集成方法 Ensemble
一、bagging
用于基础模型复杂、容易过拟合的情况,用来减小 variance(比如决策树)。基础模型之间没有太多联系(相对于boosting),训练可以并行。但用 bagging 并不能有助于把数据拟合的更准(那是要减小 bias)。
每次训练一个基础模型,都从 N 条训练数据中有放回的随机抽取出 N' 条作为训练集(虽然一般 N = N',但由于是有放回的抽,所以具体的数据还是不同的)。

模型做预测的时候用 average(回归)或者 voting(分类)。
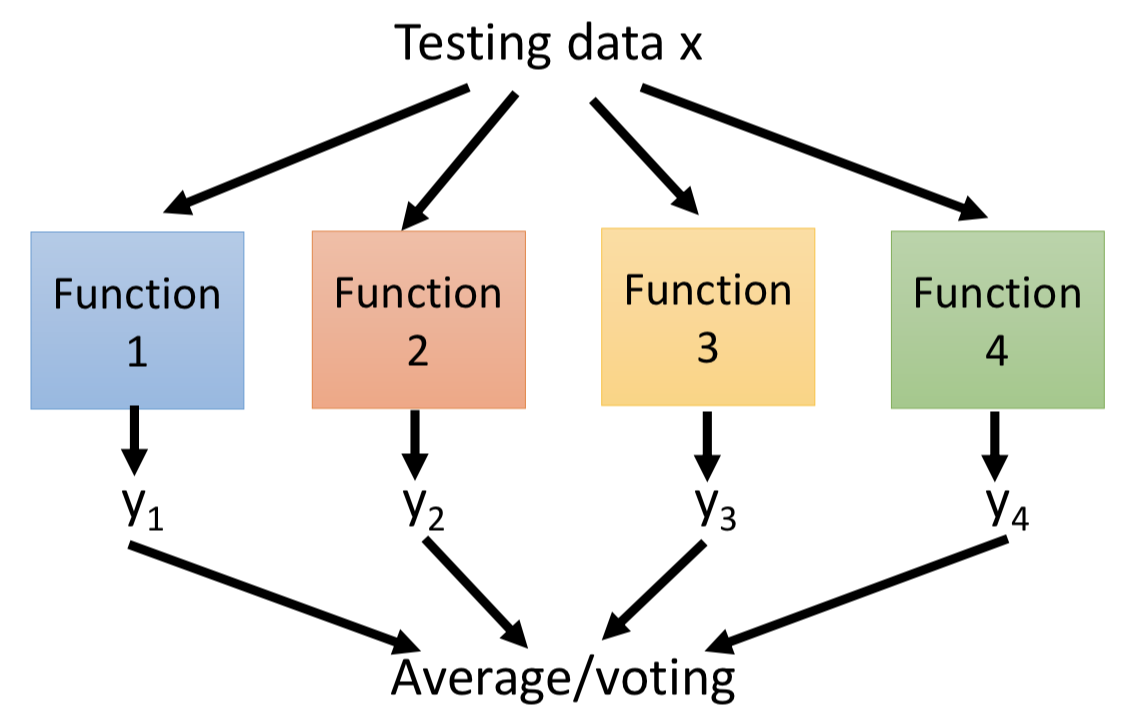
Out-of-bag validation:
用 bagging 方法不一定要把训练数据切分成训练集和验证集。因为每轮随机采样都会有一部分数据没有被采样到,可以用这部分数据来验证模型的泛化能力。
例如,训练基础模型的数据情况如下表

那就可以用 f2+f4 在 x1 上测试;f2+f3 在 x2 上测试;... ;以此类推。
Random Forest:对 decision tree 的 bagging
特点:
1. 使用 CART 决策树作为基础模型。
2. 只是有放回的 resample 训练数据是不够的(只这样做的话,得到每棵树都会差不多)。—— 每次分裂的时候随机限制一些特征不能用(在剩下的 p' 维特征中选择最优特征进行 split),p' 越小意味着得到的决策树模型鲁棒性越好(但同时对训练数据的拟合肯定也会变差),相当于 variance会变小但 bias 会变大,通过交叉验证选择一个合适的 p'。
3. 对单棵树不剪枝,以此来减小单棵树的 bias(让其“专精于”那一部分特征,所以 RF 中的决策树比较深),再借助 bagging 减小整体模型的variance(相当于从不同的角度解决问题)。
推广:Isolation Forest 用于异常检测
类似 Random Forest ,不同点:
1. 采样个数 N' 远小于训练样本个数 N。因为只需要部分样本就能够检测出异常点了。
2. 建立决策树时,随机选择特征 + 随机选择阈值来 split 。
3. 最大决策树深度选择一个比较小的值,原因同 1 。
对于测试样本 x,把其拟合到 T 棵决策树,计算该样本的叶子结点深度 ht(x),进一步计算出平均深度 h(x)。样本点是异常的概率为:
s(x, N) = 2 -h(x)/c(N) ; 其中 c(N) = 2log(N-1) + ξ - 2(N-1)/N , ξ 为欧拉常数。取值范围在[0, 1] ,越大越可能是异常点。
二、boosting
强力的保证:只要基础分类器能够在训练集上实现小于 50% 的错误率,使用 boosting 就能在训练集上实现 0% 错误率。
基础模型的训练是有顺序的(新的基础模型去补强已有的基础模型)。
怎么实现在不同的训练集上训练模型?
1. resampling
2. reweighting
3. 实际应用的时候给样本不同的权重系数就行了。
Adaboost
主要思想:在让 f1(x) 的分类效果变成随机的新的训练集上训练 f2(x) ;... ;以此类推训练新的基础分类器,综合起来就是整体分类器。
怎么做?
在训练集上训练 f1(x) 得到小于 0.5 的错误率;

改变训练样本的权重参数 u ,令 f1(x) 的错误率等于 0.5 ;

在新的训练集上训练 f2(x) 得到小于 0.5 的错误率;...
具体怎么求解新的样本参数 u ?
初始化 u1 = [1, 1, ..., 1]T,N维向量。如果第 i 个样本 xi 被 ft(x) 正确分类,就减小其权重参数 ui (除以dt);反之,如果被分错就增大 ui (乘dt)。
d 的计算也很简单:

dt = ( (1 - εt)/εt )1/2 ,由于前提是 ft(x) 的错误率一定小于 0.5,所以 d > 1。
统一乘除两种情况的形式:令 αt = log dt ;乘 dt 等价于乘 exp(αt),除以 dt 等价于乘 exp(-αt)
想办法把负号和分类情况联系起来,最后结果为:
ut+1i = uti * exp(-yi * ft(xi) * αt )
得到 T 个基础分类器后,综合模型 H(x) = sign(Σ αt * ft(x)),sum for t = 1, 2, ..., T。为什么要做 weighted sum 呢?错误率低的 ft 对应的 αt 比较大,对最后结果影响就更大。
就完事了
证明 Adaboost 能够在训练集上实现 0% 的错误率
计算 H(x) 的错误率,发现其存在上界 exp( -yi * g(xi) )

等价于证明上界会越来越小。
设 Zt 是训练 ft 的权重参数之和,可以得到 ZT+1 的表达式,发现exp里面正好出现了g(x) = Σ αt * ft(x)

所以,T个基础分类器构成的模型在训练集的错误率上界,就等于训练第 T+1 个基础分类器的样本权重参数的平均值。
等价于证明训练样本参数的平均值会越来越小。

根据 Z 的递推公式,发现 Z 是随 t 单调减,得证。
margin

Boosting 的一般形式:

定义优化目标为刚才求解出来的错误率上界:

怎么实现这个优化过程呢? —— 用gradient descent
Gradient Boosting
L 对函数 g 求梯度,得到更新公式

要找到一个 ft(x) ,乘上权重 αt 后加到 gt-1(x) 里面,和梯度下降求解得到的对 g(x) 的更新一样,那就让 ft(x) 和负梯度方向一致,也即内积越大越好。(先看方向。整体损失函数的负梯度拟合第 t 轮的损失值)
所以转换后的优化目标如下,相当于最小化 ft(x) 在权重参数为 ut 的训练集上的误差:( Adaboost 中的训练 ft 的步骤)
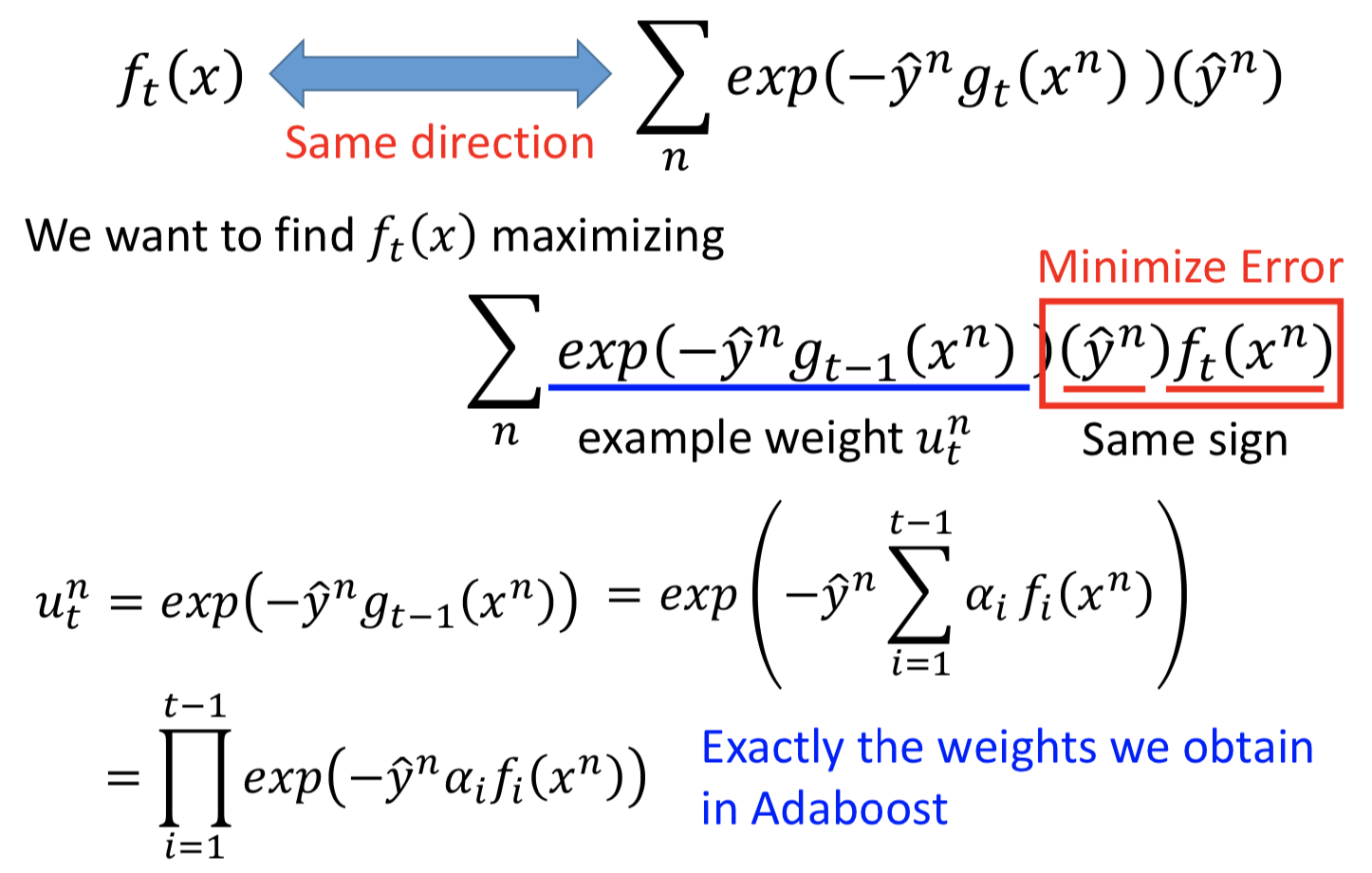
而 αt 如何确定呢?
令 L 对 αt 偏导数为 0 得到的解, 和Adaboost 中的定义是相同的。

三、stacking
各做各的,然后把前面已经有的模型输出作为最后一个 layer 的 new features,而且训练数据要分成两个部分,一部分用来训练前面的系统,另一部分用来训练 Final classifier。

集成方法 Ensemble的更多相关文章
- 【机器学习实战】第7章 集成方法 ensemble method
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 深度学习的集成方法——Ensemble Methods for Deep Learning Neural Networks
本文主要参考Ensemble Methods for Deep Learning Neural Networks一文. 1. 前言 神经网络具有很高的方差,不易复现出结果,而且模型的结果对初始化参数异 ...
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 机器学习——打开集成方法的大门,手把手带你实现AdaBoost模型
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第25篇文章,我们一起来聊聊AdaBoost. 我们目前为止已经学过了好几个模型,光决策树的生成算法就有三种.但是我们每 ...
- 常用的模型集成方法介绍:bagging、boosting 、stacking
本文介绍了集成学习的各种概念,并给出了一些必要的关键信息,以便读者能很好地理解和使用相关方法,并且能够在有需要的时候设计出合适的解决方案. 本文将讨论一些众所周知的概念,如自助法.自助聚合(baggi ...
- 【Ensemble methods】组合方法&集成方法
机器学习的算法中,讨论的最多的是某种特定的算法,比如Decision Tree,KNN等,在实际工作以及kaggle竞赛中,Ensemble methods(组合方法)的效果往往是最好的,当然需要消耗 ...
随机推荐
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置 经过分析只有画线的page在变化 上代码: items.py import scrapy class ImoocItem(scrapy.It ...
- kuangbin专题 专题一 简单搜索 Fire! UVA - 11624
题目链接:https://vjudge.net/problem/UVA-11624 题意:一个迷宫,可能有一个或者多个地方着火了,每过1个时间消耗,火会向四周蔓延,问Joe能不能逃出迷宫,只要走出迷宫 ...
- Java 集合类Hashmap
一.HashMap 简介 HashMap在程序员的开发过程中是一个十分常用的集合类,它是一个以键值对形式存在的集合类, 在开发中我们可以利用的它的一个key存在即替换的特性,实现一个更新的去重的操作. ...
- 聊聊Java String.intern 背后你不知道的知识
Java的 String类有个有意思的public方法: public String intern() 返回标准表示的字符串对象.String类维护私有字符串池. 调用此方法时,如果字符串池已经包含等 ...
- Java集合对象比对
1. 场景描述 通过java代码从外围接口中获取数据并落地,已经存在的不落地,不存在的落地,因有部分字段变化是正常的,只需比对3个字段相同即为相同. 2. 解决方案 设置定时任务(三个标签完成spri ...
- 20141209-基本概念-BlogEngine.NET(1)-笔记
最近在读BlogEngine.NET3.1源代码,希望能坚持到底吧. 刚接触源代码,没有思路,于是读了14篇关于BlogEngine.Net1.4.5的系列博客,地址:http://www.cnblo ...
- 学习2:总结# 1.while # 2.字符串格式化 # 3.运算符 # 4.编码初始
目录 1.while循环 -- 死循环 2.字符串格式化: 3.运算符 4.编码 1.while循环 -- 死循环 while 条件: 循环体 打断死循环: break -- 终止当前循环 改变条件 ...
- Scala 函数式编程(一) 什么是函数式编程?
为什么我们需要学习函数式编程?或者说函数式编程有什么优势?这个系列中我会用 scala 给你讲述函数式编程中的优势,以及一些函数式的哲学.不懂 scala 也没关系,scala 和 java 是类似的 ...
- 个人永久性免费-Excel催化剂功能第54波-批量图片导出,调整大小等
图片作为一种数据存在,较一般的存放在Excel单元格或其他形式存在的文本数据,对其管理更为不易,特别是仅有Excel原生的简单的插入图片功能时,Excel催化剂已全面覆盖图片数据的使用场景,无论是图片 ...