由和通配符模式,之所以放在一起介绍,是因为这三种模式都是用了Exchange交换机,消息没有直接发送到队列,而是发送到了交换机,经过队列绑定交换机到达 ...
- 组合数取模&&Lucas定理题集
题集链接: https://cn.vjudge.net/contest/231988 解题之前请先了解组合数取模和Lucas定理 A : FZU-2020 输出组合数C(n, m) mod p (1 ...
- The Struts dispatcher cannot be found. This is usually caused by using Struts
对于struts2中的问题: org.apache.jasper.JasperException: The Struts dispatcher cannot be found. This is usu ...
- kubernetes 入门学习
kubernetes 学习 kubernetes 简介 Kubernetes这个名字源自希腊语,意思是"舵手",也是"管理者","治理者"等 ...
- Tomcat的免安装配置
Tomcat免安装配置 以下配置说明全部针对免安装版本 基于tomcat的安装目录和运行目录是可以不同的,本文都会进行说明 首先简单介绍一下tomcat的目录结构,一般情况下,tomcat包括以下子目 ...
- TP框架---Model模型层---做模型对象
TP框架----Model模型层---------------做模型对象 Model模型层是用来做什么的呢???? 主要是用来做操作数据库访问的. 也就说明TP框架自带了一种访问数据库的方式,使用的是 ...
- chrome下载离线安装包的方法
https://www.google.com/chrome/browser/desktop/index.html?system=true&standalone=1,一般默认下载稳定版,如果需要 ...