urllib2爬取图片成功之后不能打开
经过8个小时的摸索,终于决定写下此随笔!
初学爬虫,准备爬取百度美女吧的图片,爬取图片之后发现打不开,上代码:
import urllib
import urllib2
from lxml import etree def loadPage(url):
"""
作用:根据url发送请求,获取响应文件
url:需要爬取的url地址
""" print('正在下载' )
ua_headers = {
"User-Agent": "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)"
}
request = urllib2.Request(url, headers= ua_headers)
html = urllib2.urlopen(request).read()
# print html
content = etree.HTML(html)
link_list = content.xpath('//div[@class="t_con cleafix"]/div[2]/div[1]/div[1]/a/@href')
for link in link_list:
fulurl = 'http://tieba.baidu.com' + link
loadImage(fulurl) def loadImage(url):
print '正在下载图片'
ua_headers = {
"User-Agent": "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)"
}
request = urllib2.Request(url, headers=ua_headers)
html = urllib2.urlopen(request).read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImage(link)
def writeImage(url):
"""
作用:将HTML内容写入到本地
html:服务器响应文件内容
"""
ua_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/35.0.1916.114 Safari/537.36',
'Cookie': 'AspxAutoDetectCookieSupport=1'
}
request = urllib2.Request(url,headers = ua_headers)
response =urllib2.urlopen(request)
image = response.read()
filename = url[-10:]
print('正在保存' + filename)
# print image
with open(filename, "wb") as f:
f.write(image)
print(filename + '已保存') def tiebaSpider(url, beginPage, endPage):
""" 作用:贴吧爬虫调度器。负责组合处理每个页面的url
url:贴吧url的前部分
beginPage:起始页
endPage:结束页
""" for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
fulurl = url + "&pn=" + str(pn)
loadPage(fulurl)
print('谢谢使用!') if __name__ == '__main__':
kw = raw_input('请输入需要爬取的贴吧名:')
beginPage = int(raw_input('请输入起始页:'))
endPage = int(raw_input('请输入结束页:')) url = 'http://tieba.baidu.com/f?'
key = urllib.urlencode({"kw": kw})
fulurl = url + key
tiebaSpider(fulurl,beginPage,endPage)
后来发现是writeImage()的参数跟函数体中调用的参数不一致导致的,
def writeImage(link):
"""
作用:将HTML内容写入到本地
html:服务器响应文件内容
"""
ua_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/35.0.1916.114 Safari/537.36',
'Cookie': 'AspxAutoDetectCookieSupport=1'
}
request = urllib2.Request(url,headers = ua_headers)
response =urllib2.urlopen(request)
image = response.read()
filename = url[-10:]
print('正在保存' + filename)
# print image
with open(filename, "wb") as f:
f.write(image)
print(filename + '已保存')
将参数改成跟函数体内一致后,爬取的图片总算可以正常查看了!下面看看成果吧: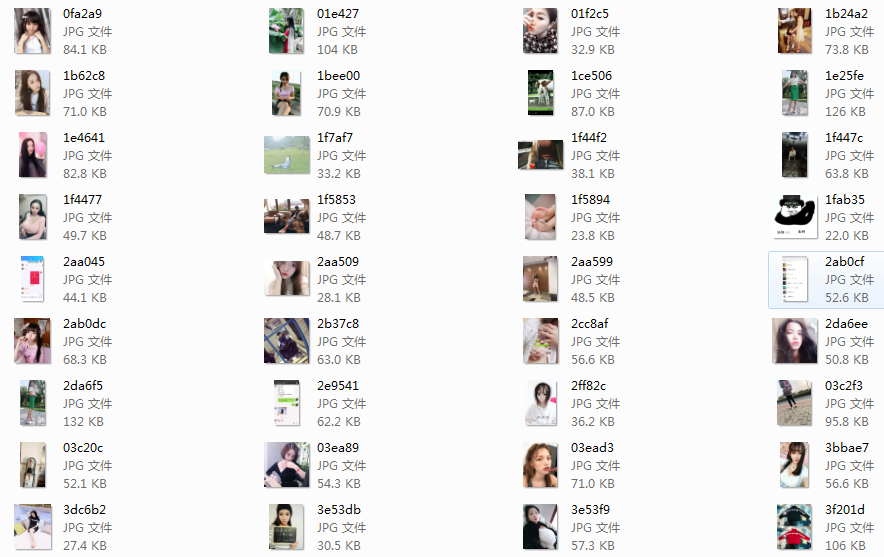
urllib2爬取图片成功之后不能打开的更多相关文章
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- Python 爬虫 爬取图片入门
爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 用户看到的网页实质是由 HTML 代码构成的,爬 ...
- C# 爬取图片
网络收集整理 爬取图片 引用AngleSharp NuGet 包 using AngleSharp; using System; using System.Collections.Generic; ...
- Java jsoup爬取图片
jsoup爬取百度瀑布流图片 是的,Java也可以做网络爬虫,不仅可以爬静态网页的图片,也可以爬动态网页的图片,比如采用Ajax技术进行异步加载的百度瀑布流. 以前有写过用Java进行百度图片的抓取, ...
- scrapy爬虫,爬取图片
一.scrapy的安装: 本文基于Anacoda3, Anacoda2和3如何同时安装? 将Anacoda3安装在C:\ProgramData\Anaconda2\envs文件夹中即可. 如何用con ...
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- scrapy 爬取图片
scrapy 爬取图片 1.scrapy 有下载图片的自带接口,不用我们在去实现 setting.py设置 # 保存log信息的文件名 LOG_LEVEL = "INFO" # L ...
随机推荐
- Linux:oracle11.2.0dbca静默建库
1.关闭防火墙 systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall ...
- React 练习项目,仿简书博客写作平台
Introduction 技术栈:react + redux + react-router + express + Nginx 练习点: redux 连接 react-router 路由跳转 scss ...
- Winform改变Textbox边框颜色
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- 常用高效 Java 工具类总结
一.前言 在Java中,工具类定义了一组公共方法,这篇文章将介绍Java中使用最频繁及最通用的Java工具类.以下工具类.方法按使用流行度排名,参考数据来源于Github上随机选取的5万个开源项目源码 ...
- .net core redis的全套操作
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). Redis支持主从同步.数据可以从主服务器向任意数 ...
- Python 标识符说明
在Python中,标识符有字母.数字.下划线组成 所有标识符都可以包括英文.数字.下划线,但不能以数字开头 Python标识符区分大小写 ※以下划线开头的标识符有特殊含义. 例如:以单下划线开头(_t ...
- Vue+ElementUI项目使用webpack输出MPA
目录 Vue+ElementUI项目使用webpack输出MPA 一. 需求分析 二. 原方案分析 三. 多页面改造3步走 四. 小结 Vue+ElementUI项目使用webpack输出MPA 示例 ...
- Gym - 101252H
题意略. 思路:二分.注意当利率高且m比较小的时候,每个月的偿还可能会大于本金,所以我们二分的右边界应该要设为2 * 本金. 详见代码: #include<bits/stdc++.h> # ...
- three.js实现球体地球城市模拟迁徙
概况如下:1.SphereGeometry实现自转的地球:2.THREE.ImageUtils.loadTexture加载地图贴图材质:3.THREE.Math.degToRad,Math.sin,M ...
- 各IDE代码自用开头模板
Pycharm #!/usr/bin/env python # -*- coding: utf-8 -*- # @version : 1.0 # @Time : ${DATE} ${TIME} # @ ...