分布式日志收集系统 —— Flume
一、Flume简介
Apache Flume 是一个分布式,高可用的数据收集系统。它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。Flume 分为 NG 和 OG (1.0 之前) 两个版本,NG 在 OG 的基础上进行了完全的重构,是目前使用最为广泛的版本。下面的介绍均以 NG 为基础。
二、Flume架构和基本概念
下图为 Flume 的基本架构图:
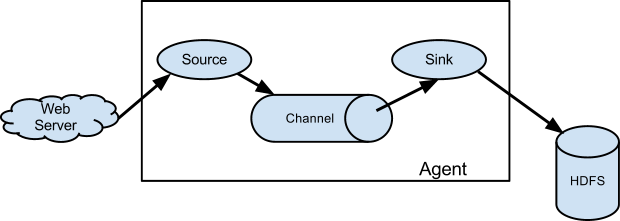
2.1 基本架构
外部数据源以特定格式向 Flume 发送 events (事件),当 source 接收到 events 时,它将其存储到一个或多个 channel,channe 会一直保存 events 直到它被 sink 所消费。sink 的主要功能从 channel 中读取 events,并将其存入外部存储系统或转发到下一个 source,成功后再从 channel 中移除 events。
2.2 基本概念
1. Event
Evnet 是 Flume NG 数据传输的基本单元。类似于 JMS 和消息系统中的消息。一个 Evnet 由标题和正文组成:前者是键/值映射,后者是任意字节数组。
2. Source
数据收集组件,从外部数据源收集数据,并存储到 Channel 中。
3. Channel
Channel 是源和接收器之间的管道,用于临时存储数据。可以是内存或持久化的文件系统:
Memory Channel: 使用内存,优点是速度快,但数据可能会丢失 (如突然宕机);File Channel: 使用持久化的文件系统,优点是能保证数据不丢失,但是速度慢。
4. Sink
Sink 的主要功能从 Channel 中读取 Evnet,并将其存入外部存储系统或将其转发到下一个 Source,成功后再从 Channel 中移除 Event。
5. Agent
是一个独立的 (JVM) 进程,包含 Source、 Channel、 Sink 等组件。
2.3 组件种类
Flume 中的每一个组件都提供了丰富的类型,适用于不同场景:
Source 类型 :内置了几十种类型,如
Avro Source,Thrift Source,Kafka Source,JMS Source;Sink 类型 :
HDFS Sink,Hive Sink,HBaseSinks,Avro Sink等;Channel 类型 :
Memory Channel,JDBC Channel,Kafka Channel,File Channel等。
对于 Flume 的使用,除非有特别的需求,否则通过组合内置的各种类型的 Source,Sink 和 Channel 就能满足大多数的需求。在 Flume 官网 上对所有类型组件的配置参数均以表格的方式做了详尽的介绍,并附有配置样例;同时不同版本的参数可能略有所不同,所以使用时建议选取官网对应版本的 User Guide 作为主要参考资料。
三、Flume架构模式
Flume 支持多种架构模式,分别介绍如下
3.1 multi-agent flow

Flume 支持跨越多个 Agent 的数据传递,这要求前一个 Agent 的 Sink 和下一个 Agent 的 Source 都必须是 Avro 类型,Sink 指向 Source 所在主机名 (或 IP 地址) 和端口(详细配置见下文案例三)。
3.2 Consolidation
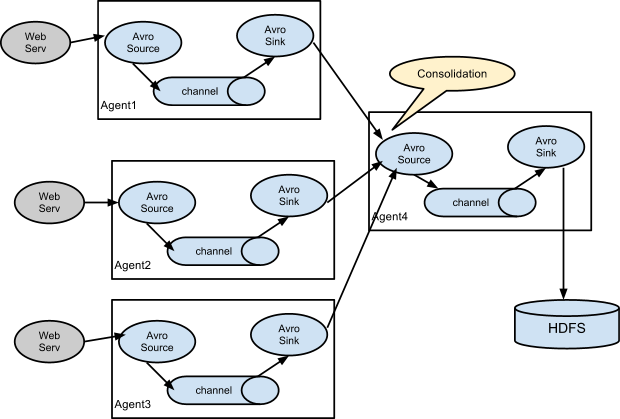
日志收集中常常存在大量的客户端(比如分布式 web 服务),Flume 支持使用多个 Agent 分别收集日志,然后通过一个或者多个 Agent 聚合后再存储到文件系统中。
3.3 Multiplexing the flow
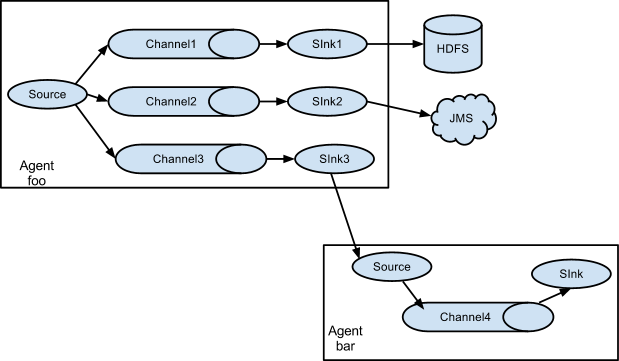
Flume 支持从一个 Source 向多个 Channel,也就是向多个 Sink 传递事件,这个操作称之为 Fan Out(扇出)。默认情况下 Fan Out 是向所有的 Channel 复制 Event,即所有 Channel 收到的数据都是相同的。同时 Flume 也支持在 Source 上自定义一个复用选择器 (multiplexing selector) 来实现自定义的路由规则。
四、Flume配置格式
Flume 配置通常需要以下两个步骤:
- 分别定义好 Agent 的 Sources,Sinks,Channels,然后将 Sources 和 Sinks 与通道进行绑定。需要注意的是一个 Source 可以配置多个 Channel,但一个 Sink 只能配置一个 Channel。基本格式如下:
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>- 分别定义 Source,Sink,Channel 的具体属性。基本格式如下:
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>五、Flume的安装部署
为方便大家后期查阅,本仓库中所有软件的安装均单独成篇,Flume 的安装见:
六、Flume使用案例
介绍几个 Flume 的使用案例:
- 案例一:使用 Flume 监听文件内容变动,将新增加的内容输出到控制台。
- 案例二:使用 Flume 监听指定目录,将目录下新增加的文件存储到 HDFS。
- 案例三:使用 Avro 将本服务器收集到的日志数据发送到另外一台服务器。
6.1 案例一
需求: 监听文件内容变动,将新增加的内容输出到控制台。
实现: 主要使用 Exec Source 配合 tail 命令实现。
1. 配置
新建配置文件 exec-memory-logger.properties,其内容如下:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources属性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c
#将sources与channels进行绑定
a1.sources.s1.channels = c1
#配置sink
a1.sinks.k1.type = logger
#将sinks与channels进行绑定
a1.sinks.k1.channel = c1
#配置channel类型
a1.channels.c1.type = memory2. 启动
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/exec-memory-logger.properties \
--name a1 \
-Dflume.root.logger=INFO,console3. 测试
向文件中追加数据:

控制台的显示:

6.2 案例二
需求: 监听指定目录,将目录下新增加的文件存储到 HDFS。
实现:使用 Spooling Directory Source 和 HDFS Sink。
1. 配置
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources属性
a1.sources.s1.type =spooldir
a1.sources.s1.spoolDir =/tmp/logs
a1.sources.s1.basenameHeader = true
a1.sources.s1.basenameHeaderKey = fileName
#将sources与channels进行绑定
a1.sources.s1.channels =c1
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H/
a1.sinks.k1.hdfs.filePrefix = %{fileName}
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#将sinks与channels进行绑定
a1.sinks.k1.channel = c1
#配置channel类型
a1.channels.c1.type = memory2. 启动
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/spooling-memory-hdfs.properties \
--name a1 -Dflume.root.logger=INFO,console3. 测试
拷贝任意文件到监听目录下,可以从日志看到文件上传到 HDFS 的路径:
# cp log.txt logs/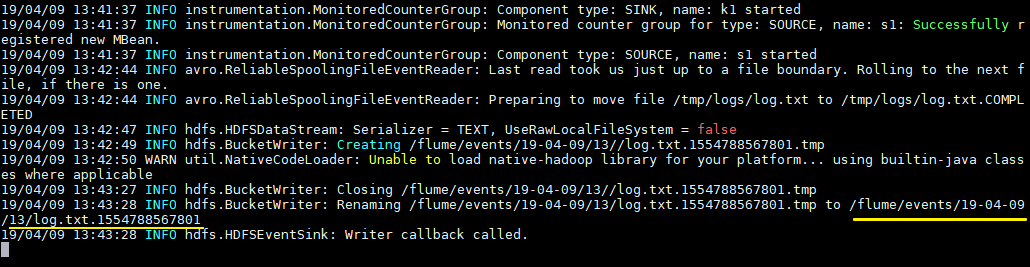
查看上传到 HDFS 上的文件内容与本地是否一致:
# hdfs dfs -cat /flume/events/19-04-09/13/log.txt.1554788567801
6.3 案例三
需求: 将本服务器收集到的数据发送到另外一台服务器。
实现:使用 avro sources 和 avro Sink 实现。
1. 配置日志收集Flume
新建配置 netcat-memory-avro.properties,监听文件内容变化,然后将新的文件内容通过 avro sink 发送到 hadoop001 这台服务器的 8888 端口:
#指定agent的sources,sinks,channels
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#配置sources属性
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /tmp/log.txt
a1.sources.s1.shell = /bin/bash -c
a1.sources.s1.channels = c1
#配置sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop001
a1.sinks.k1.port = 8888
a1.sinks.k1.batch-size = 1
a1.sinks.k1.channel = c1
#配置channel类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1002. 配置日志聚合Flume
使用 avro source 监听 hadoop001 服务器的 8888 端口,将获取到内容输出到控制台:
#指定agent的sources,sinks,channels
a2.sources = s2
a2.sinks = k2
a2.channels = c2
#配置sources属性
a2.sources.s2.type = avro
a2.sources.s2.bind = hadoop001
a2.sources.s2.port = 8888
#将sources与channels进行绑定
a2.sources.s2.channels = c2
#配置sink
a2.sinks.k2.type = logger
#将sinks与channels进行绑定
a2.sinks.k2.channel = c2
#配置channel类型
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 1003. 启动
启动日志聚集 Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/avro-memory-logger.properties \
--name a2 -Dflume.root.logger=INFO,console在启动日志收集 Flume:
flume-ng agent \
--conf conf \
--conf-file /usr/app/apache-flume-1.6.0-cdh5.15.2-bin/examples/netcat-memory-avro.properties \
--name a1 -Dflume.root.logger=INFO,console这里建议按以上顺序启动,原因是 avro.source 会先与端口进行绑定,这样 avro sink 连接时才不会报无法连接的异常。但是即使不按顺序启动也是没关系的,sink 会一直重试,直至建立好连接。
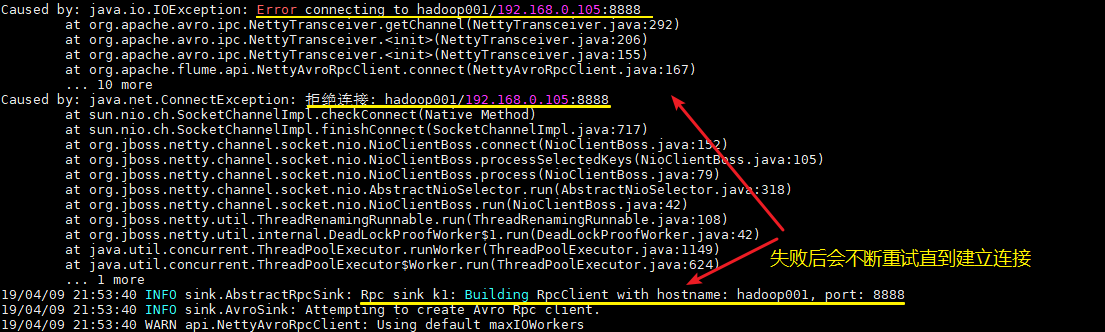
4.测试
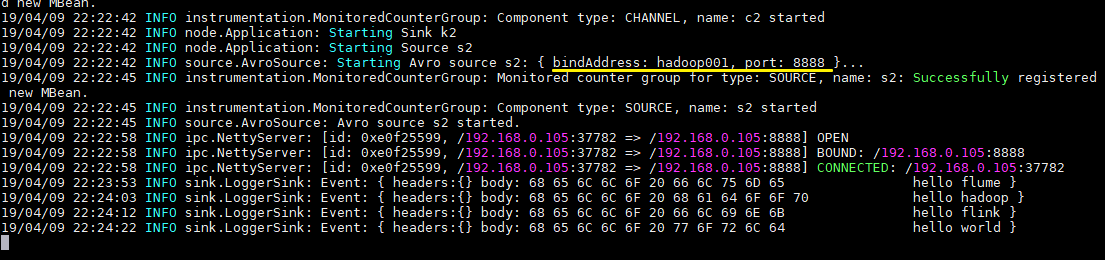
向文件 tmp/log.txt 中追加内容:

可以看到已经从 8888 端口监听到内容,并成功输出到控制台:
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
分布式日志收集系统 —— Flume的更多相关文章
- 分布式日志收集系统Apache Flume的设计详细介绍
问题导读: 1.Flume传输的数据的基本单位是是什么? 2.Event是什么,流向是怎么样的? 3.Source:完成对日志数据的收集,分成什么打入Channel中? 4.Channel的作用是什么 ...
- 分布式日志收集框架Flume
分布式日志收集框架Flume 1.业务现状分析 WebServer/ApplicationServer分散在各个机器上 想在大数据平台Hadoop进行统计分析 日志如何收集到Hadoop平台上 解决方 ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- 分布式日志收集系统- Cloudera Flume 介绍
Flume是Cloudera提供的日志收集系统,具有分布式.高可靠.高可用性等特点,对海量日志采集.聚合和传输, Flume支持在日志系统中定制各类数据发送方, 同时,Flume提供对数据进行 ...
- 分布式日志收集系统:Flume
Flume知识点: Event 是一行一行的数据 1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去. 2.flume里面有个核心概念,叫做agent.agent是一个java进程,运 ...
- Flume分布式日志收集系统
1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去.2.flume里面有个核心概念,叫做agent.agent是一个java进程,运行在日志收集节点.通过agent接收日志,然后暂存起 ...
- flume分布式日志收集系统操作
1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去. 2.flume里面有个核心概念,叫做agent.agent是一个java进程,运行在日志收集节点. 3.agent里面包含3个核心 ...
- 日志收集系统Flume及其应用
Apache Flume概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统.Flume 支持定制各类数据发送方,用于收集各类型数据:同时,Fl ...
- 学习笔记:分布式日志收集框架Flume
业务现状分析 WebServer/ApplicationServer分散在各个机器上,想在大数据平台hadoop上进行统计分析,就需要先把日志收集到hadoop平台上. 思考:如何解决我们的数据从其他 ...
随机推荐
- Linux基础之定时任务
30.1)什么是定时任务 定时任务命令是cond,crond就是计划任务,类似于我们平时生活中的闹钟,定点执行. 30.2)为什么要用crond 计划任务主要是做一些周期性的任务,比如凌晨3点定时备份 ...
- jsp的简介(2)
JSP(JavaServer Pages )是什么? JavaServer Pages(JSP)是一种支持动态内容开发的网页技术它可以帮助开发人员通过利用特殊的JSP标签,其中大部分以<%开始并 ...
- 第二章 jQuery框架使用准备
window常用属性: History:有关客户访问过的URL的信息 Location: 有关当前url的信息 常用方法: Confirm()将弹出一个确认对话框 open()在页面上弹出一个新的浏览 ...
- RFC 2544 性能测试
什么是RFC 2544?网络设备性能测试的一组指标,包括吞吐率.时延.丢包率.背靠背. * * * 吞吐率(Throughput). 定义:被测设备在不丢包的情况下,所能转发的最大数据流量.通常使用每 ...
- druid0.15.0安装方式
Druid0.15.0安装文档 1 集群规划 Master包含Coordinator和Overlord,4核16G*2: data包含Historical和MiddleManager,16核64G*3 ...
- iDevice取证的一大突破
近日手机取证领域传出令人震撼的消息,知名取证大厂Cellebrite宣称可破解任何版本,任何机型的iDevice,连最新的iPhone X也逃不过. 若真属实,代表着iOS的取证又重现光明.只是不确定 ...
- 又拍云叶靖:OpenResty 在又拍云存储中的应用
2019 年 7 月 6 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·上海站,又拍云平台开发部负责人叶靖在活动上做了<OpenRest ...
- Linux curl 命令详解
命令概要 该命令设计用于在没有用户交互的情况下工作. curl 是一个工具,用于传输来自服务器或者到服务器的数据.「向服务器传输数据或者获取来自服务器的数据」 可支持的协议有(DICT.FILE.FT ...
- JS中map()与forEach()的区别和用法
相同点: 1.都是循环遍历数组中的每一项 2.每次执行匿名函数都支持三个参数,参数分别为item(当前每一项),index(索引值),arr(原数组) 3.匿名函数中的this都是指向window 4 ...
- C++这么难,为什么还要学习C++呢?如何学?
在大多数开发或者准开发人员的认识中,C/C++ 是一门非常难的编程语言,很多人知道它的强大,但因为认为“难”造成的恐惧让很多人放弃. 这个世界本来就是残酷的,所以你不能怪C++向你展示了世界的本质 大 ...