AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法。
1、AdaBoost算法介绍
AdaBoost是Boosting方法中最优代表性的提升算法。该方法通过在每轮降低分对样例的权重,增加分错样例的权重,使得分类器在迭代过程中逐步改进,最终将所有分类器线性组合得到最终分类器,Boost算法框架如下图所示:

图1.1 Boost分类框架(来自PRML)
2、AdaBoost算法过程:
1)初始化每个训练样例的权值,共N个训练样例。
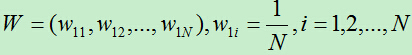
2)共进行M轮学习,第m轮学习过程如下:
A)使用权值分布为Wm的训练样例学习得到基分类器Gm。
B)计算上一步得到的基分类器的误差率:(此公式参考PRML,其余的来自统计学习方法)
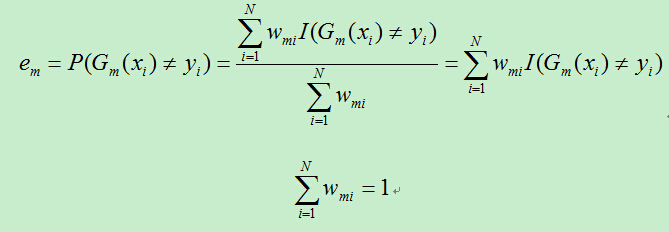
C)计算Gm前面的权重系数:
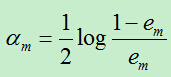
D)更新训练样例的权重系数,
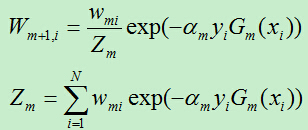
E)重复A)到D)。得到一系列的权重参数am和基分类器Gm
4)将上一步得到的基分类器根据权重参数线性组合,得到最终分类器:
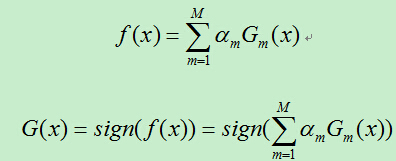
3、算法中的两个权重分析:
1)关于基分类器权重的分析
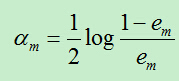
上面计算的am表示基分类器在最终的分类器中所占的权重,am的计算根据em而得到,由于每个基分类器的分类性能要好于随机分类器,故而误差率em<0.5.(对二分类问题)
当em<0.5时,am>0且am随着em的减小而增大,所以,分类误差率越小的基分类器在最终的分类器中所占的权重越大。
注:此处的所有am之后并不为1。
2)训练样例的权重分析
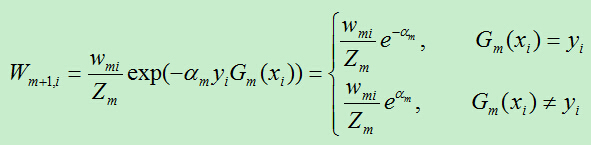
根据公式可知,样例分对和分错,权重相差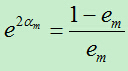 倍(统计学习方法上此公式有误)。
倍(统计学习方法上此公式有误)。
由于am>0,故而exp(-am)<1,当样例被基本分类器正确分类时,其权重在减小,反之权重在增大。
通过增大错分样例的权重,让此样例在下一轮的分类器中被重点关注,通过这种方式,慢慢减小了分错样例数目,使得基分类器性能逐步改善。
4、训练误差分析
关于误差上界有以下不等式,此不等式说明了Adaboost的训练误差是以指数的速度下降的,
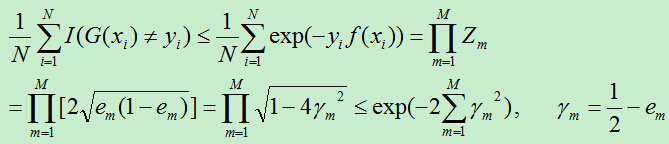
推导过程用到的公式有:
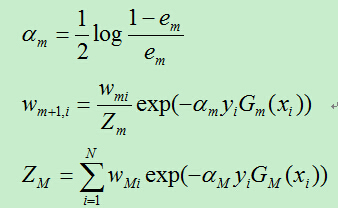
具体推导过程请看统计学习方法课本!
5、AdaBoost算法推导过程
AdaBoost算法使用加法模型,损失函数为指数函数,学习算法使用前向分步算法。
其中加法模型为:
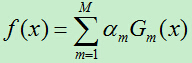
损失函数为指数函数:

我们的目标是要最小化损失函数,通过最小化损失函数来得到模型中所需的参数。而在Adaboost算法中,每一轮都需要更新样例的权重参数,故而在每一轮的迭代中需要将损失函数极小化,然后据此得到每个样例的权重更新参数。这样在每轮的迭代过程中只需要将当前基函数在训练集上的损失函数最小即可。
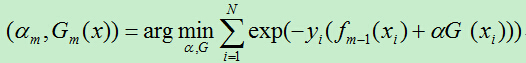
现在我们需要通过极小化上面的损失函数,得到a,G。
设:
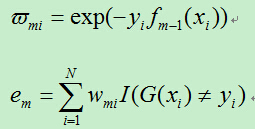
于是有:

为了方便下面推导,我们将:
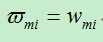
这样,我们就有:

正式推导过程如下:
设: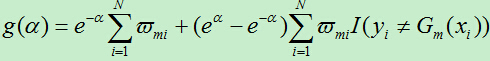
对g(a)求导得:

令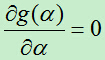 ,得到:
,得到:

其中,在计算过程中用到的em为:
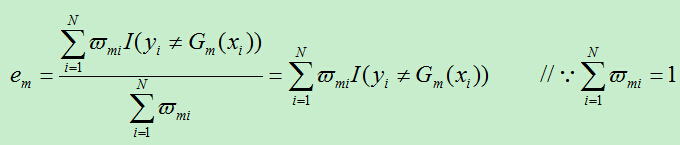
由于 ,所以得到新的损失为:
,所以得到新的损失为:
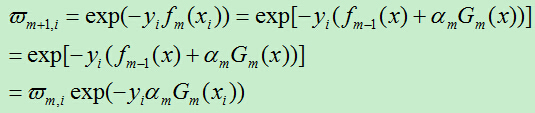
最终的wmi通过规范化得到:
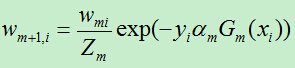
其中规范化因子为:
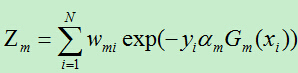
参考文献:
[1] 李航,统计学习方法。
[2] Bishop, Pattern Recognition and Machine Learning
AdaBoost 算法原理及推导的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- AdaBoost算法原理简介
AdaBoost算法原理 AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器).理论证明,只要每个 ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 【机器学习】算法原理详细推导与实现(六):k-means算法
[机器学习]算法原理详细推导与实现(六):k-means算法 之前几个章节都是介绍有监督学习,这个章解介绍无监督学习,这是一个被称为k-means的聚类算法,也叫做k均值聚类算法. 聚类算法 在讲监督 ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10 在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术.通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导 ...
- 强化学习-学习笔记7 | Sarsa算法原理与推导
Sarsa算法 是 TD算法的一种,之前没有严谨推导过 TD 算法,这一篇就来从数学的角度推导一下 Sarsa 算法.注意,这部分属于 TD算法的延申. 7. Sarsa算法 7.1 推导 TD ta ...
随机推荐
- 使用nodejs的net模块创建TCP服务器
使用nodejs的net模块创建TCP服务器 laiqun@msn.cn Contents 1. 代码实现 2. 使用telnet连接服务器测试 3. 创建一个TCP的client 1. 代码实现 ; ...
- zf-启动项目报错Server 127.0.0.1 has no instance named dlx 解决办法
由于百度出来的看不明白,于是我就在群里问,吴善如经理说:你这个问题我上次给李宽看过,用端口连,把instance去掉 然后我去掉之后 项目过程能够成功运行了,原来是这样
- Swaps in Permutation
Swaps in Permutation You are given a permutation of the numbers 1, 2, ..., n and m pairs of position ...
- 智力大冲浪(riddle)
智力大冲浪(riddle) 题目描述 小伟报名参加中央电视台的智力大冲浪节目.本次挑战赛吸引了众多参赛者,主持人为了表彰大家的勇气,先奖励每个参赛者m元.先不要太高兴!因为这些钱还不一定都是你的?!接 ...
- 过河(DP)
问题描述] 在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧.在桥上有一些石子,青蛙很讨厌踩在这些石子上.由于桥的长度和青蛙一次跳过的距离都是正整数,我们可以把独木桥上青蛙可能到达的点看成 ...
- POJ 1185炮兵阵地 (状压DP)
题目链接 POJ 1185 今天艾教留了一大堆线段树,表示做不动了,就补补前面的题.QAQ 这个题,我第一次写还是像前面HDU 2167那样写,发现这次影响第 i 行的还用i-2行那样,那以前的方法就 ...
- mysql安装使用--2 用户管理
1 修改mysql.user表 添加用户 mysql> INSERT INTO mysql.user (Host,User,Password) VALUES (\'%\',\'system\', ...
- @Resource @Autowired 区别
spring2.5提供了基于注解(Annotation-based)的配置,我们可以通过注解的方式来完成注入依赖.在Java代码中可以使用 @Resource或者@Autowired注解方式来经行注入 ...
- c语言基本数据类型short、int、long、char、float、double
C 语言包含的数据类型如下图所示: 一.数据类型与“模子”short.int.long.char.float.double 这六个关键字代表C 语言里的六种基本数据类型. 怎么去理解它们呢? 举个例子 ...
- fuel健康检查Heat失败的原因
service openstack-heat-engine restart chkconfig --level 2345 openstack-heat-engine on