Spark学习笔记2(spark所需环境配置
Spark学习笔记2
配置spark所需环境
1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求
不需要最新版的maven客户端。
解压完成之后在解压好的maven客户端的文件夹内打开conf文件夹,修改里面的settings.xml文件
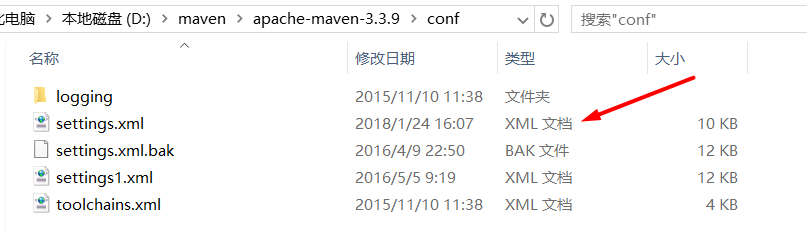
然后只需要修改这一行就可以了 ,把这一行替换成你自己本地的maven仓库的路径
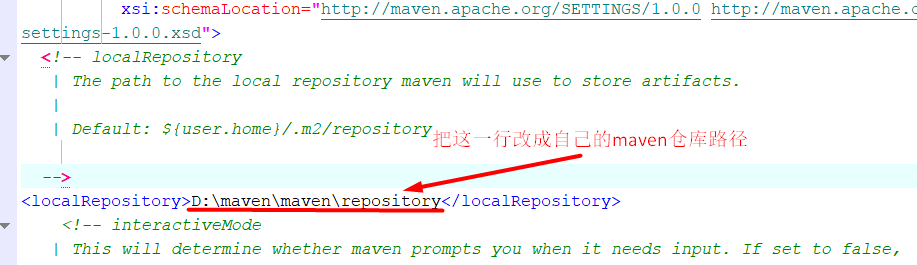
最好是自己有一个完整点的maven仓库,然后把这个修改过的xml文件放到maven仓库下

到这里,你本地的maven客户端环境已经搭建好了,现在可以到IDEA里建一个maven项目了!
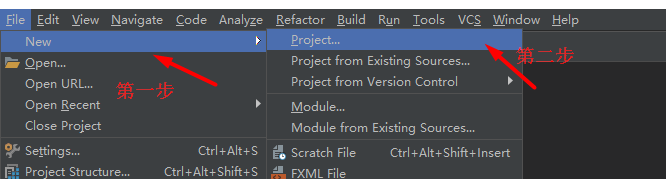
在IDEA上建立一个maven项目
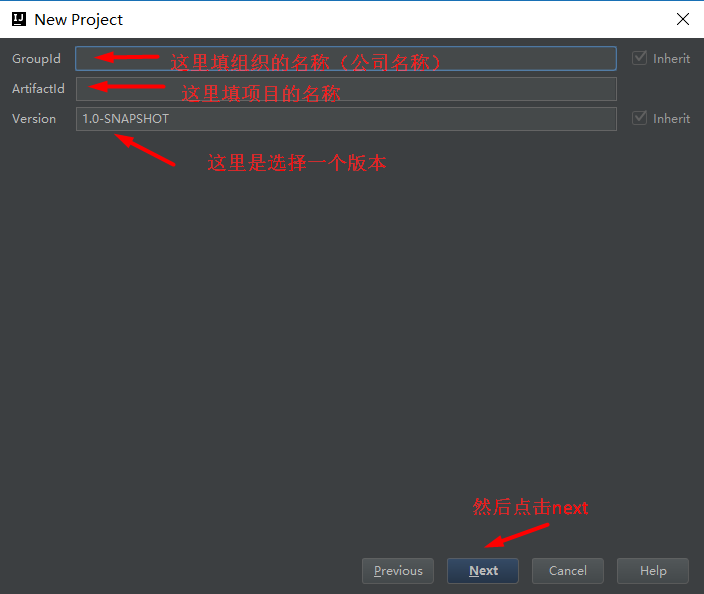
1.创建一个maven项目
new Project --》 Maven --》 next --》 groupId:组织名称(类似eclipse的工作空间),Artifactid:项目名称 Version:版本名称
--》 next到 项目名称,项目的工作路径等 --》 finish
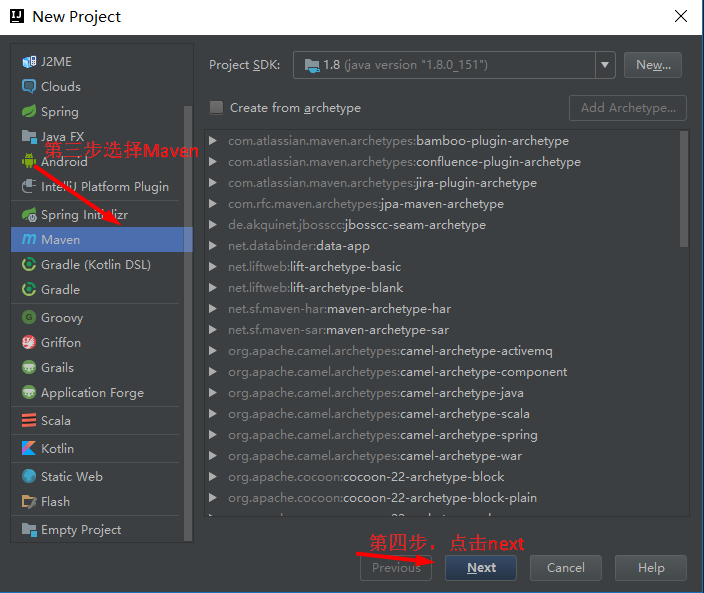

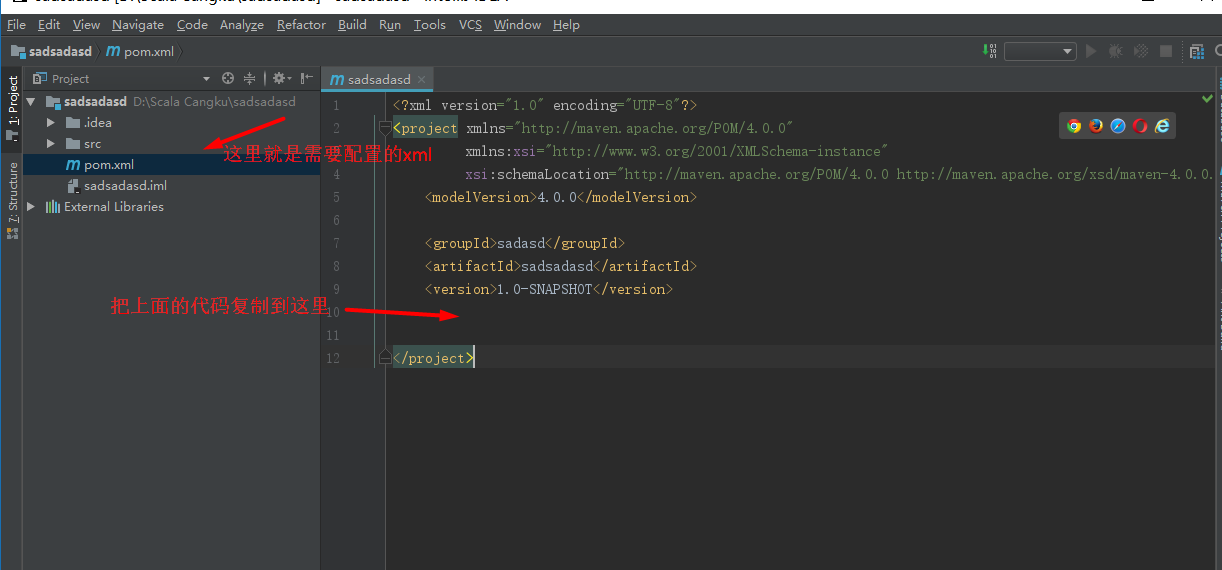
下面开始配置你的xml文件,因为maven项目需要很多的依赖,配置好xml文件
就可以导入大部分的依赖包了,直接把下面的代码复制进来放入你的xml文件里就ok
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>cn.beicai1704</groupId>
<artifactId>sparkLearn1704</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.10.6</scala.version>
<spark.version>1.6.1</spark.version>
<hadoop.version>2.6.4</hadoop.version>
</properties> <dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.1</version>
</dependency> <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.41</version>
</dependency> </dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
然后根据提示点击加载依赖到项目里,因为我已经配置过了,所以没有任何显示
到这里基本就配置完成了,现在可以写一个spark文件来测试一下了!
转载本文请和本文作者联系,本文来自博客园一袭白衣一
Spark学习笔记2(spark所需环境配置的更多相关文章
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- Spark 学习笔记之 Spark history Server 搭建
在hdfs上建立文件夹/directory hadoop fs -mkdir /directory 进入conf目录 spark-env.sh 增加以下配置 export SPARK_HISTORY ...
- 张高兴的 Xamarin.Android 学习笔记:(一)环境配置
最近在自学 Xamarin 和 Android ,同时发现国内在做 Xamarin 的不多.我在自学中间遇到了很多问题,而且百度到的很多教程也有些过时,现在打算写点东西稍微总结下,顺便帮后人指指路了. ...
- cocos2dx 3.0 学习笔记 引用cocostudio库 的环境配置
cocostudio创建UI并应用时须要引用cocostudio库,须要额外的环境配置: 之前已经搭配好了基础的开发环境,包含 1) JDK 2) Python 2.7 3) ant 4) visua ...
- Spark学习笔记之-Spark远程调试
Spark远程调试 本例子介绍简单介绍spark一种远程调试方法,使用的IDE是IntelliJ IDEA. 1.了解jvm一些参数属性 -X ...
- 《objective-c基础教程》学习笔记 (一)—— 开发环境配置和简单类型输出
懒惰是富有最大的敌人,再不前进,我们就out了.最近工作比较轻松,不是很忙.于是想晚上下班回家学习点新东西.看着苹果大军的一天天壮大,心里也是痒痒的.于是就想先系统的学习下Objective-C,为之 ...
- Hadoop学习笔记—1.基本介绍与环境配置
一.Hadoop的发展历史 说到Hadoop的起源,不得不说到一个传奇的IT公司—全球IT技术的引领者Google.Google(自称)为云计算概念的提出者,在自身多年的搜索引擎业务中构建了突破性的G ...
- MongoDB学习笔记(二:入门环境配置及与关系型数据库区别总结)
一.下载及安装MongoDB MongoDB下载官网链接:http://www.mongodb.org/downloads 具体安装步骤教程:http://www.shouce.ren/api/vie ...
- Java学习笔记之:Java Servlet环境配置
一.介绍 Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层. 使用 ...
随机推荐
- 如何减轻ajax定时触发对服务器造成的压力和带宽的压力?ajax-长轮训
AJAX长轮询的方法来解决频繁对后台的请求,进一步减小压力 在实现过程发现AJAX的多次请求会出现多线程并发的问题又使用线程同步来解决该问题 个人对ajax长轮询的一点愚见 ajax请示后台时,后台程 ...
- appium 解锁九宫格
很多人在自动化的过程中,对解锁9宫格有很多麻烦,特别是app上的有些整个放在整个view中,这就给我们测试解锁九宫格带来问题了,笔者尝试了去解决,但是都没有找到一个很好的方案,那么我就试着先去通过安卓 ...
- Android 内存暴减的秘密?!
作者:杨超,腾讯移动客户端开发 工程师 商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处. WeTest 导读 在我这样减少了26.5M Java内存! 一文中内存优化一期已经告一段落, ...
- [编织消息框架][JAVA核心技术]动态代理应用6-设计生成类
上篇介绍到rpc可以使用接口与实现类来约束书写 根据接口用javassist生成两个代理类 1.sendProxy 发送处理,调用方式可以是远程/本地 2.receiveProxy 接收处理,内部调用 ...
- php array_walk
PHP array_walk() 函数 对数组中的每个元素应用用户自定义函数: <?php function myfunction($value,$key) { echo "The k ...
- C#语言和SQL Server第十章笔记
第十章 :使用关键字模糊查询 笔记 一:使用关键字 :LIKE BETWEEN IN进行模糊查询 通配符: 一类字符,代替一个或多个真正的字符 与LIKE关键字一起使用 通配符: 解释 实例 符 ...
- python导入模块时的执行顺序
当python导入模块,执行import语句时,到底进行了什么操作?按照python的文档,她执行了如下的操作: 第一步,创建一个新的module对象(它可能包含多个module) 第二步,把这个mo ...
- JS随机显示一张图片
var images=['p1.jpg','p2.jpg','p3.jpg']; var url=images[Math.floor(Math.random()*images.length)]; co ...
- 【转】NO.3、python+appium+ios,遍历真机元素,得到webview
pyhton+appium+iOS,遍历真机webview.是遍历真机的webview,遍历模拟器的webview请另寻方法. 1.mac上安装ios_webkit_debug_proxy 命令:br ...
- HTML常用标签属性使用
img: a 页面超链接