统计学习方法c++实现之八 EM算法与高斯混合模型
EM算法与高斯混合模型
前言
EM算法是一种用于含有隐变量的概率模型参数的极大似然估计的迭代算法。如果给定的概率模型的变量都是可观测变量,那么给定观测数据后,就可以根据极大似然估计来求出模型的参数,比如我们假设抛硬币的正面朝上的概率为p(相当于我们假设了概率模型),然后根据n次抛硬币的结果就可以估计出p的值,这种概率模型没有隐变量,而书中的三个硬币的问题(先抛A然后根据A的结果决定继续抛B还是C),这种问题中A的结果就是隐变量,我们只有最后一个硬币的结果,其中的隐变量无法观测,所以这种无法直接根据观测数据估计概率模型的参数,这时就需要对隐变量进行估计,进而得到概率模型的参数,这里要注意,概率模型是已知的(已经假定好了),包括隐变量的模型也是假设好的,只是具体的参数未知,这时候就需要用EM算法求解未知参数,这里我用EM算法估计了高斯混合模型的参数,并用高斯混合模型实现了聚类,代码地址。
EM算法
EM算法中文名称是期望极大算法,EM是expectation maximization的缩写,从名字就可以窥视算法的核心,求期望,求极大。求谁的期望?求似然函数对隐变量的期望,所以,首先必须确定隐变量是什么。其次,对谁求极大?当然是求出概率模型的参数使得上一步的期望最大。算法如下:
输入:观测变量数据Y,隐变量数据Z(这里也是知道的?其实这里我的理解是,这里不是已知的,但是却是可以根据假设的隐变量的参数得到的),联合分布\(P(Y,Z|\theta)\), 条件分布\(P(Z|Y,\theta)\)
输出:模型参数\(\theta\)
E步:记\(\theta^{(i)}\)为第i次迭代参数\(\theta\)的估计值,i+1次迭代的E步, 计算
\(Q(\theta, \theta^{(i)})=E_Z[logP(Y,Z|\theta)|Y, \theta^{(i)}]=\sum_{Z}logP(Y,Z|\theta)P(Z|Y,\theta^{(i)})\)
M步,求使\(Q(\theta, \theta^{(i)})\)极大的\(\theta\),作为下一次迭代的\(\theta^{(i+1)}\)
重复2,3直到收敛
可以看出最重要的在于求\(Q(\theta, \theta^{(i)})\),那么为什么每一次迭代最大化\(\sum_{Z}logP(Y,Z|\theta)P(Z|Y,\theta^{(i)})\)就能使观测数据的似然函数最大(这是我们的最终目的)?这里书上有证明,很详细,就不赘述了。先看一下我们要最大化的极大似然函数,然后这里主要引用西瓜书中的解释来从理解EM算法:
\(L(\theta)=logP(Y|\theta)=log(\sum_ZP(Y,Z|\theta))=log(\sum_ZP(Y|Z,\theta)P(Z|\theta))\)
在迭代过程中,若参数\(\theta\)已知,则可以根据训练数据推断出最优隐变量Z的值(E步);反之,若Z的值已知,则可以方便的对参数\(\theta\)做极大似然估计(M步)。
可以看出就是一种互相计算,一起提升的过程。
这部分如果推导看不懂了,可以结合下面的二维高斯混合模型的EM算法来理解。
c++实现
这里我使用EM算法来估计高斯混合模型的参数来进行聚类,高斯混合模型还有一个很大的作用是进行前景提取,这里仅仅用二维混合高斯模型进行聚类。
代码结构
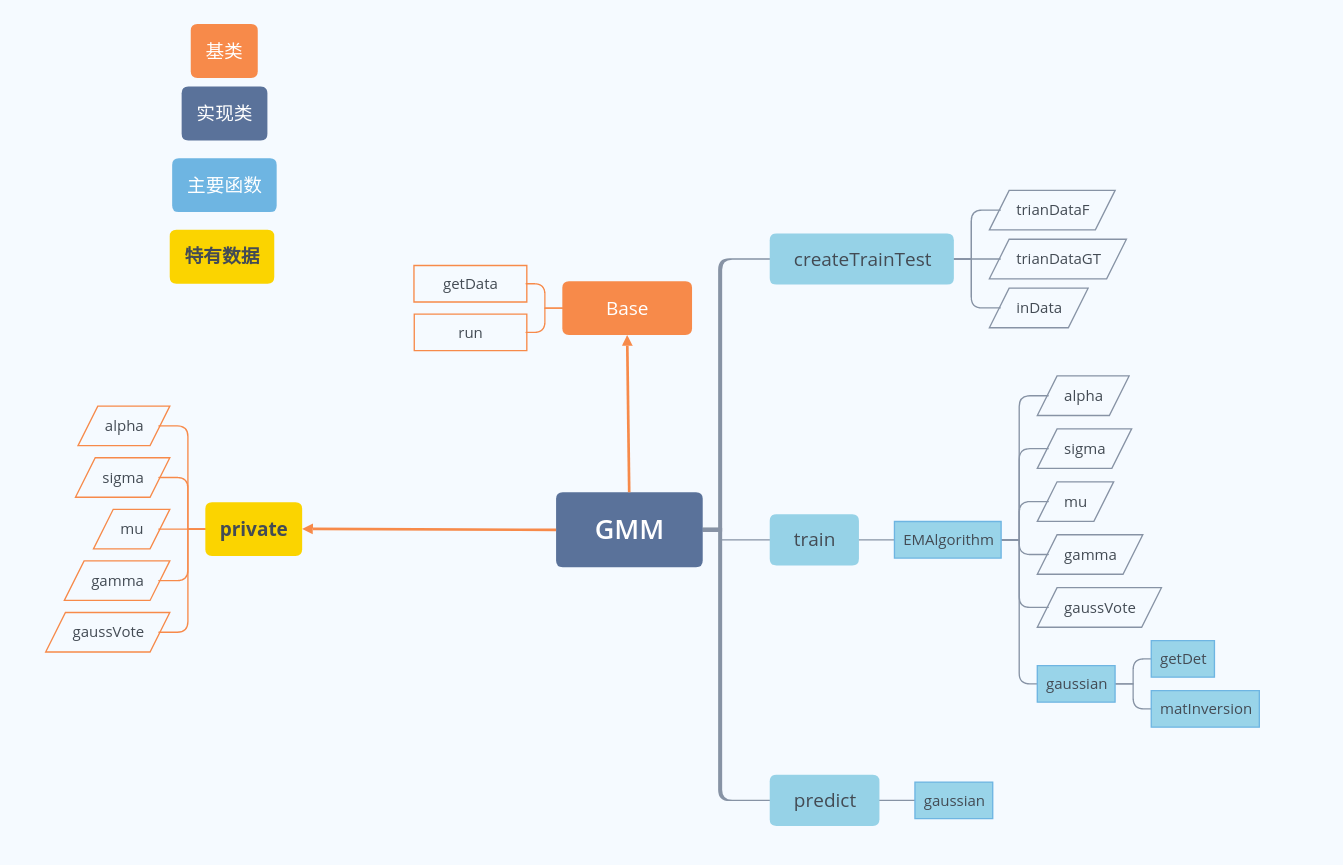
关键代码
这里实现起来其实没什么难点,难点在于推导参数的更新公式,详情参考西瓜书p206。
void GMM::EMAlgorithm(vector<double> &alphaOld, vector<vector<vector<double>>> &sigmaOld,
vector<vector<double>> &muOld) {
// compute gamma
for (int i = 0; i < trainDataF.size(); ++i) {
double probSum = 0;
for (int l = 0; l < alpha.size(); ++l) {
double gas = gaussian(muOld[l], sigmaOld[l], trainDataF[i]);
probSum += alphaOld[l] * gas;
}
for (int k = 0; k < alpha.size(); ++k) {
double gas = gaussian(muOld[k], sigmaOld[k], trainDataF[i]);
gamma[i][k] = alphaOld[k] * gas / probSum;
}
}
// update mu, sigma, alpha
for (int k = 0; k < alpha.size(); ++k) {
vector<double> muNew;
vector<vector<double>> sigmaNew;
double alphaNew;
vector<double> muNumerator;
double sumGamma = 0.0;
for (int i = 0; i < trainDataF.size(); ++i) {
sumGamma += gamma[i][k];
if (i==0) {
muNumerator = gamma[i][k] * trainDataF[i];
}
else {
muNumerator = muNumerator + gamma[i][k] * trainDataF[i];
}
}
muNew = muNumerator / sumGamma;
for (int i = 0; i < trainDataF.size(); ++i) {
if (i==0) {
auto temp1 = gamma[i][k]/ sumGamma * (trainDataF[i] - muNew);
auto temp2 = trainDataF[i] - muNew;
sigmaNew = vecMulVecToMat(temp1, temp2);
}
else {
auto temp1 = gamma[i][k] / sumGamma * (trainDataF[i] - muNew);
auto temp2 = trainDataF[i] - muNew;
sigmaNew = sigmaNew + vecMulVecToMat(temp1, temp2);
}
}
alphaNew = sumGamma / trainDataF.size();
mu[k] = muNew;
sigma[k] = sigmaNew;
alpha[k] = alphaNew;
}
}
总结
前面的代码一直用vector来实现向量,但是这里用到了矩阵,矩阵的相关计算都添加的计算函数。最正规的应该是写个类,实现矩阵运算,但是这里偷懒了,以后写代码一定要考虑周到,这样添添补补的太低效了。
统计学习方法c++实现之八 EM算法与高斯混合模型的更多相关文章
- 《统计学习方法》笔记九 EM算法及其推广
本系列笔记内容参考来源为李航<统计学习方法> EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计或极大后验概率估计.迭代由 (1)E步:求期望 (2)M步:求极大 组成,称 ...
- EM 算法求解高斯混合模型python实现
注:本文是对<统计学习方法>EM算法的一个简单总结. 1. 什么是EM算法? 引用书上的话: 概率模型有时既含有观测变量,又含有隐变量或者潜在变量.如果概率模型的变量都是观测变量,可以直接 ...
- 斯坦福大学机器学习,EM算法求解高斯混合模型
斯坦福大学机器学习,EM算法求解高斯混合模型.一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的 ...
- 机器学习第三课(EM算法和高斯混合模型)
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一.说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值. ...
- 机器学习算法总结(六)——EM算法与高斯混合模型
极大似然估计是利用已知的样本结果,去反推最有可能(最大概率)导致这样结果的参数值,也就是在给定的观测变量下去估计参数值.然而现实中可能存在这样的问题,除了观测变量之外,还存在着未知的隐变量,因为变量未 ...
- EM算法求高斯混合模型參数预计——Python实现
EM算法一般表述: 当有部分数据缺失或者无法观察到时,EM算法提供了一个高效的迭代程序用来计算这些数据的最大似然预计.在每一步迭代分为两个步骤:期望(Expectation)步骤和最大化( ...
- EM算法和高斯混合模型GMM介绍
EM算法 EM算法主要用于求概率密度函数参数的最大似然估计,将问题$\arg \max _{\theta_{1}} \sum_{i=1}^{n} \ln p\left(x_{i} | \theta_{ ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
随机推荐
- Apache Hadoop各版本发布的SVN地址
http://svn.apache.org/repos/asf/hadoop/common/tags
- Linux上安装ZooKeeper并设置开机启动(CentOS7+ZooKeeper3.4.10)
1下载Zookeeper 2安装启动测试 2.1上载压缩文件并解压 2.2新建 zookeeper配置文件 2.3安装JDK 2.4启动zookeeper 2.5查看zookeeper的状态 3将Zo ...
- 1.1 What Is This Book About(这本书是关于什么的)
CHAPTER 1 Preliminaries(预备知识) 1.1 What Is This Book About?(这本书是关于什么的) 这本书关心的是如何用Python对数据进行处理和清洗等操作. ...
- 1088. [SCOI2005]扫雷Mine【网格DP】
Description 相信大家都玩过扫雷的游戏.那是在一个n*m的矩阵里面有一些雷,要你根据一些信息找出雷来.万圣节到了 ,“余”人国流行起了一种简单的扫雷游戏,这个游戏规则和扫雷一样,如果某个格子 ...
- Loj #2256. 「SNOI2017」英雄联盟
题目 我就是个丝薄 如果要用\(dp_i\)表示凑出\(i\)的最小花费显然不可能的 之后大力猜想能凑出来的状态不会很多,我的暴力也告诉我不是很多,好像也确实不多的样子,大概\(4e4\)左右 但是我 ...
- Connection reset原因分析和解决方案
在使用HttpClient调用后台resetful服务时,“Connection reset”是一个比较常见的问题,有同学跟我私信说被这个问题困扰很久了,今天就来分析下,希望能帮到大家.例如我们线上的 ...
- Google 地图切片URL地址解析
一.Google地图切片的投影方式及瓦片索引机制 1.地图投影 Google地图采用的是Web墨卡托投影(如下图),为了方便忽略了两极变形较大的地区,把世界地图做成了一个边长等于赤道周长的正方形(赤道 ...
- c++—— 函数重载(Overroad)
5 函数重载(Overroad) 函数重载概念 1 函数重载概念 函数重载(Function Overload) 用同一个函数名定义不同的函数 当函数名和不同的参数搭配时函数的含义不同 2 函数重载的 ...
- request请求转换成对象。
1)前端post数据过来,key和val键值对会有很多,这个时候往后端进行插值的时候,最好将这些键值对转换成对象进行处理. 使用common-beanutils 来将前端传递过来的map直接转换成对象 ...
- smtp outlook邮件发送非授权码模式
1.起因:send fail SMTP AUTH extension not supported by server. 使用端口25 和587均失效出现此问题 首先前往outlook修改设置pop和I ...