hadoop自定义数据类型
统计某手机数据库的每个手机号的上行数据包数量和下行数据包数量
数据库类型如下:
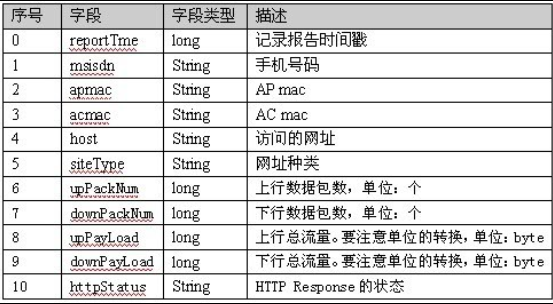
数据库内容如下:
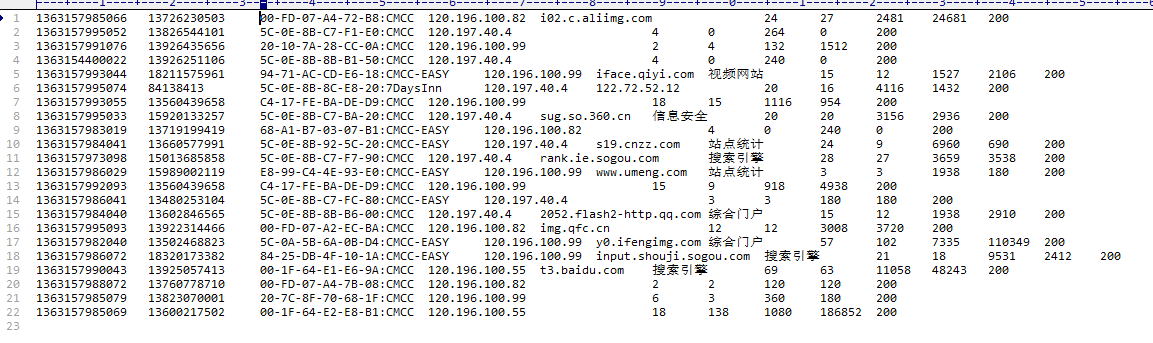
下面自定义类型SimLines,类似于平时编写的model
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; public class SimLines implements Writable { long upPackNum, downPackNum; public SimLines(){
super();
} public SimLines(String upPackNum, String downPackNum) {
super();
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
} //反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
} //序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
} public String toString(){
return upPackNum + "\t" + downPackNum;
}
}
注意:write方法中的顺序和readFields中的顺序要相同
其中的空构造方法一定要写,不然会报错或者反序列化步骤不执行。还有toString方法也必须定义,不然最后输的东西会很头疼的,不信你可以试试。
下面是hadoop的功能代码
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { static final String INPUT_PATH = "F:/Tutorial/Hadoop/TestData/data/HTTP_20130313143750.dat";
static final String OUTPUT_PATH = "hdfs://masters:9000/user/hadoop/output/TestPhone";
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { //添加以下的代码,就可以联通,不知道咋回事
String path = new File(".").getCanonicalPath();
System.getProperties().put("hadoop.home.dir", path);
new File("./bin").mkdirs();
new File("./bin/winutils.exe").createNewFile(); Configuration conf = new Configuration();
Path outpath = new Path(OUTPUT_PATH); //检测输出路径是否存在,如果存在就删除,否则会报错
FileSystem fileSystem = FileSystem.get(new URI(OUTPUT_PATH), conf);
if(fileSystem.exists(outpath)){
fileSystem.delete(outpath, true);
} Job job = new Job(conf, "SimLines"); FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outpath); job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(SimLines.class);
job.waitForCompletion(true);
} //输入,map,即拆分过程
static class MyMapper extends Mapper<LongWritable, Text, Text, SimLines>{ protected void map(LongWritable k1, Text v1, Context context)throws IOException, InterruptedException{
String[] splits = v1.toString().split("\t");//按照空格拆分
Text k2 = new Text(splits[1]);
SimLines simLines = new SimLines(splits[6], splits[7]);
context.write(k2, simLines);
}
} //输出,reduce,汇总过程
static class MyReducer extends Reducer<Text, SimLines, Text, SimLines>{
protected void reduce(
Text k2, //输出的内容,即value
Iterable<SimLines> v2s, //是一个longwritable类型的数组,所以用了Iterable这个迭代器,且元素为v2s
org.apache.hadoop.mapreduce.Reducer<Text, SimLines, Text, SimLines>.Context context)
//这里一定设置好,不然输出会变成单个单词,从而没有统计数量
throws IOException, InterruptedException {
//列表求和 初始为0
long upPackNum = 0L, downPackNum = 0L;
for(SimLines simLines:v2s){
upPackNum += simLines.upPackNum;
downPackNum += simLines.downPackNum;
}
SimLines v3 = new SimLines(upPackNum + "", downPackNum + "");
context.write(k2, v3);
}
}
}
这样就ok了,结果如下:
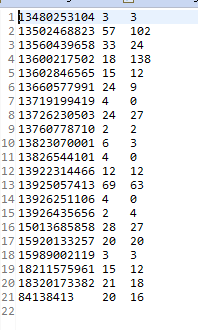
hadoop自定义数据类型的更多相关文章
- hadoop的自定义数据类型和与关系型数据库交互
最近有一个需求就是在建模的时候,有少部分数据是postgres的,只能读取postgres里面的数据到hadoop里面进行建模测试,而不能导出数据到hdfs上去. 读取postgres里面的数据库有两 ...
- Hadoop MapReduce自定义数据类型
一 自定义数据类型的实现 1.继承接口Writable,实现其方法write()和readFields(), 以便该数据能被序列化后完成网络传输或文件输入/输出: 2.如果该数据需要作为主键key使用 ...
- Hadoop-MapReduce之自定义数据类型
以下是自定义的一个数据类型,有两个属性,一个是名称,一个是开始点(可以理解为单词和单词的位置) MR程序就不写了,请看WordCount程序. package cn.genekang.hadoop.m ...
- Hadoop自定义类型处理手机上网日志
job提交源码分析 在eclipse中的写的代码如何提交作业到JobTracker中的哪?(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 con ...
- 通过SQL Server自定义数据类型实现导入数据
写在前面 在看同事写的代码时看到了SQL Server中可以自定义数据类型,而且定义的是DataTable类型的数据类型. 后我想起了以前我们导入数据时要么是循环insert写入,要么是SqlBulk ...
- OSG 自定义数据类型 关键帧动画
OSG 自定义数据类型 关键帧动画 转自:http://blog.csdn.net/zhuyingqingfen/article/details/12651017 /* 1.创建一个AnimManag ...
- Oracle存储过程-自定义数据类型,集合,遍历取值
摘要 Oracle存储过程,自定义数据类型,集合,遍历取值 目录[-] 0.前言 1.Packages 2.Packages bodies 3.输出结果 0.前言 在Oracle的存储过程中,可能会遇 ...
- eclipse 提交作业到JobTracker Hadoop的数据类型要求必须实现Writable接口
问:在eclipse中的写的代码如何提交作业到JobTracker中的哪?答:(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 connect() ...
- Oracle自定义数据类型 1
原文 oracle 自定义类型 type / create type 一 Oracle中的类型 类型有很多种,主要可以分为以下几类: 1.字符串类型.如:char.nchar.varchar2.nva ...
随机推荐
- 使用第三方工具连接docker数据库
一.背景 为了把测试环境迁移至docker上,我在centos7上安装了docker,具体安装方法可参考<CentOS7下安装docker>本文不再论述.有些同学可能会有疑问,为什么要 ...
- PG进程结构和内存结构
本文主要介绍PostgreSQL数据库(后文简称PG)进程结构和内存结构,物理结构将在后续继续整理分享. 上图描述了PG进程结构.内存结构和部分物理结构的内容.图中的内容包含了两个部分: PG ...
- 设置Vim编辑器里Tab的长度,行号
使用Vim编辑器写脚本时,经常会遇到多重循环语句,习惯上会用tab键来补齐.这时设置tab键占用的长度,可以调节界面的松紧度,使其达到令人满意的效果. 在针对个别用户和所有用户来设置时,与编辑SSH相 ...
- javascript--淘宝页面的放大镜效果
放大镜效果需求: 鼠标放入原图中,会出现一个黄色的遮盖层和一个放大的图片,鼠标移动时候,遮盖层会跟着鼠标一起移动,同时放大的图片会跟着一起移动. 实现过程: 1.鼠标移入,遮盖层和大图片显示 2.鼠标 ...
- 【Linux磁盘优化管理--RAID和LVM】
在现阶段的企业环境中,为了数据的安全性及完整性必须要有一个合理的存储方案.面对着每秒可能产生超过几TB的数据,考虑到磁盘能不能实现 热冗余,及扩容,缩容.Linux给出了RAID(磁盘阵列)以及LVM ...
- docker 启动 nginx 访问不了的问题
使用版本:nginx version: nginx/1.13.8 正使用docker启动nginx容器的时候,一切都很正常,容器也起来了 docker run -dit -p 80:80 --name ...
- vertical-align垂直居中
<div id="content"> <div id="weizi"> 锄禾日当午,<br> 汗滴禾下土.<br> ...
- springcloud生态图
springcloud生态图
- 使用NPOI快速导出导入Excel
这两天做项目需要导入导出EXCEL,是基于NPOI的封装,设计思路是使用DataTable,然后导出一个和DataTable一模一样的Excel表出来 github地址:https://github. ...
- queue消息队列
class queue.Queue(maxsize=0) #先入先出 class queue.LifoQueue(maxsize=0) #last in fisrt out class queue. ...