hadoop自定义数据类型
统计某手机数据库的每个手机号的上行数据包数量和下行数据包数量
数据库类型如下:
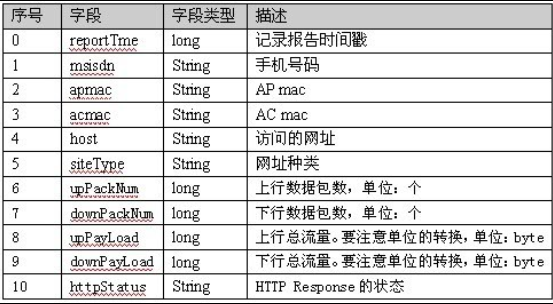
数据库内容如下:
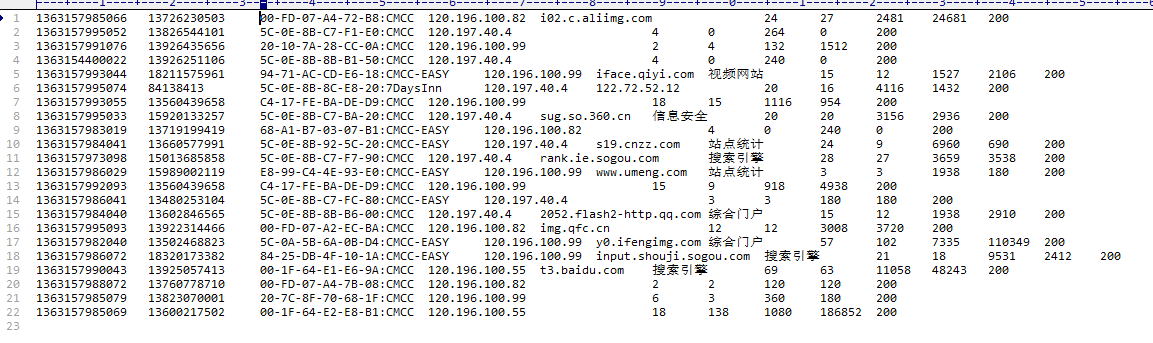
下面自定义类型SimLines,类似于平时编写的model
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; public class SimLines implements Writable { long upPackNum, downPackNum; public SimLines(){
super();
} public SimLines(String upPackNum, String downPackNum) {
super();
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
} //反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
} //序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
} public String toString(){
return upPackNum + "\t" + downPackNum;
}
}
注意:write方法中的顺序和readFields中的顺序要相同
其中的空构造方法一定要写,不然会报错或者反序列化步骤不执行。还有toString方法也必须定义,不然最后输的东西会很头疼的,不信你可以试试。
下面是hadoop的功能代码
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { static final String INPUT_PATH = "F:/Tutorial/Hadoop/TestData/data/HTTP_20130313143750.dat";
static final String OUTPUT_PATH = "hdfs://masters:9000/user/hadoop/output/TestPhone";
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { //添加以下的代码,就可以联通,不知道咋回事
String path = new File(".").getCanonicalPath();
System.getProperties().put("hadoop.home.dir", path);
new File("./bin").mkdirs();
new File("./bin/winutils.exe").createNewFile(); Configuration conf = new Configuration();
Path outpath = new Path(OUTPUT_PATH); //检测输出路径是否存在,如果存在就删除,否则会报错
FileSystem fileSystem = FileSystem.get(new URI(OUTPUT_PATH), conf);
if(fileSystem.exists(outpath)){
fileSystem.delete(outpath, true);
} Job job = new Job(conf, "SimLines"); FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outpath); job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(SimLines.class);
job.waitForCompletion(true);
} //输入,map,即拆分过程
static class MyMapper extends Mapper<LongWritable, Text, Text, SimLines>{ protected void map(LongWritable k1, Text v1, Context context)throws IOException, InterruptedException{
String[] splits = v1.toString().split("\t");//按照空格拆分
Text k2 = new Text(splits[1]);
SimLines simLines = new SimLines(splits[6], splits[7]);
context.write(k2, simLines);
}
} //输出,reduce,汇总过程
static class MyReducer extends Reducer<Text, SimLines, Text, SimLines>{
protected void reduce(
Text k2, //输出的内容,即value
Iterable<SimLines> v2s, //是一个longwritable类型的数组,所以用了Iterable这个迭代器,且元素为v2s
org.apache.hadoop.mapreduce.Reducer<Text, SimLines, Text, SimLines>.Context context)
//这里一定设置好,不然输出会变成单个单词,从而没有统计数量
throws IOException, InterruptedException {
//列表求和 初始为0
long upPackNum = 0L, downPackNum = 0L;
for(SimLines simLines:v2s){
upPackNum += simLines.upPackNum;
downPackNum += simLines.downPackNum;
}
SimLines v3 = new SimLines(upPackNum + "", downPackNum + "");
context.write(k2, v3);
}
}
}
这样就ok了,结果如下:
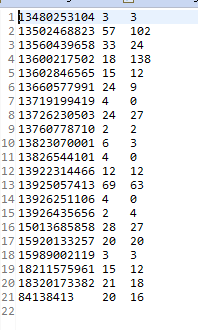
hadoop自定义数据类型的更多相关文章
- hadoop的自定义数据类型和与关系型数据库交互
最近有一个需求就是在建模的时候,有少部分数据是postgres的,只能读取postgres里面的数据到hadoop里面进行建模测试,而不能导出数据到hdfs上去. 读取postgres里面的数据库有两 ...
- Hadoop MapReduce自定义数据类型
一 自定义数据类型的实现 1.继承接口Writable,实现其方法write()和readFields(), 以便该数据能被序列化后完成网络传输或文件输入/输出: 2.如果该数据需要作为主键key使用 ...
- Hadoop-MapReduce之自定义数据类型
以下是自定义的一个数据类型,有两个属性,一个是名称,一个是开始点(可以理解为单词和单词的位置) MR程序就不写了,请看WordCount程序. package cn.genekang.hadoop.m ...
- Hadoop自定义类型处理手机上网日志
job提交源码分析 在eclipse中的写的代码如何提交作业到JobTracker中的哪?(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 con ...
- 通过SQL Server自定义数据类型实现导入数据
写在前面 在看同事写的代码时看到了SQL Server中可以自定义数据类型,而且定义的是DataTable类型的数据类型. 后我想起了以前我们导入数据时要么是循环insert写入,要么是SqlBulk ...
- OSG 自定义数据类型 关键帧动画
OSG 自定义数据类型 关键帧动画 转自:http://blog.csdn.net/zhuyingqingfen/article/details/12651017 /* 1.创建一个AnimManag ...
- Oracle存储过程-自定义数据类型,集合,遍历取值
摘要 Oracle存储过程,自定义数据类型,集合,遍历取值 目录[-] 0.前言 1.Packages 2.Packages bodies 3.输出结果 0.前言 在Oracle的存储过程中,可能会遇 ...
- eclipse 提交作业到JobTracker Hadoop的数据类型要求必须实现Writable接口
问:在eclipse中的写的代码如何提交作业到JobTracker中的哪?答:(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 connect() ...
- Oracle自定义数据类型 1
原文 oracle 自定义类型 type / create type 一 Oracle中的类型 类型有很多种,主要可以分为以下几类: 1.字符串类型.如:char.nchar.varchar2.nva ...
随机推荐
- UDP端口启动后一段时间无法接收到数据
接口需求:开发一个UDP协议的接口作为服务端接收来自客户端的认证数据,数据量每分钟7w+条; 数据格式:标准的redius协议,redius协议的相关知识在网上查资料,提供线索:http://blog ...
- flex 遇到white-space:nowrap
背景,做一个前面图片宽度固定,后面宽度自适应,使用到了flex布局,但是想让后面div里文字不换行,超出以点点表示时,这时布局就乱了,查了下,原来flex布局与white-space:nowrap有影 ...
- SAC E#1 - 一道难题 Tree(树形DP)
题目背景 冴月麟和魏潇承是好朋友. 题目描述 冴月麟为了守护幻想乡,而制造了幻想乡的倒影,将真实的幻想乡封印了.任何人都无法进入真实的幻想乡了,但是她给前来救她的魏潇承留了一个线索. 她设置了一棵树( ...
- ABAP术语-BW (Business Information Warehouse)
BW (Business Information Warehouse) 原文:http://www.cnblogs.com/qiangsheng/archive/2008/01/14/1037761. ...
- MySQL 修改主键
网上顺便查了下 ,要先删除 再创建,如果是添加复合主键,则复合主键值不能为空 alter table table_name drop primary key; alter table table_na ...
- 高级同步器:信号量Semaphore
引自:https://blog.csdn.net/Dason_yu/article/details/79734425 一.信号量一个计数信号量.从概念上讲,信号量维护了一个许可集.Semaphore经 ...
- 转:Java子线程中的异常处理(通用)
引自:https://www.cnblogs.com/yangfanexp/p/7594557.html 在普通的单线程程序中,捕获异常只需要通过try ... catch ... finally . ...
- Linux基础(04)、功能配置(调整防火墙、静态IP、环境变量)
目录 一.centos防火墙 二.VMware网络连接方式 2.1.连接方式:桥接.NAT.仅主机 2.2.常见问题 三.centos配置静态IP 四.环境变量 4.1.什么是环境变量 4.2.临时修 ...
- Python学习手册之Python异常和文件
在上一篇文章中,我们介绍了 Python 的函数和模块,现在我们介绍 Python 中的异常和文件. 查看上一篇文章请点击:https://www.cnblogs.com/dustman/p/9963 ...
- C语言实现二分查找
二分查找优势:比顺序查找更有效率 特点:元素按顺序排列 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include ...