【SQL Server 2012】按倒序存储“分组统计”结果的临时表到新建表
程序预先说明:
本文访问的数据库是基于存有RDF三元组的开源数据库Localyago修改的库,其中只有一个表,表中有五个属性:主语subject、谓语predict、宾语object、主语的编号subid,宾语的编号objid。每条记录由(subject,predict,object,subid,objid)组成。其中当宾语为字符型而不是实体时(比如“2011”),编号默认为0。有以下数据表:
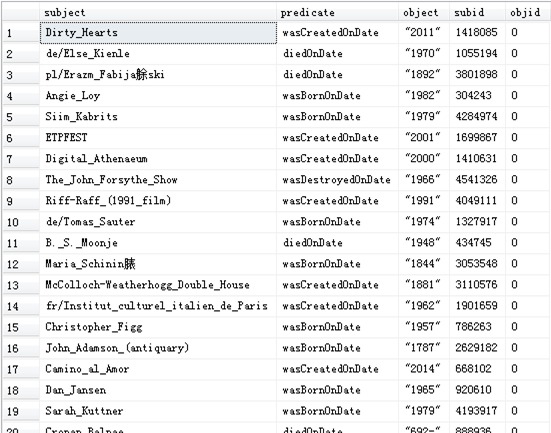
程序需求:
- 统计每个主语有多少相关的谓语属性(每个谓语可有多个宾语),即有多少以该实体作为主语的记录
- 由于结果非常巨大,所以需要将结果存储到数据库中的新建的一个表中,并按倒序存储
具体过程:
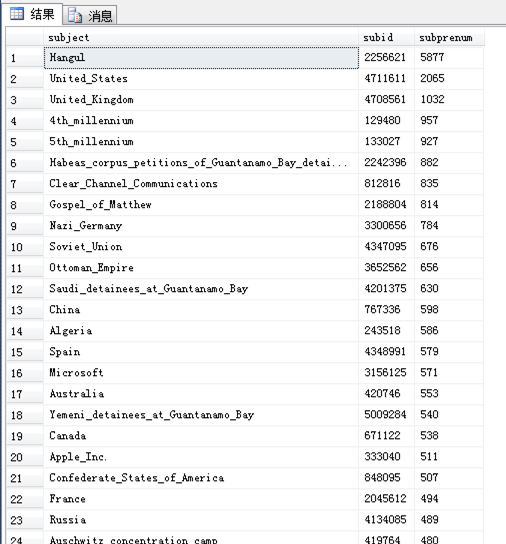
- 统计每个主语的谓词数目,输出(主语,主语id和主语属性数目),按每个主语的属性数目倒序输出:
select subject, subid, count(subject) as subprenum
from [Localyago].[dbo].[yago]
group by subject,subid
order by subprenum DESC;
group by实现分组统计,这里按subject分类,由于我们在select的时候选择了subject和subid,而select中的字段要么包含在group by语句里,要么被包含在聚合函数里,所以我们在这里的group by中也要写入subid,不然会报错
order by 是排序,默认从小到大输出,加上DESC就变成倒序、从大到小输出
得到如下结果:
2. 将查询结果的临时表按subprenum倒序存入新的表中,便于存储和查询
最基本的方式:
如果新表不存在
select * into 新表 from 旧表
如果新表不存在
insert into 新表 select * from 旧表
从而有:
select subject, subid, count(subject) as subprenum
into Localyago.dbo.subpre
from [Localyago].[dbo].[yago]
group by subject,subid;
order by subprenum;
然后发现虽然我们上一步查询的结果是有序的,但运行这个之后生成的新表,并没有按照subprenum排序,顺序是乱的。
检索之后发现这是由于SQL Server自身的局限,如果有特殊需要,要求临时表里面的数据有序,则可以通过【创建聚集索引】来解决这个问题。具体请参考博文:https://www.cnblogs.com/kerrycode/p/5172333.html
从而改进代码如下:
select subject, subid, count(subject) as subprenum
into Localyago.dbo.subpre
from [Localyago].[dbo].[yago]
where 1=0
group by subject,subid;
create clustered index inx_subpre on Localyago.dbo.subpre(subprenum DESC);--创建聚集索引,按subprenum倒序排序
insert into Localyago.dbo.subpre
select subject, subid, count(subject) as subprenum
from [Localyago].[dbo].[yago]
where subid !=0
group by subject,subid
order by subprenum;
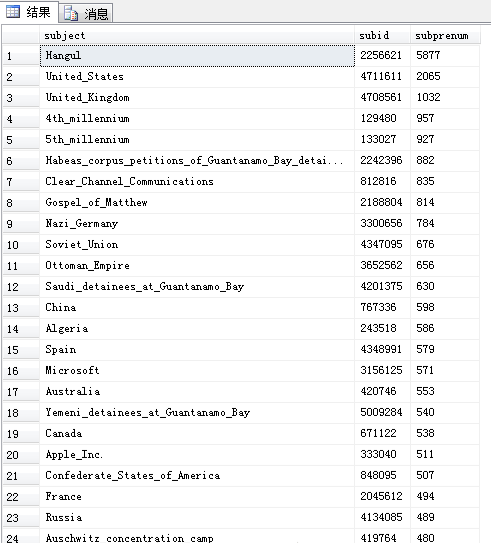
这样运行之后得到的新表subpre里的记录就是按照subprenum倒序排序了
如下:
【SQL Server 2012】按倒序存储“分组统计”结果的临时表到新建表的更多相关文章
- 在SQL Server 2012中如何使用分组集
作者:Itzik Ben-Gan 翻译:张洪举 此文摘自作者的<Microsoft SQL Server 2012 T-SQL基础>. 分组集就是你据以分组的一个属性集.传统上,SQL中 ...
- SQL Server 2012 列存储索引分析(翻译)
一.概述 列存储索引是SQL Server 2012中为提高数据查询的性能而引入的一个新特性,顾名思义,数据以列的方式存储在页中,不同于聚集索引.非聚集索引及堆表等以行为单位的方式存储.因为它并不要求 ...
- SQL Server 2012 列存储索引分析(转载)
一.概述 列存储索引是SQL Server 2012中为提高数据查询的性能而引入的一个新特性,顾名思义,数据以列的方式存储在页中,不同于聚集索引.非聚集索引及堆表等以行为单位的方式存储.因为它并不要求 ...
- 统计sql server 2012表的行数
--功能:统计sql server 2012表的行数 SELECT a.name, a.object_id, b.rows, b.index_id FROM sys.tables AS a INNER ...
- (数据科学学习手册28)SQL server 2012中的查询语句汇总
一.简介 数据库管理系统(DBMS)最重要的功能就是提供数据查询,即用户根据实际需求对数据进行筛选,并以特定形式进行显示.在Microsoft SQL Serve 2012 中,可以使用通用的SELE ...
- SQL Server 2012 数据库笔记
慕课网 首页 实战 路径 猿问 手记 Python 手记 \ SQL Server 2012 数据库笔记 SQL Server 2012 数据库笔记 2016-10-25 16:29:33 1 ...
- SQL Server 2012 各版本功能比较
有关不同版本的 SQL Server 2012 所支持的功能的详细信息. 功能名称 Enterprise 商业智能 Standard Web Express with Advanced Service ...
- 【转】Microsoft® SQL Server® 2012 Performance Dashboard Reports
http://www.cnblogs.com/shanyou/archive/2013/02/12/2910232.html SQL Server Performance Dashboard Repo ...
- SQL Server 2012 案例教程(贾祥素)——学习笔记
第2章 SQL Server 2012概述 1.SQL(Structed Query Language),结构化查询语言. 2.SSMS(SQL Server Mangement Studio),SQ ...
随机推荐
- windows cmd 切换磁盘
抛砖引玉 切换到D盘根目录——cd /d D: 切换到D:\dev目录——cd /d D:\dev
- 洛谷 P3380 【模板】二逼平衡树(树套树)
题面 luogu 题解 2019年AC的第一道题~~ 函数名命名为rank竟然会ce 我写的是树状数组套值域线段树(动态开点) 操作1:询问\(k\)在\([l-r]\)这段区间有多少数比它小,再加\ ...
- Phyton自定义包导入。
说明:同一个项目下的自定义包. 项目层次: 1:先建好项目Pybasestudty 2:建Python package,包名:pytestpk,__init__.py是建包时自动产生的文件. 3:在该 ...
- 深入应用C++11:代码优化与工程级应用》勘误表
https://www.cnblogs.com/qicosmos/p/4562174.html
- MVC参数自动装配
在拿到一个类型的所有属性以及字段的描述信息后,就可以通过循环的方式,根据这些数据成员的名字去QueryString,Form,Session,Cookie读取所需的数据了. 就是遍历参数,然后用反射遍 ...
- how to use Sqoop to import/ export data
Sqoop is a tool designed for efficiently transferring data between RDBMS and HDFS, we can import dat ...
- cloudemanager安装时出现ProtocolError: <ProtocolError for 127.0.0.1/RPC2: 401 Unauthorized>问题解决方法(图文详解)
不多说,直接上干货! 问题详情 查看日志/var/log/cloudera-scm-agent/,得知 解决办法 $> ps -ef | grep supervisord $> kill ...
- Long 和 Integer
Integer 32位 其范围为 -2^31 到 2^31-1 之间,所以最大值是 2^31-1 Long 64位
- AI从入门到放弃:CNN的导火索,用MLP做图像分类识别?
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 作者:郑善友 腾讯MIG后台开发工程师 导语:在没有CNN以及更先进的神经网络的时代,朴素的想法是用多层感知机(MLP)做图片分类的识别:但 ...
- python pickle命令执行与marshal 任意代码执行
1.python pickle反序列化漏洞 自己的理解: 由于在类的__reduce__方法中提供了我们可以自定义程序如何去解序列化的方法,因此如果应用程序接受了不可信任的序列化的数据,那么就可能导致 ...