Linux Kernel文件系统写I/O流程代码分析(一)
Linux Kernel文件系统写I/O流程代码分析(一)
在Linux VFS机制简析(二)这篇博客上介绍了struct address_space_operations里底层文件系统需要实现的操作,实际编码过程中发现不是那么清楚的知道这里面的函数具体是干啥,在什么时候调用。尤其是写IO相关的操作,包括write_begin, write_end, writepage, writepages, direct_IO以及set_page_dirty等函数指针。
要搞清楚这些函数指针,就需要纵观整个写流程里这些函数指针的调用位置。因此本文重点分析和梳理了Linux文件系统写I/O的代码流程,以帮助实现底层文件系统的读写接口。
概览
先放一张图镇贴,该流程图没有包括bdi_writeback回写机制(将在下一篇中展示):
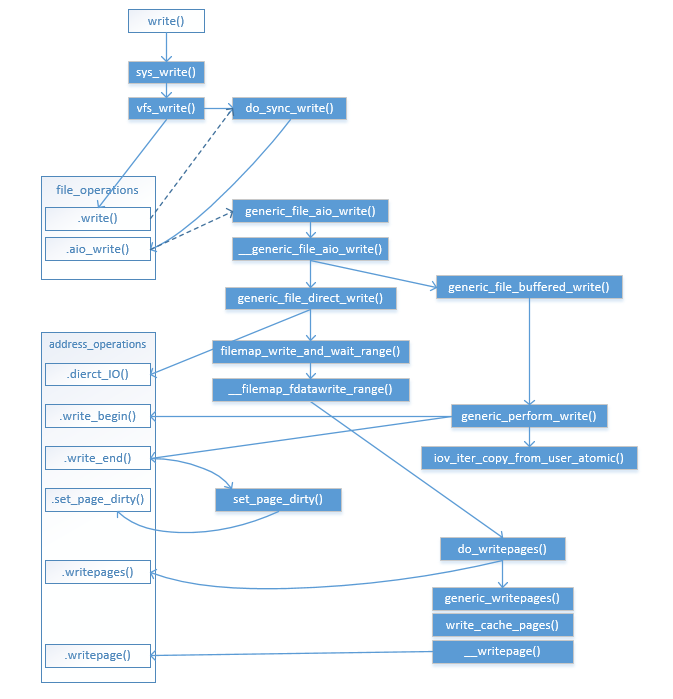
VFS流程
sys_write()
Glibc提供的write()函数调用由内核的write系统调用实现,对应的系统调用函数为sys_write()定义如下:
asmlinkage long sys_write(unsigned int fd, const char __user *buf,
size_t count);
sys_write()的实现在fs/read_write.c里:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
该函数获取struct fd引用计数和pos锁定,获取pos并主要通过调用vfs_write()实现数据写入。
vfs_write()
vfs_write()函数定义如下:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
if (!file->f_op || (!file->f_op->write && !file->f_op->aio_write))
return -EINVAL;
if (unlikely(!access_ok(VERIFY_READ, buf, count)))
return -EFAULT;
ret = rw_verify_area(WRITE, file, pos, count);
if (ret >= 0) {
count = ret;
file_start_write(file);
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos);
else
ret = do_sync_write(file, buf, count, pos);
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
file_end_write(file);
}
return ret;
}
该函数首先调用rw_verify_area()检查pos和count对应的区域是否可以写入(如是否获取写锁等)。然后如果底层文件系统指定了struct file_operations里的write()函数指针,则调用file->f_op->write()函数,否则直接调用VFS的通用写入函数do_sync_write()。
do_sync_write()
VFS的do_sync_write()函数在底层文件系统没有指定f_op->write()函数指针时默认调用,它也被很多底层系统直接指定为f_op->write()。其定义如下所示:
ssize_t do_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{
struct iovec iov = { .iov_base = (void __user *)buf, .iov_len = len };
struct kiocb kiocb;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = *ppos;
kiocb.ki_left = len;
kiocb.ki_nbytes = len;
ret = filp->f_op->aio_write(&kiocb, &iov, 1, kiocb.ki_pos);
if (-EIOCBQUEUED == ret)
ret = wait_on_sync_kiocb(&kiocb);
*ppos = kiocb.ki_pos;
return ret;
}
通过时上面的代码可知,该函数主要生成struct kiocb,将其提交给f_op->aio_write()函数,并等待该kiocb的完成。所以底层文件系统必须实现f_op->aio_write()函数指针。
底层文件系统大部分实现了自己的f_op->aio_write(),也有部分文件系统(如ext4, nfs等)直接指向了通用的写入方法:generic_file_aio_write()。我们通过该函数代码来分析写入的大致流程。
generic_file_aio_write()
VFS(其实是mm模块)提供了通用的aio_write()函数,其定义如下:
ssize_t generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos)
{
struct file *file = iocb->ki_filp;
struct inode *inode = file->f_mapping->host;
ssize_t ret;
BUG_ON(iocb->ki_pos != pos);
mutex_lock(&inode->i_mutex);
ret = __generic_file_aio_write(iocb, iov, nr_segs, &iocb->ki_pos);
mutex_unlock(&inode->i_mutex);
if (ret > 0) {
ssize_t err;
err = generic_write_sync(file, pos, ret);
if (err < 0 && ret > 0)
ret = err;
}
return ret;
}
该函数对inode加锁之后,调用__generic_file_aio_write()函数将数据写入。如果ret > 0即数据写入成功,并且写操作需要同步到磁盘(如设置了O_SYNC),则调用generic_write_sync(),这里面将调用f_op->fsync()函数指针将数据写盘。
函数__generic_file_aio_write()的代码略多,这里贴出主要的片段如下:
ssize_t __generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t *ppos)
{
...
if (io_is_direct(file)) {
loff_t endbyte;
ssize_t written_buffered;
written = generic_file_direct_write(iocb, iov, &nr_segs, pos,
ppos, count, ocount);
...
} else {
written = generic_file_buffered_write(iocb, iov, nr_segs,
pos, ppos, count, written);
}
...
从上面代码可以看到,如果是Direct IO,则调用generic_file_direct_write(),不经过page cache直接写入磁盘;如果不是Direct IO,则调用generic_file_buffered_write()写入page cache。
Direct IO实现
generic_file_direct_write()
函数generic_file_direct_write()的主要代码如下所示:
ssize_t
generic_file_direct_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long *nr_segs, loff_t pos, loff_t *ppos,
size_t count, size_t ocount)
{
...
if (count != ocount)
*nr_segs = iov_shorten((struct iovec *)iov, *nr_segs, count);
write_len = iov_length(iov, *nr_segs);
end = (pos + write_len - 1) >> PAGE_CACHE_SHIFT;
written = filemap_write_and_wait_range(mapping, pos, pos + write_len - 1);
if (written)
goto out;
if (mapping->nrpages) {
written = invalidate_inode_pages2_range(mapping,
pos >> PAGE_CACHE_SHIFT, end);
if (written) {
if (written == -EBUSY)
return 0;
goto out;
}
}
written = mapping->a_ops->direct_IO(WRITE, iocb, iov, pos, *nr_segs);
if (mapping->nrpages) {
invalidate_inode_pages2_range(mapping,
pos >> PAGE_CACHE_SHIFT, end);
}
if (written > 0) {
pos += written;
if (pos > i_size_read(inode) && !S_ISBLK(inode->i_mode)) {
i_size_write(inode, pos);
mark_inode_dirty(inode);
}
*ppos = pos;
}
out:
return written;
}
由于是Direct IO,在写入之前需要调用filemap_write_and_wait_range()将page cache里的对应脏数据刷盘,以保障正确的写入顺序。filemap_write_and_wait_range()函数最终通过调用do_writepages()函数将脏页刷盘(参见后面)。
然后调用invalidate_inode_pages2_range()函数将要写入的区域在page cache里失效,以保证读操作必须经过磁盘读到最新写入的数据。在本次写操作完成后再次调用invalidate_inode_pages2_range()函数将page cache失效,避免写入磁盘的过程中有新的读取操作将过期数据读到了cache里。
最终通过调用a_ops->dierct_IO()将数据Direct IO方式写入磁盘。a_ops即struct address_operations,由底层文件系统实现。
Buffered IO实现
generic_file_buffered_write()
函数generic_file_buffered_write()的主要代码如下所示:
ssize_t
generic_file_buffered_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t pos, loff_t *ppos,
size_t count, ssize_t written)
{
struct file *file = iocb->ki_filp;
ssize_t status;
struct iov_iter i;
iov_iter_init(&i, iov, nr_segs, count, written);
status = generic_perform_write(file, &i, pos);
if (likely(status >= 0)) {
written += status;
*ppos = pos + status;
}
return written ? written : status;
}
该函数初始化一个struct iov_iter,然后主要通过调用generic_perform_write()函数写入page cache。
generic_perform_write()
函数generic_perform_write()主要代码如下所示:
static ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
...
if (segment_eq(get_fs(), KERNEL_DS))
flags |= AOP_FLAG_UNINTERRUPTIBLE;
do {
...
offset = (pos & (PAGE_CACHE_SIZE - 1));
bytes = min_t(unsigned long, PAGE_CACHE_SIZE - offset,
iov_iter_count(i));
again:
if (unlikely(iov_iter_fault_in_readable(i, bytes))) {
status = -EFAULT;
break;
}
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
if (unlikely(status))
break;
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
pagefault_disable();
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
pagefault_enable();
flush_dcache_page(page);
mark_page_accessed(page);
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
if (unlikely(status < 0))
break;
copied = status;
cond_resched();
iov_iter_advance(i, copied);
if (unlikely(copied == 0)) {
bytes = min_t(unsigned long, PAGE_CACHE_SIZE - offset,
iov_iter_single_seg_count(i));
goto again;
}
pos += copied;
written += copied;
balance_dirty_pages_ratelimited(mapping);
if (fatal_signal_pending(current)) {
status = -EINTR;
break;
}
} while (iov_iter_count(i));
return written ? written : status;
}
该函数包括如下几个步骤:
1.通过调用a_ops->write_begin()进行数据写入前的处理,由底层文件系统实现,主要处理需要申请额外的存储空间,以及从后端存储(磁盘或者网络)读取不在缓存里的page数据。该函数返回locked的page。
2.从用户空间拷贝数据到步骤1返回的page里。访问用户态内存时可能触发缺页异常,为避免陷入缺页异常处理从而导致重入和死锁(如mmap文件系统的内存),拷贝之前,通过pagefault_disable()将缺页异常处理关闭,当发生缺页异常时不进行异常处理。
3.通过调用底层文件系统的a_ops->write_end()将page这是为dirty并unlock。
4.循环步骤1-3,直到所有iov都得到处理,每次循环只处理一个page里的数据。
5.调用balance_dirty_pages_ratelimited()平衡内存中的脏页,需要时将脏页刷盘。
后记
从上可知,对于Buffered IO,并不一定有将数据写入磁盘的操作,这就是延迟写技术。数据写入内核的page cache缓存后,后续由bdi_writeback机制负责脏页的数据刷盘回写。
Linux Kernel文件系统写I/O流程代码分析(一)的更多相关文章
- Linux Kernel文件系统写I/O流程代码分析(二)bdi_writeback
Linux Kernel文件系统写I/O流程代码分析(二)bdi_writeback 上一篇# Linux Kernel文件系统写I/O流程代码分析(一),我们看到Buffered IO,写操作写入到 ...
- arm linux kernel 从入口到start_kernel 的代码分析
参考资料: <ARM体系结构与编程> <嵌入式Linux应用开发完全手册> Linux_Memory_Address_Mapping http://www.chinaunix. ...
- Ecshop的购物流程代码分析详细说明
Ecshop的购物流程代码分析详细说明 (2012-07-30 10:41:12) 转载▼ 标签: 购物车 结算中心 商品价格 ecshop ecshop购物流程 杂谈 分类: ECSHOP研究院 同 ...
- Openfire注册流程代码分析
Openfire注册流程代码分析 一.客户端/服务端注册用户流程 经过主机连接消息确认后,客户端共发送俩条XML完成注册过程.服务器返回两条XML. 注:IQ消息节点用于处理用户的注册.好友.分组.获 ...
- 《linux 内核全然剖析》 fork.c 代码分析笔记
fork.c 代码分析笔记 verifiy_area long last_pid=0; //全局变量,用来记录眼下最大的pid数值 void verify_area(void * addr,int s ...
- 《linux 内核全然剖析》 sys.c 代码分析
sys.c 代码分析 setregid /* * This is done BSD-style, with no consideration of the saved gid, except * th ...
- 配置Linux Kernel时make menuconfig执行流程分析
在编译内核前,一般是根据已有的配置文件(一般在内核根目录下的arch/arm/configs/文件夹下,把该目录下的xxx_defconfig文件拷贝到内核根目录下,并重命名为.config)来 ...
- linux kernel的cmdline參数解析原理分析
利用工作之便,今天研究了kernel下cmdline參数解析过程.记录在此.与大家共享.转载请注明出处.谢谢. Kernel 版本:3.4.55 Kernel启动时会解析cmdline,然后依据这些參 ...
- pf_ring DNA接收流程代码分析
经过一个月的学习,对pf_ring DNA的内核部分有了一些认识,本文侧重pf_ring对ixgbe的改动分析. 先说一说接收流程吧,流程如下: 其中,硬中断处理函数是ixgbe_msix_clean ...
随机推荐
- oracle重新编译所有invalid objects
点第一个,按住shift键点最后一个,右键recompile就OK了
- 【bzoj1022】[SHOI2008]小约翰的游戏John 博弈论
Description 小约翰经常和他的哥哥玩一个非常有趣的游戏:桌子上有n堆石子,小约翰和他的哥哥轮流取石子,每个人取 的时候,可以随意选择一堆石子,在这堆石子中取走任意多的石子,但不能一粒石子也不 ...
- bzoj2440完全平方数
题目链接 上来先吐槽题面!!!!!! 你跟我说$1$不是完全平方数昂? 看了半天样例啊. 活生生的半天$……$ 莫比乌斯 反演 函数容斥一下,每次二分就好 反正本宝宝不知道反演是啥. 每次判断应 ...
- The server of Apache (二)——apache服务客户端验证
一.确定网站名称.IP地址 地址为: 192.168.1.1 域名为: www.benet.com 二.配置可用的DNS域名服务或者修改本地hosts记录 ~] # vim /etc/hosts ...
- 浅谈C#中的委托、事件与异步
从刚接触c#编程到现在,差不多快有一年的时间了.在学习过程中,有很多地方始终似是而非,直到最近才弄明白. 本文将先介绍用法,后评断功能. 一.委托 基本用法: 1.声明一个委托类型.委托就像是‘类'一 ...
- [o.e.b.ElasticsearchUncaughtExceptionHandler] [unknown] uncaught exception in thread [main] org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
这是因为不知从哪个版本后,elasticsearch为了安全性,是不能用root用户启动的. 解决的办法:当然是创建一个用户,用创建的用户启动啦,注意权限的问题,目录也应该改为创建的用户权限! 我是用 ...
- google 浏览器的Debug 调试工具使用
一个写后台的人 有一天要自己找前台页面的错误 于是乎就得会前台debug 于是乎我不会 就在网上找了一些资料看 不就是几个按钮 嘛 有啥难的 上图片 1.Google 浏览器 F12 就可以看到 ...
- Qt 学习之路 2(76):QML 和 QtQuick 2
Home / Qt 学习之路 2 / Qt 学习之路 2(76):QML 和 QtQuick 2 Qt 学习之路 2(76):QML 和 QtQuick 2 豆子 2013年12月18日 Qt ...
- 【转】 关于IDEA javax.servlet.http.HttpServletRequest; 不存在 解决方案
昨天从eclipse导入了一个web项目到idea,想运行一下,结果发现 servlet报红... 没有包,第一反应就是eclipse需要设置Targeted Runtimes,但是idea的设置是啥 ...
- 012 Android Palette颜色选择器的使用
1.页面总体使用线性布局(LinearLayout) 2.将Toolbar(顶部菜单栏)拖入design模式下的设计界面中 3.颜色选择器需要在build.gradle中手动的添加 compile ' ...