Spark 学习笔记之 union/intersection/subtract
union/intersection/subtract:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testUnion(sc)
testIntersection(sc)
testSubtract(sc) } private def testSubtract(sc: SparkContext) = {
val rdd1 = sc.parallelize(1 to 3, 1)
val rdd2 = sc.parallelize(3 to 5, 1)
//返回在当前RDD中出现,并且不在另一个RDD中出现的元素,不去重。
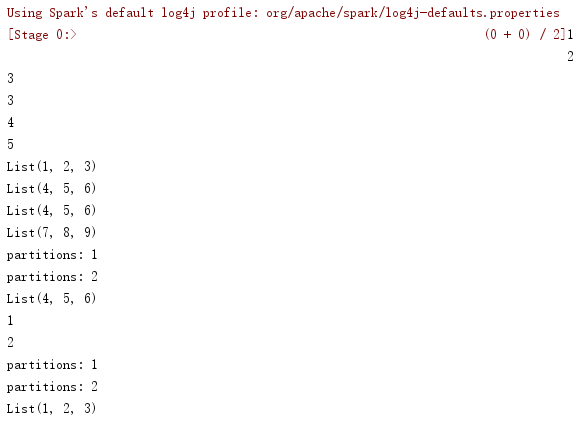
rdd1.subtract(rdd2).collect().foreach(println)
println(s"partitions: ${rdd1.subtract(rdd2, 1).partitions.size}")
println(s"partitions: ${rdd1.subtract(rdd2, 2).partitions.size}") val rdd3 = sc.parallelize(List(List(1, 2, 3), List(4, 5, 6)), 1)
val rdd4 = sc.parallelize(List(List(4, 5, 6), List(7, 8, 9)), 1)
rdd3.subtract(rdd4).collect().foreach(println)
} private def testIntersection(sc: SparkContext) = {
val rdd1 = sc.parallelize(1 to 2, 1)
val rdd2 = sc.parallelize(3 to 5, 1)
//返回两个RDD的交集,并且去重。
rdd1.intersection(rdd2).collect().foreach(println)
println(s"partitions: ${rdd1.intersection(rdd2, 1).partitions.size}")
println(s"partitions: ${rdd1.intersection(rdd2, 2).partitions.size}") val rdd3 = sc.parallelize(List(List(1, 2, 3), List(4, 5, 6)), 1)
val rdd4 = sc.parallelize(List(List(4, 5, 6), List(7, 8, 9)), 1)
rdd3.intersection(rdd4).collect().foreach(println)
} private def testUnion(sc: SparkContext) = {
val rdd1 = sc.parallelize(1 to 3, 1)
val rdd2 = sc.parallelize(3 to 5, 1)
//将两个RDD进行合并,不去重。
rdd1.union(rdd2).collect().foreach(println) val rdd3 = sc.parallelize(List(List(1, 2, 3), List(4, 5, 6)), 1)
val rdd4 = sc.parallelize(List(List(4, 5, 6), List(7, 8, 9)), 1)
rdd3.union(rdd4).collect().foreach(println)
} }
运行结果:
Spark 学习笔记之 union/intersection/subtract的更多相关文章
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
随机推荐
- 2019nc#6
https://ac.nowcoder.com/acm/contest/886#question 题号 标题 已通过代码 题解/讨论 通过率 团队的状态 A Garbage Classificatio ...
- hdu-6701 Make Rounddog Happy
题目链接 Make Rounddog Happy Problem Description Rounddog always has an array a1,a2,⋯,an in his right po ...
- CodeForces 812E Sagheer and Apple Tree 树上nim
Sagheer and Apple Tree 题解: 先分析一下, 如果只看叶子层的话. 那么就相当于 经典的石子问题 nim 博弈了. 那我们看非叶子层. 看叶子层的父亲层. 我们可以发现, 如果从 ...
- “玲珑杯”ACM比赛 Round #18 1147 - 最后你还是AK了(思维,边的贡献)
题目链接:http://www.ifrog.cc/acm/problem/1147 题解:这题很容易想到的是边的贡献也就是每条边最多被取到几次,和点的贡献类似,那些加边只要加在边贡献大的边上就行.然后 ...
- codeforces Educational Codeforces Round 24 (A~F)
题目链接:http://codeforces.com/contest/818 A. Diplomas and Certificates 题解:水题 #include <iostream> ...
- Bytes类型
Bytes类型 一.定义 bytes类型是指一堆字节的集合,在python中以b开头的字符串都是bytes类型. b'\xe5\xb0\x8f\xe7\x8c\xbf\xe5\x9c\x88' ''' ...
- Winform中设置DevExpress的RadioGroup的items从配置文件中加载
场景 DevExpress的RadioGroup的items选项如果是不确定的话,需要其从配置文件中加载. 实现 在项目目录下新建Config文件夹,文件夹下新建xml配置文件. <?xml v ...
- SqlServer 2014 还原数据库时提示:操作系统返回了错误5,,拒绝访问
场景 在进行数据库还原时提示: System.Data.SqlError:在对”“尝试”“时,操作系统返回了错误5(拒绝访问) 实现 第一种方案是修改要还原的数据库备份文件的权限. 找到备份文件右击属 ...
- CentOS7 使用tree命令不显示中文
1.你如果使用tree命令看见的情况是这样 [lk@localhost ~]$ tree . ├── perl5 ├── Python-.tgz ├── \\\\\\ ├── \\\\\\ ├── \ ...
- Linux 笔记 - 第十四章 LAMP 之(一) 环境搭建
博客地址:http://www.moonxy.com 一.前言 LAMP 是 Linux Apache MySQL PHP 的简写,即把 Apache.MySQL 以及 PHP 安装在 Linux 系 ...