Hadoop自定义类型处理手机上网日志
job提交源码分析
在eclipse中的写的代码如何提交作业到JobTracker中的哪?
(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法
connect();
info = jobClient.submitJobInternal(conf);
(2)在connect()方法中,实际上创建了一个JobClient对象。
在调用该对象的构造方法时,获得了JobTracker的客户端代理对象JobSubmissionProtocol。
JobSubmissionProtocol的实现类是JobTracker。
(3)在jobClient.submitJobInternal(conf)方法中,调用了
JobSubmissionProtocol.submitJob(...),
即执行的是JobTracker.submitJob(...)。
Hadoop数据类型
1.Hadoop的数据类型要求必须实现Writable接口。
2.java基本类型与Hadoop常见基本类型的对照
Long LongWritable
Integer IntWritable
Boolean BooleanWritable
String Text
java类型如何转化为hadoop基本类型?
调用hadoop类型的构造方法,或者调用set()方法。
new LongWritable(123L);
hadoop基本类型如何转化为java类型?
对于Text,需要调用toString()方法,其他类型调用get()方法。
使用Hadoop自定义类型处理手机上网日志
1、首先,将手机上网日志文件HTTP_20130313143750.dat通过WinSCP工具复制到/usr/local目录下
2、将日志文件上传到hdfs://chaoren:9000/wlan文件夹下
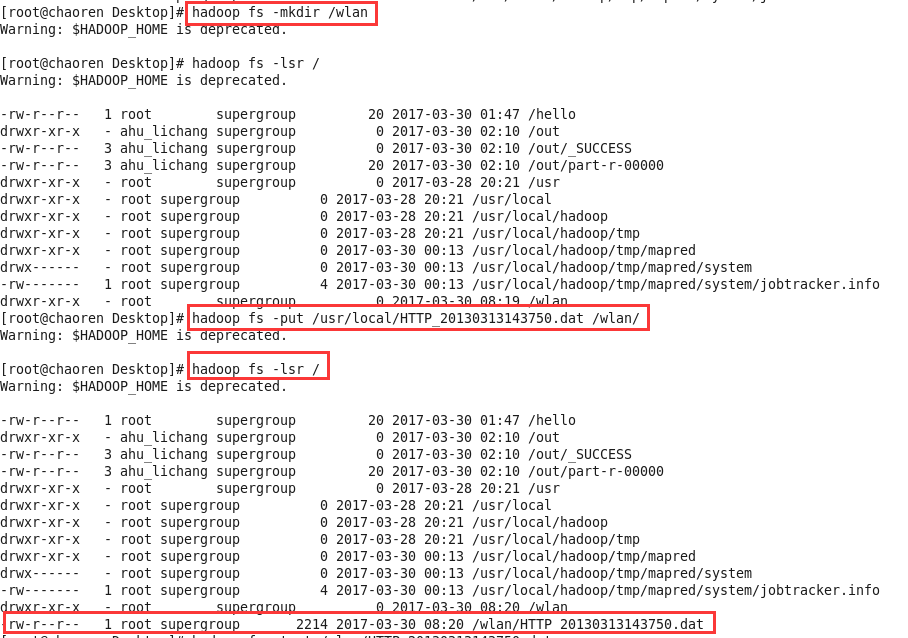
日志文件:

日志文件中各字段含义:
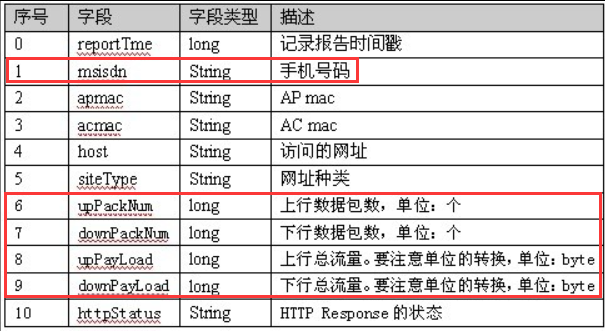
3、编写Java代码将日志文件中想要的数据统计出来。
package mapreduce; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; public class KpiApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/wlan";//wlan是个文件夹,日志文件放在/wlan目录下
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
final Job job = new Job(new Configuration(),
KpiApp.class.getSimpleName());
// 1.1 指定输入文件路径
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定哪个类用来格式化输入文件
job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的Mapper类
job.setMapperClass(MyMapper.class);
// 指定输出<k2,v2>的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KpiWritable.class); // 1.3 指定分区类
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1); // 1.4 TODO 排序、分区 // 1.5 TODO (可选)归约 // 2.2 指定自定义的reduce类
job.setReducerClass(MyReducer.class);
// 指定输出<k3,v3>的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(KpiWritable.class); // 2.3 指定输出到哪里
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
// 设定输出文件的格式化类
job.setOutputFormatClass(TextOutputFormat.class); // 把代码提交给JobTracker执行
job.waitForCompletion(true);
} static class MyMapper extends Mapper<LongWritable, Text, Text, KpiWritable> {
protected void map(
LongWritable key,
Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
final String[] splited = value.toString().split("\t");
final String msisdn = splited[1];
final Text k2 = new Text(msisdn);
final KpiWritable v2 = new KpiWritable(splited[6], splited[7],
splited[8], splited[9]);
context.write(k2, v2);
};
} static class MyReducer extends
Reducer<Text, KpiWritable, Text, KpiWritable> {
/**
* @param k2
* 表示整个文件中不同的手机号码
* @param v2s
* 表示该手机号在不同时段的流量的集合
*/
protected void reduce(
Text k2,
java.lang.Iterable<KpiWritable> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L; for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
} final KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum
+ "", upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
};
}
} class KpiWritable implements Writable {
long upPackNum;
long downPackNum;
long upPayLoad;
long downPayLoad; public KpiWritable() {
} public KpiWritable(String upPackNum, String downPackNum, String upPayLoad,
String downPayLoad) {
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
this.upPayLoad = Long.parseLong(upPayLoad);
this.downPayLoad = Long.parseLong(downPayLoad);
} public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
} public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
} @Override
public String toString() {
return upPackNum + "\t" + downPackNum + "\t" + upPayLoad + "\t"
+ downPayLoad;
}
}
4、运行结果
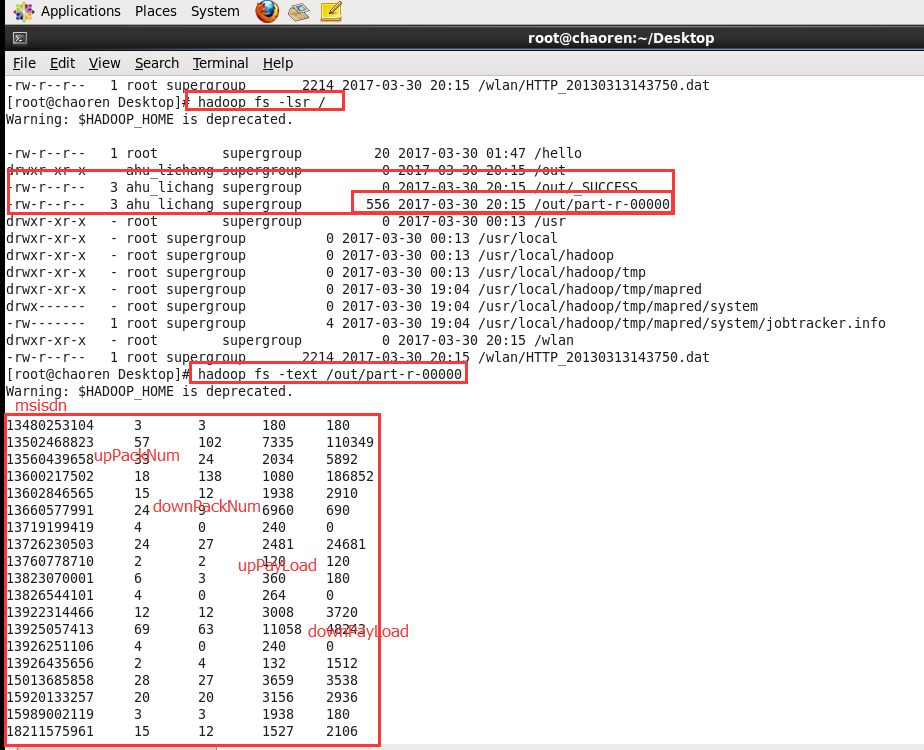
Hadoop自定义类型处理手机上网日志的更多相关文章
- Hadoop日记Day13---使用hadoop自定义类型处理手机上网日志
测试数据的下载地址为:http://pan.baidu.com/s/1gdgSn6r 一.文件分析 首先可以用文本编辑器打开一个HTTP_20130313143750.dat的二进制文件,这个文件的内 ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- 使用Pig对手机上网日志进行分析
在安装成功Pig的基础上.本文将使用Pig对手机上网日志进行分析,详细过程例如以下: 写在前面: 手机上网日志文件phone_log.txt.文件内容 及 字段说明部分截图例如以下 需求分析 显示每一 ...
- MapReduce实现手机上网日志分析(分区)
一.问题背景 实际业务的需要,比如以移动为例,河南的用户去了北京上网,那么他的上网信息默认保存在了北京的基站,那么我们想要查询北京地区的上网日志信息默认也包含了其他地区用户的在本区的上网信息,否则只能 ...
- MapReduce实现手机上网日志分析(排序)
一.背景 1.1 流程 实现排序,分组拍上一篇通过Partitioner实现了. 实现接口,自动产生接口方法,写属性,产生getter和setter,序列化和反序列化属性,写比较方法,重写toStri ...
- 2017.9.2Java中的自定义类型的定义及使用&&自定义类的内存图
今日内容介绍 1.自定义类型的定义及使用 2.自定义类的内存图 3.ArrayList集合的基本功能 4.随机点名器案例及库存案例代码优化 01引用数据类型_类 * A: 数据类型 * a: java ...
- hadoop自定义数据类型
统计某手机数据库的每个手机号的上行数据包数量和下行数据包数量 数据库类型如下: 数据库内容如下: 下面自定义类型SimLines,类似于平时编写的model import java.io.DataIn ...
- CMWAP CMWAP是手机上网使用的接入点的名称
CMWAP 锁定 本词条由“科普中国”百科科学词条编写与应用工作项目 审核 . CMWAP是手机上网使用的接入点的名称.CMWAP使用HTTP代理协议和WAP网关协议可以访问到Internet.移动用 ...
- APN APN指一种网络接入技术,是通过手机上网时必须配置的一个参数,它决定了手机通过哪种接入方式来访问网络。
apn 锁定 本词条由“科普中国”百科科学词条编写与应用工作项目 审核 . APN指一种网络接入技术,是通过手机上网时必须配置的一个参数,它决定了手机通过哪种接入方式来访问网络. 对于手机用户来说,可 ...
随机推荐
- 转:zookeeper中Watcher和Notifications
转自:http://www.tuicool.com/articles/B7FRzm 传统polling远程service服务 传统远程的service往往是这样服务的,服务提供者在远程service注 ...
- Nginx错误日志与优化专题
一.Nginx配置和内核优化 实现突破十万并发 二.一次Nignx的502页面的错误记录 (1)错误页面显示 错误日志: // :: [error] #: * recv() failed (: Con ...
- 活学活用,CSS清除浮动的4种方法
清除浮动这个问题,做前端的应该再熟悉不过了,咱是个新人,所以还是记个笔记,做个积累,努力学习向大神靠近. CSS清除浮动的方法网上一搜,大概有N多种,用过几种,说下个人感受. 1.结尾处加空div标签 ...
- sort函数(cmp)、map用法---------------Tju_Oj_2312Help Me with the Game
这道题里主要学习了sort函数.sort的cmp函数写法.C++的map用法(其实和数组一样) Your task is to read a picture of a chessboard posit ...
- c++刷题(24/100)正则匹配与位运算
题目1:正则表达式匹配 请实现一个函数用来匹配包括'.'和'*'的正则表达式.模式中的字符'.'表示任意一个字符,而'*'表示它前面的字符可以出现任意次(包含0次). 在本题中,匹配是指字符串的所有字 ...
- HDU 4545 (模拟) 魔法串
题目链接 Problem Description 小明和他的好朋友小西在玩一个新的游戏,由小西给出一个由小写字母构成的字符串,小明给出另一个比小西更长的字符串,也由小写字母组成,如果能通过魔法转换使小 ...
- python概念-各类绑定的概念和property的变态一面
# 编辑者:闫龙 # 1.什么是绑定到对象的方法,如何定义,如何调用,给谁用?有什么特性 #在类中定义的(self)方法都是绑定到对象的方法 #定义 class a: def b(self):#绑定到 ...
- centos7.2安装php7.2
Centos 7源码编译安装 php7.2 原文地址:https://renwole.com/archives/29 介绍: 先安装php依赖包,否则在编译安装php7的过程当中会出现各种报错,安装完 ...
- UNIX环境高级编程 第6章 系统数据文件和信息
UNIX系统的正常运作需要用到大量与系统有关的数据文件,例如系统用户账号.用户密码.用户组等文件.出于历史原因,这些数据文件都是ASCII文本文件,并且使用标准I/O库函数来读取. 口令文件 /etc ...
- 【Linux技术】ubuntu常用命令【转】
转自:http://www.cnblogs.com/lcw/p/3159462.html 查看软件xxx安装内容:dpkg -L xxx查找软件库中的软件:apt-cache search 正则表达式 ...