scrapy爬虫,爬取图片
一、scrapy的安装:
本文基于Anacoda3,
Anacoda2和3如何同时安装?
将Anacoda3安装在C:\ProgramData\Anaconda2\envs文件夹中即可。
如何用conda安装scrapy?
安装了Anaconda2和3后,

如图,只有一个命令框,可以看到打开的时候:
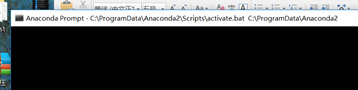
可以切到Anaconda3对应的路径下即可。
安装的方法:cmd中:conda install scrapy即可。
当然,可能会出现权限的问题,那是因为安装的文件夹禁止了读写。可以如图:
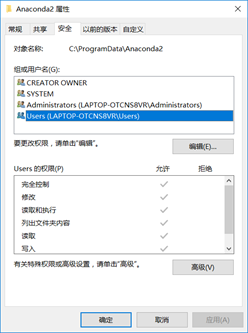
将权限都设为“允许“。
注意:此时虽然scapy安装上了,但是在cmd中输入scapy可能会不认,可以将安装scrapy.exe的路径添加到环境变量中。
二、scapy的简单使用
例子:爬取图片
1、 创建scrapy工程
譬如,想要创建工程名:testImage
输入:scrapy startproject testImage
即可创建该工程,按照cmd中提示的依次输入:
cd testImage
scrapy genspider getPhoto www.27270.com/word/dongwushijie/2013/4850.html
其中:在当前项目中创建spider,这仅仅是创建spider的一种快捷方法,该方法可以使用提前定义好的模板来生成spider,后面的网址是一个采集网址的集合,即为允许访问域名的一个判断。注意不要加http/https。
至此,可以在testImage\testImage\spiders中找到创建好的爬虫getPhoto.py,可以在此基础上进行修改。
2、创建爬虫
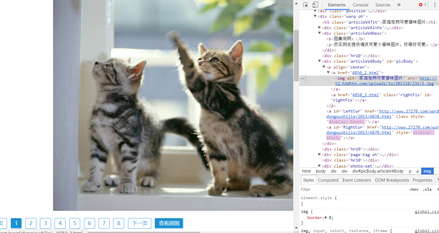
如图,可以在图片的位置右键,检查,查看源码,在图片所在的位置处,将xpath拷贝出来。
此时,可以找出图片的地址:
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.27270.com']
start_urls = ['http://www.27270.com/word/dongwushijie/2013/4850.html']
def parse(self, response):
urlImage = response.xpath('//*[@id="picBody"]/p/a[1]/img/@src').extract()
print(urlImage)
pass
此时,注意网络路径的正确书写,最后没有/,
http://www.27270.com/word/dongwushijie/2013/4850.html/
此时将4850.html 当作了目录,会出现404找不到路径的错误!
3、 下载图片
items.py:
class PhotoItem(scrapy.Item):
name = scrapy.Field()
imageLink = scrapy.Field()
pipelines.py:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class ImagePipeline(ImagesPipeline):
def get_media_requests(self,item,info):
image_link = item['imageLink']
yield scrapy.Request(image_link)
settings.py:
IMAGES_STORE = r"C:\Users\24630\Desktop\test"
另外,对于上面的网址,还需要ROBOTSTXT_OBEY = False
并且,访问该网址会出现302错误,这是一个重定向的问题,
MEDIA_ALLOW_REDIRECTS =True
设置该选项,就可以正确下载,但是下载的还是不对,问题不好解决。
当然在爬虫中,还要对items赋值:
from testImage import items
。。。 for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
三、 进一步爬取(读取下一页)
# -*- coding: utf-8 -*-
import scrapy
from testImage import items
class GetphotoSpider(scrapy.Spider):
name = 'getPhoto'
allowed_domains = ['www.wmpic.me']
start_urls = ['http://www.wmpic.me/93912']
def parse(self, response):
#//*[@id="content"]/div[1]/p/a[2]/img
urlImage = response.xpath('//*[@id="content"]/div[1]/p/a/img/@src').extract()
print(urlImage)
for urllink in urlImage:
item = items.PhotoItem()
item['imageLink'] = urllink
yield item ifnext = response.xpath('//*[@id="content"]/div[2]/text()').extract()[0]
# 当没有下一篇,即最后一页停止爬取
if("下一篇" in ifnext):
nextUrl = response.xpath('//*[@id="content"]/div[2]/a/@href').extract()[0]
url=response.urljoin(nextUrl)
yield scrapy.Request(url=url)
此时,便可以看到路径下的下载后的文件了。(由于该网址每页的图片所在的xpath都不一样,故下载的图片不全)
scrapy爬虫,爬取图片的更多相关文章
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- 使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件
目标网站:https://www.mn52.com/ 本文代码已上传至git和百度网盘,链接分享在文末 网站概览 目标,使用scrapy框架抓取全部图片并分类保存到本地. 1.创建scrapy项目 s ...
- Python 爬虫 爬取图片入门
爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 用户看到的网页实质是由 HTML 代码构成的,爬 ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy ImagesPipeline爬取图片资源
这是一个使用scrapy的ImagesPipeline爬取下载图片的示例,生成的图片保存在爬虫的full文件夹里. scrapy startproject DoubanImgs cd DoubanIm ...
- <scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目 dos窗口输入: scrapy startproject images360 cd images360 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) ...
随机推荐
- JS踩过的坑
一:DOM对象的查找 DOM的查找到的对象,除byID的之外,返回的都是一个数组,并不是DOM对象无法调用DOM对象的方法. 通过id查找: 因为id在一个HTML文件中唯一,因此查找到的只会是一个元 ...
- 21、List遍历时修改元素的问题
List迭代时修改元素的问题 请编写代码完成以下需求:判断一个List里面是否包含monkey,如果包含的话,向集合中添加1024这个字符串.‘ package com.monkey1024.list ...
- Shell基础-通配符
* - 通配符,代表任意字符 ? - 通配符,代表一个字符 # - 注释 | - 分隔两个管线命令的界定 ; - 连续性命令的界定 ~ - 用户的根目录 $ - 变量前需要加的变量值 ! - 逻辑运算 ...
- [转]QList内存释放
QList<T> 的释放分两种情况: 1.T的类型为非指针,这时候直接调用clear()方法就可以释放了,看如下测试代码 #include <QtCore/QCoreApplicat ...
- 技术分享:如何在PowerShell脚本中嵌入EXE文件
技术分享:如何在PowerShell脚本中嵌入EXE文件 我在尝试解决一个问题,即在客户端攻击中只使用纯 PowerShell 脚本作为攻击负荷.使用 PowerShell 运行恶意代码具有很多优点, ...
- PE文件结构及其加载机制
一.PE文件结构 PE即Portable Executable,是win32环境自身所带的执行体文件格式,其部分特性继承自Unix的COFF(Common Object File Format)文件格 ...
- 39 - 同步-异步-IO多路复用
目录 1 同步与异步 2 阻塞与非阻塞 3 什么是IO 3.1 内核态用户态 3.2 IO两个阶段 3.3 IO模型 3.3.1 同步阻塞IO 3.3.2 同步非阻塞IO 3.3.3 IO多路复用 3 ...
- 二、springcloud之熔断器hystrix
一.背景 雪崩效应 在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应.服务雪崩效应是一种因“服务提供者”的不可用导致“服 ...
- nvm npm node.js的关系
nvm npm node.js都是用来构建reactNativ的项目 nvm管理node.j和npm版本的 node.js管理reactNative开发中所需要的代码库的 npm管理对应node ...
- TF-搞不懂的TF矩阵加法
看谷歌的demo mnist,卷积后加偏执量的代码 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)h_pool1 = max_pool ...