【Spark】编程实战之模拟SparkRPC原理实现自定义RPC
1. 什么是RPC
RPC(Remote Procedure Call)远程过程调用。在Hadoop和Spark中都使用了PRC,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。简单来说,就是有A、B两台机器,A机器可以调用B机器上的程序。
2. Spark 的RPC
Master和Worker的启动流程:
(1) 启动Master,会启动一个定时器,定时检查超时的Worker,并移除超时Worker信息。
(2) 启动Worker,向Master发送注册信息。
(3) Master收到Worker发来的注册信息后,保存到内存中,并返回一个响应信息,这个信息就是自己的masterUrl。
(4) Worker接收到Master发来的响应信息(masterUrl)之后,保存到内存中,并开启一个定时器,定时向Master发送心跳信息。
(5) Master 不断的接收Worker发来的心跳信息,并将每个Worker的最后一次心跳时间为当前接收到心跳信息的时间。
流程如下图。

3. 编程实战
3.1 项目代码(Scala语言)
WorkInfo.scala
package com.nova.rpc
/**
* @author Supernova
* @date 2018/06/15
*/
class WorkerInfo(val id: String, val host: String, val port: Int,val memory: Int, val cores: Int) {
// 记录最后一次心跳时间
var lastHeartbeatTime: Long = _
}
RemoteMsg.scala
package com.nova.rpc /**
* @author Supernova
* @date 2018/06/15
*/
trait RemoteMsg extends Serializable{ } // Master 向自己发送检查超时Worker的信息
case object CheckTimeOutWorker // Worker向Master发送的注册信息
case class RegisterWorker(id: String, host: String,port: Int, memory: Int, cores: Int) extends RemoteMsg // Master向Worker发送的响应信息
case class RegisteredWorker(masterUrl: String) extends RemoteMsg // Worker向Master发送的心跳信息
case class Heartbeat(workerId: String) extends RemoteMsg // Worker向自己发送的要执行发送心跳信息的消息
case object SendHeartbeat
Master.scala
package com.nova.rpc
import akka.actor.{Actor, ActorSystem, Props}
import com.typesafe.config.{Config, ConfigFactory}
import scala.collection.mutable
import scala.concurrent.duration._
/**
* @author Supernova
* @date 2018/06/15
*/
class Master(val masterHost: String, val masterPort: Int) extends Actor{
// 用来存储Worker的注册信息: <workerId, WorkerInfo>
val idToWorker = new mutable.HashMap[String, WorkerInfo]()
// 用来存储Worker的信息,必须使用可变的HashSet
val workers = new mutable.HashSet[WorkerInfo]()
// Worker的超时时间间隔
val checkInterval: Long = 15000
/**
* 重写生命周期preStart方法
* 作用:当Master启动时,开启定时器,定时检查超时Worker
*/
override def preStart(): Unit = {
// 启动定时器,定时检查超时的Worker
import context.dispatcher
context.system.scheduler.schedule(0 millis,checkInterval millis, self,CheckTimeOutWorker)
}
/**
* 重写生命周期receive方法
* 作用:
* 1.接收Worker发来的注册信息
* 2.不断接收Worker发来的心跳信息,并更新最后一次心跳时间
* 3.过滤出超时的Worker并移除
*/
override def receive = {
// 接收Worker给Master发送过来的注册信息
case RegisterWorker(id, host, port, memory, cores) => {
//判断改Worker是否已经注册过,已注册的不执行任何操作,未注册的将进行注册
if (!idToWorker.contains(id)) {
val workerInfo = new WorkerInfo(id, host, port, memory, cores)
idToWorker += (id -> workerInfo)
workers += workerInfo
println("一个新的Worker注册成功")
//向Worker发送响应信息,将masterUrl返回
sender ! RegisteredWorker(s"akka.tcp://${Master.MASTER_SYSTEM}" +
s"@${masterHost}:${masterPort}/user/${Master.MASTER_ACTOR}")
}
}
//接收Worker发来的心跳信息
case Heartbeat(workerId) => {
// 通过传输过来的workerId获取对应的WorkerInfo
val workerInfo = idToWorker(workerId)
// 获取当前时间
val currentTime = System.currentTimeMillis()
// 更新最后一次心跳时间
workerInfo.lastHeartbeatTime = currentTime
}
//检查超时Worker并移除
case CheckTimeOutWorker => {
val currentTime = System.currentTimeMillis()
// 把超时的Worker过滤出来
val toRemove: mutable.HashSet[WorkerInfo] =
workers.filter(w => currentTime - w.lastHeartbeatTime > checkInterval)
// 将超时的Worker移除
toRemove.foreach(deadWorker => {
idToWorker -= deadWorker.id
workers -= deadWorker
})
}
println(s"当前Worker的数量: ${workers.size}")
}
}
object Master{
val MASTER_SYSTEM = "MasterSystem"
val MASTER_ACTOR = "Master"
def main(args: Array[String]): Unit = {
val host = args(0) // 通过main方法参数制定master主机名
val port = args(1).toInt //通过main方法参数指定Master的端口号
//akka配置信息
val configStr: String =
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin
// 配置创建Actor需要的配置信息
val config: Config = ConfigFactory.parseString(configStr)
// 创建ActorSystem
val actorSystem: ActorSystem = ActorSystem(MASTER_SYSTEM, config)
// 用actorSystem实例创建Actor
actorSystem.actorOf(Props(new Master(host, port)), MASTER_ACTOR)
actorSystem.awaitTermination()
}
}
Worker.scala
package com.nova.rpc import java.util.UUID
import akka.actor.{Actor, ActorSelection, ActorSystem, Props}
import com.typesafe.config.{Config, ConfigFactory} import scala.concurrent.duration._
/**
* @author Supernova
* @date 2018/06/15
*/
class Worker(val host: String, val port: Int, val masterHost: String,val masterPort: Int, val memory: Int, val cores: Int) extends Actor{ // 生成一个Worker ID
val workerId: String = UUID.randomUUID().toString // 用来存储MasterUrl
var masterUrl: String = _ // 心跳时间间隔
val heartbeat_interval: Long = 10000 // Master的Actor
var master: ActorSelection = _ /**
* 生命周期preStart方法
* 作用:当启动Worker时,向master发送注册信息
*/
override def preStart(): Unit = {
// 获取Master的Actor
master = context.actorSelection(s"akka.tcp://${Master.MASTER_SYSTEM}" +
s"@${masterHost}:${masterPort}/user/${Master.MASTER_ACTOR}")
master ! RegisterWorker(workerId, host, port, memory, cores)
} /**
* 生命周期receive方法
* 作用:
* 定时向Master发送心跳信息
*/
override def receive: Receive = {
// Worker接收到Master发送过来的注册成功的信息(masterUrl)
case RegisteredWorker(masterUrl) => {
this.masterUrl = masterUrl
// 启动一个定时器, 定时的给Master发送心跳
import context.dispatcher
context.system.scheduler.schedule(
0 millis, heartbeat_interval millis, self, SendHeartbeat)
}
case SendHeartbeat => {
// 向Master发送心跳信息
master ! Heartbeat(workerId)
}
} } object Worker{
val WORKER_SYSTEM = "WorkerSystem"
val WORKER_ACTOR = "Worker" def main(args: Array[String]): Unit = {
/**
* 通过main方法参数指定相应的
* worker主机名、端口号,master主机名、端口号,使用的内存和核数
*/
val host = args(0)
val port = args(1).toInt
val masterHost = args(2)
val masterPort = args(3).toInt
val memory = args(4).toInt
val cores = args(5).toInt //akka配置信息
val configStr =
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname = "$host"
|akka.remote.netty.tcp.port = "$port"
""".stripMargin // 配置创建Actor需要的配置信息
val config: Config = ConfigFactory.parseString(configStr) // 创建ActorSystem
val actorSystem: ActorSystem = ActorSystem(WORKER_SYSTEM, config) // 用actorSystem实例创建Actor
actorSystem.actorOf(Props(new Worker(
host, port, masterHost, masterPort, memory, cores)), WORKER_ACTOR) actorSystem.awaitTermination()
}
}
3.2 测试运行
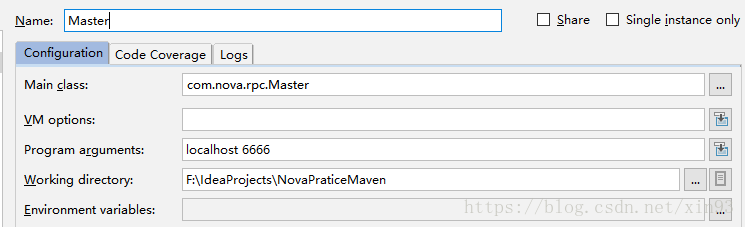
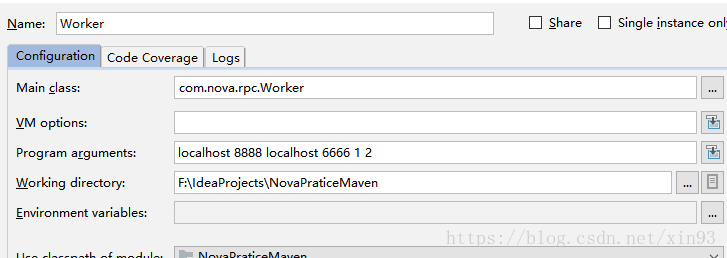
由于Master 和Worker的运行都是使用main方法参数传入相应的主机名端口等参数,所以在运行前要在IDEA中的Edit Configurations 窗口中传入相应的参数。在本次测试中,我指定的参数如图:
【Master端】
【Worker端】
【运行结果】
1. 先运行Master,可以看到一旦运行Master,就启动了定时器检查超时Worker,因为还没有Worker进行注册,所以结果一直为0

2. 启动Worker

3. 启动Worker后,再看Master的窗口可以发现Worker注册成功,并且数量为1

4. 关闭Worker,此时Worker已经宕掉了,可以发现Master窗口会收到一条警告信息,并且Master在定时检查超时Worker的时候移除了过期未收到心跳的Worker

【Spark】编程实战之模拟SparkRPC原理实现自定义RPC的更多相关文章
- Spark调研笔记第6篇 - Spark编程实战FAQ
本文主要记录我使用Spark以来遇到的一些典型问题及其解决的方法,希望对遇到相同问题的同学们有所帮助. 1. Spark环境或配置相关 Q: Sparkclient配置文件spark-defaults ...
- 《java并发编程实战》读书笔记11--构建自定义的同步工具,条件队列,Condition,AQS
第14章 构建自定义的同步工具 本章将介绍实现状态依赖性的各种选择,以及在使用平台提供的状态依赖机制时需要遵守的各项规则. 14.1 状态依赖性的管理 对于并发对象上依赖状态的方法,虽然有时候在前提条 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- 超级干货:动态防御WAF技术原理及编程实战!
本文带给大家的内容是动态防御WAF的技术原理及编程实战. 将通过介绍ShareWAF的核心技术点,向大家展示动态防御的优势.实现思路,并以编程实战的方式向大家展示如何在WAF产品开发过程中应用动态防御 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 . 安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语 ...
- Scala实战高手****第17课:Scala并发编程实战及Spark源码阅读
package com.wanji.scala.test import javax.swing.text.AbstractDocument.Content import scala.actors.Ac ...
- 【Java编程实战】Metasploit_Java后门运行原理分析以及实现源码级免杀与JRE精简化
QQ:3496925334 文章作者:MG1937 CNBLOG博客ID:ALDYS4 未经许可,禁止转载 某日午睡,迷迷糊糊梦到Metasploit里有个Java平台的远控载荷,梦醒后,打开虚拟机, ...
- 大数据学习day20-----spark03-----RDD编程实战案例(1 计算订单分类成交金额,2 将订单信息关联分类信息,并将这些数据存入Hbase中,3 使用Spark读取日志文件,根据Ip地址,查询地址对应的位置信息
1 RDD编程实战案例一 数据样例 字段说明: 其中cid中1代表手机,2代表家具,3代表服装 1.1 计算订单分类成交金额 需求:在给定的订单数据,根据订单的分类ID进行聚合,然后管理订单分类名称, ...
随机推荐
- js 三元表达式的写法
句式一. if(a) do_a elseif(b) do_b else do_c 转化为: =>a ? do_a : b ?do_b : do_c 句式二. if(a) do_a 转化为: =& ...
- C# 递归函数详细介绍及使用方法
什么是递归函数/方法? 任何一个方法既可以调用其他方法也可以调用自己,而当这个方法调用自己时,我们就叫它递归函数或递归方法. 通常递归有两个特点: 1. 递归方法一直会调用自己直到某些条件被满足 2. ...
- [翻译] JTNumberScrollAnimatedView
JTNumberScrollAnimatedView 本人视频教程系类 iOS中CALayer的使用 效果: Use JTNumberScrollAnimatedView for have a n ...
- Excel操作之级联菜单
设置级联菜单主要用的是excel的数据验证功能.下面以简单的设置城市选择框为例: 1.准备好数据 2.给所有省份起个名称(例如:省份),然后同样方法给每个省份所对应的城市以其省份命名,(例如:南京.苏 ...
- Sqoop操作集合
1.在hive中建一个与mysql中一模一样的表 sqoop create-hive-table --connect jdbc:mysql://***.**.***.**:3306/数据库名称 --t ...
- 多变量线性回归 matlab
%multivariate_linear_regression data=load('data.txt'); x=data(:,1:2); y=data(:,3); m=length(x(:,1)); ...
- MVC中使用EF的技巧集(二)——分部验证
1.从数据库生成模型后,再次更新模型时,之前设置的验证规则会丢失. 解决方法:在Models文件夹中新建一个空白类,把它命名为shujuyanzh.cs(类名可以自定),然后把Models中自动生成的 ...
- python源码学习(一)——python的总体架构
python源码学习(一)——python的总体架构 学习环境: 系统:ubuntu 12.04 STLpython版本:2.7既然要学习python的源码,首先我们要在电脑上安装python并且下载 ...
- 利用describe( )中的count来检查数据是否缺省
#-*- coding: utf-8 -*- #在python的pandas库中,只需要读入数据,然后使用describe()函数就可以查看数据的基本情况 import pandas as pd in ...
- Django的视图流式响应机制
Django的视图流式响应机制 Django的响应类型:一次性响应和流式响应. 一次性响应,顾名思义,将响应内容一次性反馈给用户.HttpResponse类及子类和JsonResponse类属于一次性 ...