《机器学习技法》---AdaBoost算法
1 AdaBoost的推导
首先,直接给出AdaBoost算法的核心思想是:在原数据集上经过取样,来生成不同的弱分类器,最终再把这些弱分类器聚合起来。
关键问题有如下几个:
(1)取样怎样用数学方式表达出来;
(2)每次取样依据什么准则;
(3)最后怎么聚合这些弱分类器。
首先我们看第一个问题,如何表示取样?答案使用原数据集上的加权error。
假设我们对数据集D做的取样如下:

那么我们在新数据集上的01error可以等效为在原数据集上的加权error:

即我们取样相当于确定一组权重μ,对这个加权的error作最小化就能得到一个弱分类器g。
特别的,对于svm和逻辑回归,如果我们已知权重μ,我们可以用下面的方式解:
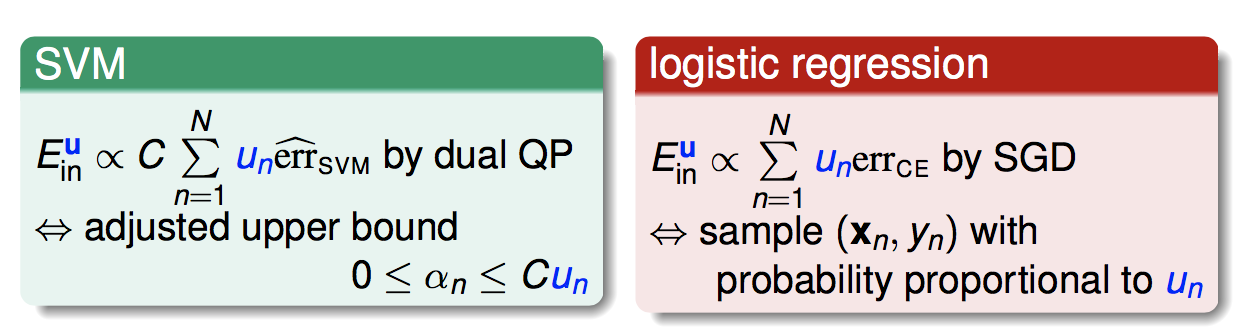
然后是第二个问题,依据什么原则来取样?或者说,怎样选择权重μ。
答案是多样性。即保证生成的每个弱分类器的差别越大,最后的聚合出来的强分类器就会越好。
如何来保证这一点呢?假设我的第t次取样生成了gt,第t+1次取样生成了g(t+1),取样的规则分别是μt和μt+1。即:

那么,要保证gt+1和gt有很大不同,有一个办法,就是使gt用在gt+1的数据集上时,效果很差。效果很差就是错误率是0.5,跟扔硬币一样:

即:

所以,更新这个权重的方法是,对于t轮上分类错误的点,它的u应该更新为乘以总的分类正确率,对于分类正确的点,它的u应该更新为乘以总的分类错误率,注意这里的分类错误率是加权后的分类错误率(或者说在采样后的分类错误率):

这里我们使用另一种与上面等效的方法:

它有一定的物理意义:由于上一轮错误率总是小于0.5,因此方块t是大于1的。因此对于上一次分类正确的权重,除以方块t,减小了权重;对于上一次分类错误的权重,乘以方块t,放大了权重。
类似于水果课堂中老师教学生的例子。
第三个问题,得到了这些弱分类器,如何把他们聚合起来?AdaBoost使用的是Linear Blending的方式,其中的权重应该与方块t成正比,即这个弱分类器表现越好,权重应该越大:

另外,初始的u我们定为均匀的。
这样,AdaBoost算法如下:

2 AdaBoost的理论保证

《机器学习技法》---AdaBoost算法的更多相关文章
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- Adaboost算法初识
1.算法思想很简单: AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(三个臭皮匠,顶个诸葛亮) 它的 ...
- 【AdaBoost算法】积分图代码实现
一.积分图介绍 定义:图像左上方的像素点值的和: 在Adaboost算法中可用于加速计算Haar或MB-LBP特征值,如下图: 二.代码实现 #include <opencv/highgui.h ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- adaboost算法
三 Adaboost 算法 AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(很多博客里说的三个臭皮匠 ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
随机推荐
- c++学习书籍推荐《C++沉思录》下载
百度云及其他网盘下载地址:点我 编辑推荐 经典C++图书,应广大读者的强烈要求再版 目录 第0章 序幕第一篇 动机第1章 为什么我用C++第2章 为什么用C++工作第3章 生活在现实世界中 第二篇 类 ...
- 树链剖分 [JLOI2014]松鼠的新家
[JLOI2014]松鼠的新家 时间限制: 1 Sec 内存限制: 128 MB 题目描述 松鼠的新家是一棵树,前几天刚刚装修了新家,新家有n个房间,并且有n-1根树枝连接,每个房间都可以相互到达, ...
- 【UVA - 10006 】Carmichael Numbers (快速幂+素数筛法)
-->Carmichael Numbers Descriptions: 题目很长,基本没用,大致题意如下 给定一个数n,n是合数且对于任意的1 < a < n都有a的n次方模n等于 ...
- [Spring-Cloud-Alibaba] Sentinel 整合RestTemplate & Feign
Sentinel API Github : WIKI Sphu (指明要保护的资源名称) Tracer (指明调用来源,异常统计接口) ContextUtil(标示进入调用链入口) 流控规则(针对来源 ...
- SpringBoot之SpringApplication Explain
SpringApplication Explain The SpringApplication class provides a convenient way to bootstrap a Sprin ...
- pytorch实现yolov3(5) 实现端到端的目标检测
torch实现yolov3(1) torch实现yolov3(2) torch实现yolov3(3) torch实现yolov3(4) 前面4篇已经实现了network的forward,并且将netw ...
- Python用法
Python用法 IDE IDE是集成开发环境:Integrated Development Environment的缩写. 使用IDE的好处在于按,可以把编写代码.组织项目.编译.运行.调试等放到一 ...
- c语言进阶14-线性表之链表
一. 线性表的链式存储结构 1. 顺序存储结构不足的解决办法 前面我们讲的线性表的顺序存储结构.它是有缺点的,最大的缺点就是插入和删除时需要移动大量元素,这显然就需要耗费时间.能不能想 ...
- 哥们,B/S了解吗?——啥玩意,我是敲代码的
了解B/S和C/S 前言:......“学好长时间编程了,JavaSE学完了,前端也简单学了”.....“那你学这么多,讲讲B/S吧”......“B/S?这是个啥玩意?没听过”......“靠,牛逼 ...
- SQL Server 保存特殊字符时乱码
场景:协同完成的项目,数据库是同事创建,我们共同使用的表. 客户反应有一些字符查看的时候出现乱码.第一反应是否编码规则的问题.后来去数据库查发现数据库里就是乱码,百度了一下发现说特殊字符要保存在NVA ...