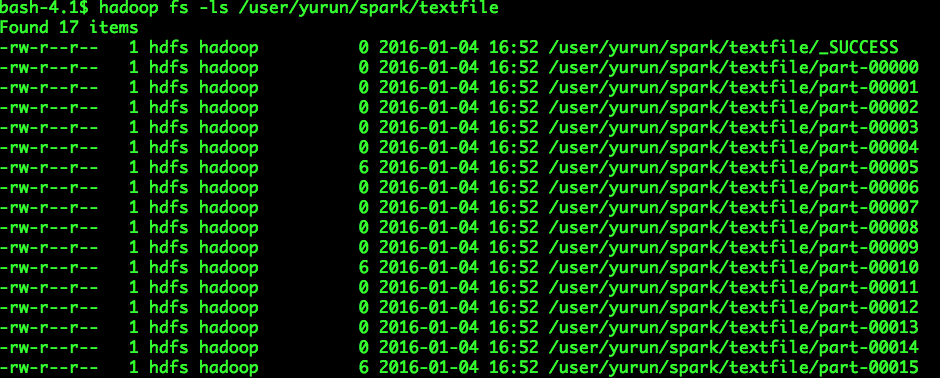
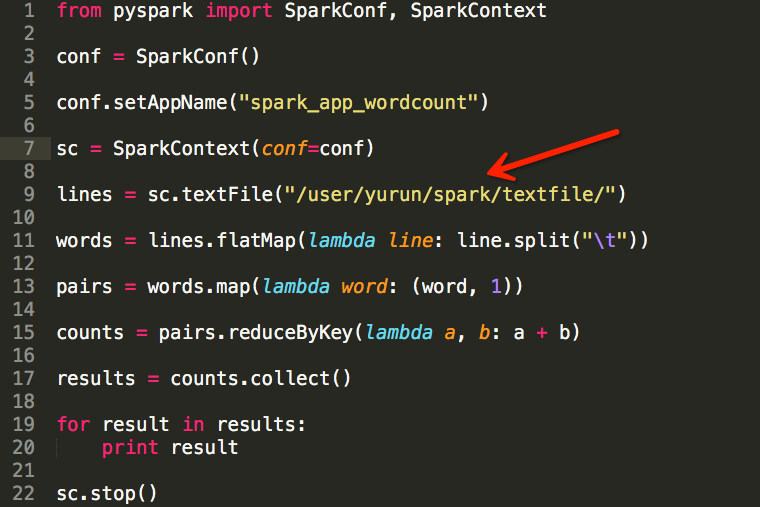
Spark使用CombineTextInputFormat缓解小文件过多导致Task数目过多的问题






Spark使用CombineTextInputFormat缓解小文件过多导致Task数目过多的问题的更多相关文章
- Spark SQL 小文件问题处理
在生产中,无论是通过SQL语句或者Scala/Java等代码的方式使用Spark SQL处理数据,在Spark SQL写数据时,往往会遇到生成的小文件过多的问题,而管理这些大量的小文件,是一件非常头疼 ...
- hadoop 小文件 挂载 小文件对NameNode的内存消耗 HDFS小文件解决方案 客户端 自身机制 HDFS把块默认复制3次至3个不同节点。
hadoop不支持传统文件系统的挂载,使得流式数据装进hadoop变得复杂. hadoo中,文件只是目录项存在:在文件关闭前,其长度一直显示为0:如果在一段时间内将数据写到文件却没有将其关闭,则若网络 ...
- 干货!Apache Hudi如何智能处理小文件问题
1. 引入 Apache Hudi是一个流行的开源的数据湖框架,Hudi提供的一个非常重要的特性是自动管理文件大小,而不用用户干预.大量的小文件将会导致很差的查询分析性能,因为查询引擎执行查询时需要进 ...
- mapreduce 关于小文件导致任务缓慢的问题
小文件导致任务执行缓慢的原因: 1.很容易想到的是map task 任务启动太多,而每个文件的实际输入量很小,所以导致了任务缓慢 这个可以通过 CombineTextInputFormat,解决,主要 ...
- Spark优化之小文件是否需要合并?
我们知道,大部分Spark计算都是在内存中完成的,所以Spark的瓶颈一般来自于集群(standalone, yarn, mesos, k8s)的资源紧张,CPU,网络带宽,内存.Spark的性能,想 ...
- 数仓面试高频考点--解决hive小文件过多问题
本文首发于公众号:五分钟学大数据 小文件产生原因 hive 中的小文件肯定是向 hive 表中导入数据时产生,所以先看下向 hive 中导入数据的几种方式 直接向表中插入数据 insert into ...
- XCode编译文件过多导致内存吃紧解决方法
XCode编译文件过多导致内存吃紧解决方法 /Users/~~/Library/Developer/Xcode/DerivedData 1) 然后 找到编译文件 删除 就好了哦 快去试试看吧
- Spark:spark df插入hive表后小文件数量多,如何合并?
在做spark开发过程中,时不时的就有可能遇到租户的hive库目录下的文件个数超出了最大限制问题. 一般情况下通过hive的参数设置: val conf = new SparkConf().setAp ...
- spark sql/hive小文件问题
针对hive on mapreduce 1:我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并: 参数详细内容可参考官网:https://cwiki.apache.org/conflue ...
随机推荐
- 关于css的兼容
这篇随笔为了方便自己后期的学习和查找,用来记录平时遇到的一些问题,后期会陆续更新 1.背景图 :background-position属性,在ff下不支持该属性的拆分写法(background-pos ...
- JavaScript小笔记の经典算法等....
1.利用toString()里面的参数,实现各进制之间的快速转换: var n = 17; binary_string = n.toString(2); //->二进制"10001&q ...
- U3D 收藏一个飞机随机运动的方法
文章转载:http://www.manew.com/thread-43578-1-1.html 前面的学习中已经涉及到了随机运动,这一篇主要还是前面的随机运动的改进,不废话直接上效果图吧,对比前面的随 ...
- SQL SERVER排序函数
排名函数是SQL Server2005新加的功能.在SQL Server2005中有如下四个排名函数: 1.row_number 2.rank 3.dense_rank 4.ntile 下面分别介绍一 ...
- ios专题 - CocoaPods - 初次体验
[原创]http://www.cnblogs.com/luoguoqiang1985 这CocoaPods怎么用呢? 参考官方文章:guides.cocoapods.org/using/using-c ...
- Lucene初步搜索
Lucene在创立索引后,要进行搜索查询 搜索大概需要5部, 1,读取索引. 2,查询索引. 3,匹配数据. 4,封装匹配结果. 5,获取需要的值. 语言表达能力不好,大概就是分着几部吧. /** * ...
- html5时间选择器
HTML5日期输入类型(date) 分享 分享 分享 分享 分享 在很多页面和web应用中都有输入日期和时间的地方,最典型的是订飞机票,火车票,酒店,批萨等网站. 在HTML5之前 ...
- ng-form
form提供的属性都是用来表示表单的验证状态的,包括:$pristine(表单没有填写记录).$dirty(表单有填写记录).$valid(通过验证).$invalid(未通过验证).$error(验 ...
- 帝国cms灵动标签调用tags
这个语法用来调用[指定分类][指定条件]的所有tags [e:loop={"select * from [!db.pre!]enewstags order by num desc limit ...
- "System.Web" 中不存在类型或命名空间
System.Web”中不存在类型或命名空间名称script /找不到System.Web.Extensions.dll引用 添加引用就行了...“添加引用→.Net→System.Web.Ente ...