EM算法和高斯混合模型GMM介绍
EM算法
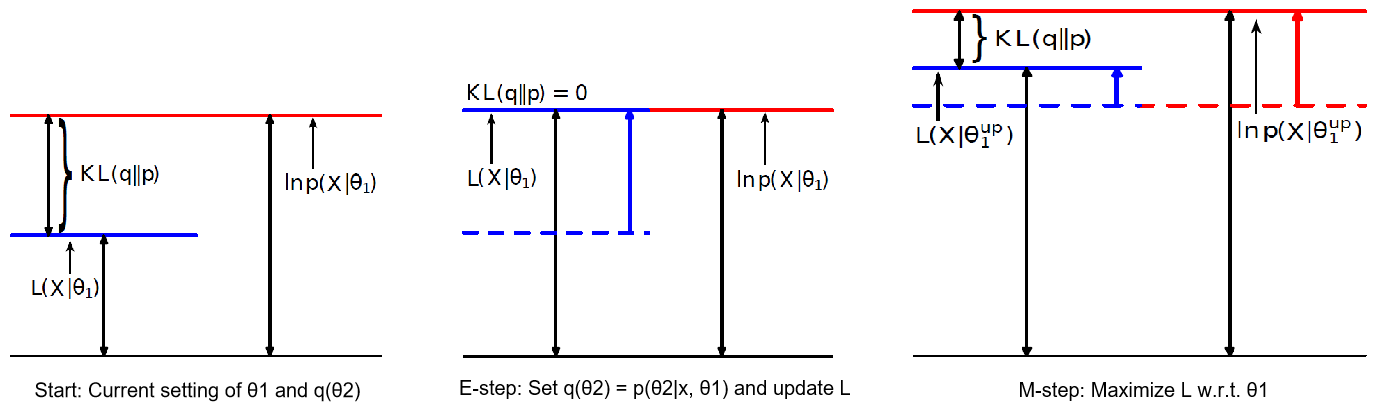
EM算法主要用于求概率密度函数参数的最大似然估计,将问题$\arg \max _{\theta_{1}} \sum_{i=1}^{n} \ln p\left(x_{i} | \theta_{1}\right)$转换为更加易于计算的$\sum_{i=1}^{n} \ln p\left(x_{i}, \theta_{2} | \theta_{1}\right)$,其中$\theta_2$可以取任意的先验分布$q(\theta_2)$。EM算法的推导过程如下:$$\begin{aligned} \ln p\left(x | \theta_{1}\right) &=\int q\left(\theta_{2}\right) \ln p\left(x | \theta_{1}\right) d \theta_{2}=\int q\left(\theta_{2}\right) \ln \frac{p\left(x, \theta_{2} | \theta_{1}\right)}{p\left(\theta_{2} | x, \theta_{1}\right)} d \theta_{2}=\int q\left(\theta_{2}\right) \ln \frac{p\left(x, \theta_{2} | \theta_{1}\right) q\left(\theta_{2}\right)}{p\left(\theta_{2} | x, \theta_{1}\right) q\left(\theta_{2}\right)} d \theta_{2} \\ &=\underbrace{\int q\left(\theta_{2}\right) \ln \frac{p\left(x, \theta_{2} | \theta_{1}\right)}{q\left(\theta_{2}\right)} d \theta_{2}}_{\text { define this to }\mathcal{L}\left(x,\theta_1\right)}+\underbrace{\int q\left(\theta_{2}\right) \ln \frac{q\left(\theta_{2}\right)}{p\left(\theta_{2} | x, \theta_{1}\right)} d \theta_{2}}_{\text { Kullback-Leibler divergence }} \end{aligned}$$利用凸函数的性质,$\text{KL divergence}=E\left[-\ln \frac{p\left(\theta_{2} | x, \theta_{1}\right)}{q\left(\theta_{2}\right)}\right]\geq{-\ln{E\left[\frac{p\left(\theta_{2} | x, \theta_{1}\right)}{q\left(\theta_{2}\right)}\right]}}=-\ln{1}=0$,当且仅当$q\left(\theta_{2}\right)=p\left(\theta_{2} | x, \theta_{1}\right)$时$\text{KL divergence}$取值为0。
基于以上推导,EM算法的计算流程如下:
给定初始值$\theta_1^{(0)}$,按以下步骤迭代至收敛(以第t+1步为例):
- E-step: 令$q_{t}\left(\theta_{2}\right)=p\left(\theta_{2} | x, \theta_{1}^{(t)}\right)$,则$\mathcal{L}_{t}\left(x, \theta_{1}\right)=\int q_{t}\left(\theta_{2}\right) \ln p\left(x, \theta_{2} | \theta_{1}\right) d \theta_{2}-\underbrace{\int q_{t}\left(\theta_{2}\right) \ln q_{t}\left(\theta_{2}\right) d \theta_{2}}_{\text { can ignore this term }}$
- M-step: 令$\theta_{1}^{(t+1)}=\arg \max _{\theta_{1}} \mathcal{L}_{t}\left(x, \theta_{1}\right)$
算法解释:
$$
\begin{aligned} \ln p\left(x | \theta_{1}^{(t)}\right) &=\mathcal{L}_{t}\left(x, \theta_{1}^{(t)}\right)+\underbrace{K L\left(q_t\left(\theta_{2}\right) \| p\left(\theta_{2} | x_{1}, \theta_{1}^{(t)}\right)\right)}_{=0 \text { by setting } q=p}\quad \leftarrow \text { E-step } \\ & \leq \mathcal{L}_{t}\left(x, \theta_{1}^{(t+1)}\right) \quad \leftarrow \text { M-step } \\ & \leq \mathcal{L}_{t}\left(x, \theta_{1}^{(t+1)}\right)+\underbrace{K L\left(q_{t}\left(\theta_{2}\right) \| p\left(\theta_{2} | x_{1}, \theta_{1}^{(t+1)}\right)\right)}_{>0 \text { because } q \neq p} \\ &=\ln p\left(x | \theta_{1}^{(t+1)}\right)\end{aligned}
$$
高斯混合模型GMM
高斯混合模型是一个用于聚类的概率模型,对于数据$\vec{x}_1,\vec{x}_2,\cdots,\vec{x}_n$中的任一数据$\vec{x}_i$,$c_i$表示$\vec{x}_i$被分配到了第$c_i$个簇中,并且$c_i\in\{1,2,\cdots,K\}$。模型定义如下:
- Prior cluster assignment: $c_{i} \stackrel{\text { iid }}{\sim}$ Discrete $(\vec{\pi}) \Rightarrow \operatorname{Prob}\left(c_{i}=k | \vec{\pi}\right)=\pi_{k}$
- Generate observation: $\vec{x}_i \sim N\left(\vec{\mu}_{c_{i}}, \Sigma_{c_{i}}\right)$
模型需要求解的就是先验概率$\vec{\pi}=(\pi_1,\pi_2,\cdots,\pi_K)$,各簇高斯分布的均值$\{\vec{\mu}_1,\vec{\mu}_2,\cdots,\vec{\mu}_K\}$以及协方差矩阵$\{\Sigma_1,\Sigma_2,\cdots,\Sigma_K\}$这些量。为了求解这些量,使用最大似然估计,定义需最大化的目标函数为
$$\sum_{i=1}^{n} \ln p\left(\vec{x}_{i} | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)\text{, where }\boldsymbol{\mu}=\{\vec{\mu}_1,\vec{\mu}_2,\cdots,\vec{\mu}_K\}\text{ and }\boldsymbol{\Sigma}=\{\Sigma_1,\Sigma_2,\cdots,\Sigma_K\}$$
利用EM算法求解上式的最大值,将上式写为$$\sum_{i=1}^{n} \ln p\left(\vec{x}_{i} | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)=\sum_{i=1}^{n} \underbrace{\sum_{k=1}^{K} q\left(c_{i}=k\right) \ln \frac{p\left(\vec{x}_{i}, c_{i}=k | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)}{q\left(c_{i}=k\right)}}_{\mathcal{L}}+\sum_{i=1}^n\underbrace{\sum_{k=1}^{K} q\left(c_{i}=k\right) \ln \frac{q\left(c_{i}=k\right)}{p\left(c_{i}=k | \vec{x}_{i}, \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)}}_{\text{KL divergence}}$$
- E-step: 根据贝叶斯法则,令$q_t\left(c_{i}=k\right)=p\left(c_{i}=k | \vec{x}_{i}, \vec{\pi}^{(t)}, \mu^{(t)}, \Sigma^{(t)}\right)\propto p\left(c_{i}=k | \vec{\pi}^{(t)}\right) p\left(\vec{x}_{i} | c_{i}=k, \boldsymbol{\mu}^{(t)}, \boldsymbol{\Sigma}^{(t)}\right)$,容易看出$$q_t\left(c_{i}=k\right)=\frac{\pi_{k}^{(t)} N\left(\vec{x}_{i} | \vec{\mu}_{k}^{(t)}, \Sigma_{k}^{(t)}\right)}{\sum_{j} \pi_{j}^{(t)} N\left(\vec{x}_{i} | \vec{\mu}_{j}^{(t)}, \Sigma_{j}^{(t)}\right)}$$
- M-step: $$\arg\max_{\vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}}\sum_{i=1}^{n} \sum_{k=1}^{K} q_t\left(c_{i}=k\right)\ln p\left(\vec{x}_{i}, c_{i}=k | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)=\arg\max_{\vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}}\sum_{i=1}^{n} \sum_{k=1}^{K} q_t\left(c_{i}=k\right)\left[\ln \pi_k+\ln N\left(\vec{x}_{i} | \vec{\mu}_{k}, \Sigma_{k}\right)\right]$$可以得出$\pi_{k}^{(t+1)}=\frac{\sum_{i=1}^{n}q_t\left(c_i=k\right)}{\sum_{j=1}^{K}\sum_{i=1}^{n}q_t\left(c_i=j\right)}=\frac{\sum_{i=1}^{n}q_t\left(c_i=k\right)}{n}, \quad\vec{\mu}_{k}^{(t+1)}=\frac{\sum_{i=1}^{n} q_t\left(c_i=k\right) \vec{x}_{i}}{\sum_{i=1}^{n}q_t\left(c_i=k\right)}, \quad \Sigma_{k}^{(t+1)}=\frac{ \sum_{i=1}^{n} q_t\left(c_i=k\right)\left(\vec{x_{i}}-\vec{\mu}_{k}^{(t+1)}\right)\left(\vec{x}_{i}-\vec{\mu}_{k}^{(t+1)}\right)^{T}}{\sum_{i=1}^{n}q_t\left(c_i=k\right)}$
EM算法和高斯混合模型GMM介绍的更多相关文章
- 斯坦福大学机器学习,EM算法求解高斯混合模型
斯坦福大学机器学习,EM算法求解高斯混合模型.一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的 ...
- EM 算法求解高斯混合模型python实现
注:本文是对<统计学习方法>EM算法的一个简单总结. 1. 什么是EM算法? 引用书上的话: 概率模型有时既含有观测变量,又含有隐变量或者潜在变量.如果概率模型的变量都是观测变量,可以直接 ...
- 统计学习方法c++实现之八 EM算法与高斯混合模型
EM算法与高斯混合模型 前言 EM算法是一种用于含有隐变量的概率模型参数的极大似然估计的迭代算法.如果给定的概率模型的变量都是可观测变量,那么给定观测数据后,就可以根据极大似然估计来求出模型的参数,比 ...
- 机器学习算法总结(六)——EM算法与高斯混合模型
极大似然估计是利用已知的样本结果,去反推最有可能(最大概率)导致这样结果的参数值,也就是在给定的观测变量下去估计参数值.然而现实中可能存在这样的问题,除了观测变量之外,还存在着未知的隐变量,因为变量未 ...
- 机器学习第三课(EM算法和高斯混合模型)
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一.说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值. ...
- EM算法求高斯混合模型參数预计——Python实现
EM算法一般表述: 当有部分数据缺失或者无法观察到时,EM算法提供了一个高效的迭代程序用来计算这些数据的最大似然预计.在每一步迭代分为两个步骤:期望(Expectation)步骤和最大化( ...
- 贝叶斯来理解高斯混合模型GMM
最近学习基础算法<统计学习方法>,看到利用EM算法估计高斯混合模型(GMM)的时候,发现利用贝叶斯的来理解高斯混合模型的应用其实非常合适. 首先,假设对于贝叶斯比较熟悉,对高斯分布也熟悉. ...
- 6. EM算法-高斯混合模型GMM+Lasso详细代码实现
1. 前言 我们之前有介绍过4. EM算法-高斯混合模型GMM详细代码实现,在那片博文里面把GMM说涉及到的过程,可能会遇到的问题,基本讲了.今天我们升级下,主要一起解析下EM算法中GMM(搞事混合模 ...
- 5. EM算法-高斯混合模型GMM+Lasso
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-GMM代码实现 5. EM算法-高斯混合模型+Lasso 1. 前言 前面几篇博文对EM算法和G ...
随机推荐
- Centos6 samba服务配置
1.在阿里虚拟机中配置包源 在ecs的 /etc/yum.repos.d 创建个 alios.repo,内容如下 [alios.$releasever.base.$basearch] name=al ...
- 简单的scrapy实例
前天实验室的学长要求写一个简单的scrapy工程出来,之前也多少看了点scrapy的知识,但始终没有太明白,刚好趁着这个机会,加深一下对scrapy工作流程的理解.由于临近期末,很多作业要做(其实.. ...
- 渐进式web应用开发---service worker (二)
阅读目录 1. 创建第一个service worker 及环境搭建 2. 使用service worker 对请求拦截 3. 从web获取内容 4. 捕获离线请求 5. 创建html响应 6. 理解 ...
- jmeter分析性能报告时的误区
概述 我们用jmeter做性能测试,必然需要学会分析测试报告.但是初学者常常因为对概念的不清晰,最后被测试报告带到沟里去. 常见的误区 分析响应时间全用平均值 响应时间不和吞吐量挂钩 响应时间和吞吐量 ...
- 利用jenkins实现自动构建、部署,提升团队开发效率
一大早就被群里的同学刷银川下雪的消息,看着我都发冷,突觉一阵凉风裹身,是不是该考虑秋裤了. 偏离主题,正文走起...... 使用jenkins目标:利用其结合maven完成自动构建,并部署到tomca ...
- Bzoj 3813 奇数国 题解 数论+线段树+状压
3813: 奇数国 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 748 Solved: 425[Submit][Status][Discuss] ...
- ~~小练习:python的简易购物车~~
进击のpython 1,用户先给自己的账户充钱:比如先充3000元. 2,有如下的一个格式: goods = [{"name": "电脑", "pri ...
- wussUI v1.0.0小程序UI组件库 第一期开发已完成
经过了两个月不到的开发时间,我们phonycode团队顺利的发布了小程序的UI组件库 wuss-ui 的第一个版本.目前大体预览如下 介绍 wussUI 现在有大概27个组件左右, 目前基础组件都有了 ...
- 手机web app开发笔记
各位朋友好,最近自学开发了一个手机Web APP,“编程之路”,主要功能包括文章的展示,留言,注册登录,音乐播放等.为了记录学习心得,提高自己的编程水平,也许对其他朋友有点启发,特整理开发笔记如下. ...
- Shiro在Web环境下集成Spring的大致工作流程
1,Shiro提供了对Web环境的支持,其通过一个 ShiroFilter 入口来拦截需要安全控制的URL,然后进行相应的控制. ①配置的 ShiroFilter 实现类为:org.spri ...