Google论文系列(2) MapReduce
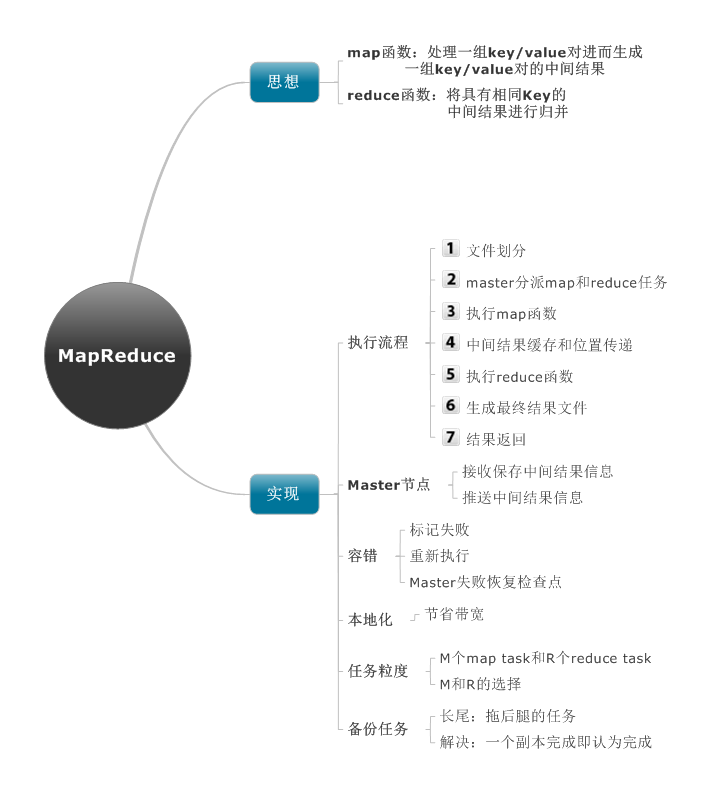
思想
map函数:处理一组key/value对进而生成一组key/value对的中间结果
reduce函数:将具有相同Key的中间结果进行归并
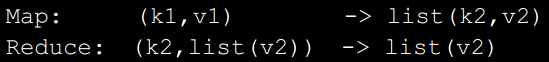
实现
环境
普通带宽,上千台机器(失败变得正常),廉价硬盘,调度系统。
执行过程
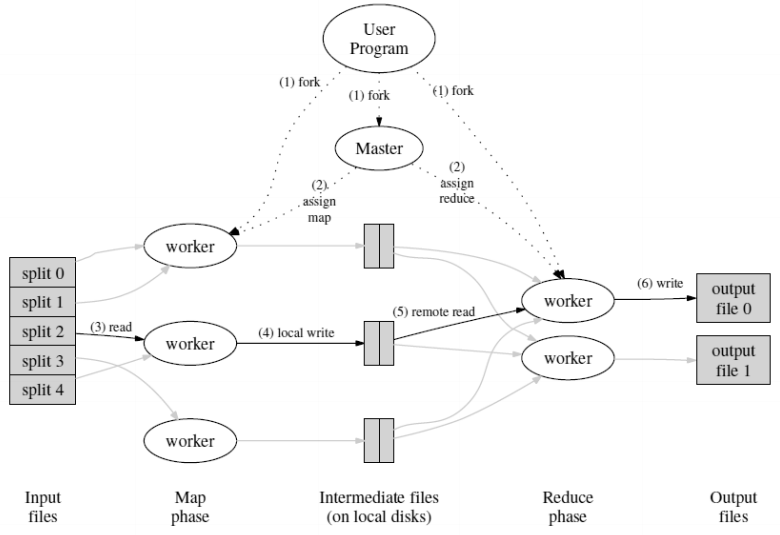
- 文件划分
- master分派map和reduce任务
- 执行map函数
- 中间结果缓存和位置传递
- 执行reduce函数
- 生成最终结果文件
- 结果返回
Master是将中间结果文件从map task传递到reduce task的渠道。
保存:对于每个完成的map task,master会保存由它产生的R个中间结果文件的大小及位置。
收到:中间结果信息上报:当map task结束后,将会受到对于这些位置和大小信息的更新。
推送:中间结果信息(位置+大小)会被逐步推送到那些包含正在处理中国的reduce task 的worker
容错:
标记失败:Master周期性地ping每个worker。一定时间内无响应则标记失败。
重新执行:标记失败worker上的完成状态任务需要重新执行,因为中间结果仍保存在失败机器上。
Master失败:从上次检查点状态恢复拷贝。
本地化:输入和中间结果本地存取。
任务粒度:
R个map task 和 M各reduce task,M和R都应当远远大于运行worker的机器数目。
优点:
提高动态负载平衡。
加速worker失败后的恢复过程。
M的选择:使每个独立task输入数据限制在16M到64M之间。
R的选择:大概是使用worker机器的几倍。
备份任务:
长尾:花费相当长的时间去完成MapReduce任务中最后剩下的极少数的那几个task的那台机器。
解决:当MapReduce任务接近尾声的时候,master会备份那些还在执行的task,只要该task的主本或者一个副本完成了,我们就认为它完成了。
技巧
- 划分函数
- 有序化保证:中间结果的key/value对是按照key值的增序进行处理
- 合并函数:每个reduce task部分归并
- 输入和输出类型:预定义的类型就足够了
- 副作用:map和reduce操作过程中产生一个文件作为额外输出,应用程序编写者保证这些操作的原子性以及幂等性(backup机制)
- 跳过坏记录:一种可选模式,在该模式下,MapReduce库会检测哪些记录会引发crash,然后跳过它们继续执行。
- 本地执行:调试和小规模测试可以再本地串行执行
- 状态信息:web页面
- 计数器:MapReduce库提供了一些计数器设施来计算各种事件的发生。
MapReduce优点:
- 模型容易使用,隐藏了并行化、容错、本地化优化、负载平衡的细节
- 大量的问题可以简单地用MapReduce计算来表达
- 可以扩展到数千台机器上
参考资料:
《google系列论文》- MapReduce
Google论文系列(2) MapReduce的更多相关文章
- Google论文之三----MapReduce
Google论文之三----MapReduce MapReduce:大型集群上的简单数据处理 摘要 MapReduce是一个设计模型,也是一个处理和产生海量数据的一个相关实现.用户指定一个用于处理一个 ...
- 转:Google论文之三----MapReduce
文章来自于:http://www.cnblogs.com/geekma/p/3139823.html MapReduce:大型集群上的简单数据处理 摘要 MapReduce是一个设计模型,也是一个处理 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- [转]玩转Google开源C++单元测试框架Google Test系列
gtest的官方网站是: http://code.google.com/p/googletest/ 从官方的使用文档里,你几乎可以获得你想要的所有东西 http://code.google.com/p ...
- 转:玩转Google开源C++单元测试框架Google Test系列
转自http://www.cnblogs.com/coderzh/archive/2009/04/06/1426755.html 前段时间学习和了解了下Google的开源C++单元测试框架Google ...
- 玩转Google开源C++单元测试框架Google Test系列(转载)
越来越多公司采用敏捷开发,单元和回归测试越来越重要,GTest作为最佳C++单元测试工具越来越多的被使用.转自 http://www.cnblogs.com/coderzh/archive/2009/ ...
- Google的PageRank及其Map-reduce应用(日志五)
上一篇:Hadoop的安装(日志四) 1,算法的原理解释: 如下图所示,G就是传说中的谷歌矩阵,这个矩阵是n*n型号的,n表示共计有n个网页. 如矩阵中所示: 11位置处的元素,是表示第一个网页指向的 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- 读论文系列:Deep transfer learning person re-identification
读论文系列:Deep transfer learning person re-identification arxiv 2016 by Mengyue Geng, Yaowei Wang, Tao X ...
随机推荐
- Python案例之QQ空间自动登录程序实现
不多说,直接上干货! 工具选择: 电脑系统:win7,32 位,下面第二部安装SetupTools时注意系统版本要求: Python: 2.7.11, 相信只要是2.7的就可以实现: Seleniu ...
- 使用github oauth 出现 OpenSSL::SSL::SSLError - SSL_connect SYSCALL returned=5 errno=0 state=SSLv2/v3 解决
A top level initializer is highly recommended to use: conf/initializer/tls_settings.rb OpenSSL::SSL: ...
- iOS开源项目周报0119
由OpenDigg 出品的iOS开源项目周报第六期来啦.我们的iOS开源周报集合了OpenDigg一周来新收录的优质的iOS开源项目,方便iOS开发人员便捷的找到自己需要的项目工具等. Sharaku ...
- [转]emailjs-smtp-client
本文转自:https://github.com/emailjs/emailjs-smtp-client/blob/master/README.md SMTP Client SMTP Client al ...
- RabbitMQ---5、远程 IP 访问
刚刚安装的RabbitMQ-Server-3.3.7,并且也已经开启了Web管理功能,但是现在存在一个问题: 出于安全的考虑,guest这个默认的用户只能通过http://localhost:1567 ...
- WAMP配置httpd.conf允许外部访问
在电脑上开启Apache服务后,如何让外部网络访问呢? 在网上查找答案和问过一些小伙伴后,得到以以下方案.大致是在httpd.conf中加入一些语句以及利用自己的WiFi建立热点,让需要访问的设备连接 ...
- [javaSE] 面向对象(Object类toString)
每一个对象,都有一个在内存中的地址哈希值,这个哈希值是十六进制的 调用Object对象的hashCode()方法,返回这个对象的哈希值 调用Integer.toHexString()方法,转换十六进制 ...
- java实现邮箱验证的功能
在日常生活中,我们在一个网站中注册一个账户时,往往在提交个人信息后,网站还要我们通过手机或邮件来验证,邮件的话大概会是下面这个样子的: 用户通过点击链接从而完成注册,然后才能登录. 也许你会想,为什么 ...
- 01 使用JavaScript原生控制div属性
写在前面: 因对前端开发感兴趣,于是自学前端技术,现在已经会HTML.CSS.JavaScript基础技术.但水平处于小白阶段,在网上找一些小项目练练手,促进自己的技术成长.文章记录自己的所思所想,以 ...
- 小程序异步处理demo计时器setInterval()
实现一个计时器/秒 其实就是要求对某字段每秒执行一次更新 这里用到了官方给的定时器 官方API 每秒刷新一次,所以用setInterval()方法 下面给出关键代码: 由于无关代码过多,这里尽可能贴出 ...