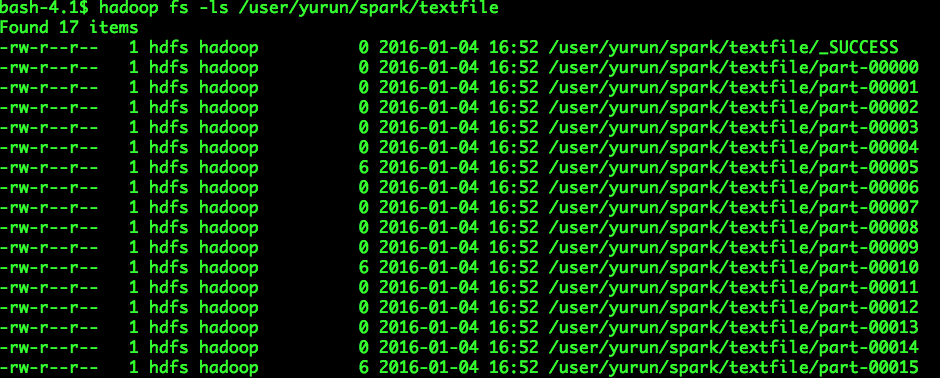
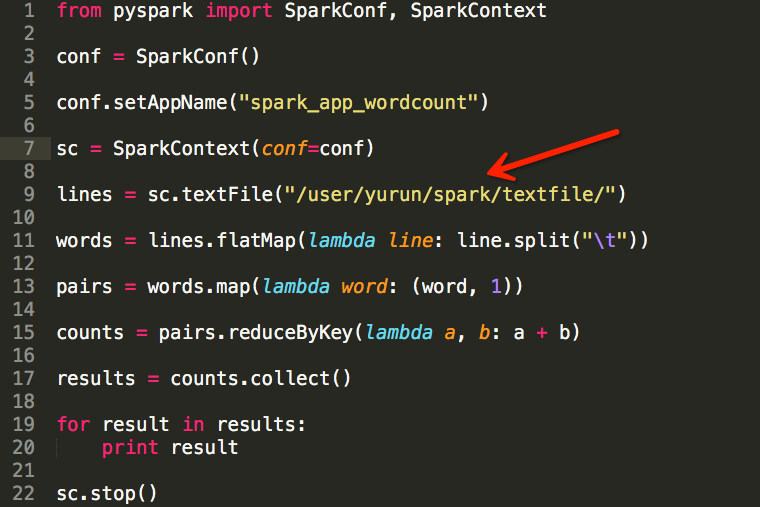
Spark使用CombineTextInputFormat缓解小文件过多导致Task数目过多的问题






Spark使用CombineTextInputFormat缓解小文件过多导致Task数目过多的问题的更多相关文章
- Spark SQL 小文件问题处理
在生产中,无论是通过SQL语句或者Scala/Java等代码的方式使用Spark SQL处理数据,在Spark SQL写数据时,往往会遇到生成的小文件过多的问题,而管理这些大量的小文件,是一件非常头疼 ...
- hadoop 小文件 挂载 小文件对NameNode的内存消耗 HDFS小文件解决方案 客户端 自身机制 HDFS把块默认复制3次至3个不同节点。
hadoop不支持传统文件系统的挂载,使得流式数据装进hadoop变得复杂. hadoo中,文件只是目录项存在:在文件关闭前,其长度一直显示为0:如果在一段时间内将数据写到文件却没有将其关闭,则若网络 ...
- 干货!Apache Hudi如何智能处理小文件问题
1. 引入 Apache Hudi是一个流行的开源的数据湖框架,Hudi提供的一个非常重要的特性是自动管理文件大小,而不用用户干预.大量的小文件将会导致很差的查询分析性能,因为查询引擎执行查询时需要进 ...
- mapreduce 关于小文件导致任务缓慢的问题
小文件导致任务执行缓慢的原因: 1.很容易想到的是map task 任务启动太多,而每个文件的实际输入量很小,所以导致了任务缓慢 这个可以通过 CombineTextInputFormat,解决,主要 ...
- Spark优化之小文件是否需要合并?
我们知道,大部分Spark计算都是在内存中完成的,所以Spark的瓶颈一般来自于集群(standalone, yarn, mesos, k8s)的资源紧张,CPU,网络带宽,内存.Spark的性能,想 ...
- 数仓面试高频考点--解决hive小文件过多问题
本文首发于公众号:五分钟学大数据 小文件产生原因 hive 中的小文件肯定是向 hive 表中导入数据时产生,所以先看下向 hive 中导入数据的几种方式 直接向表中插入数据 insert into ...
- XCode编译文件过多导致内存吃紧解决方法
XCode编译文件过多导致内存吃紧解决方法 /Users/~~/Library/Developer/Xcode/DerivedData 1) 然后 找到编译文件 删除 就好了哦 快去试试看吧
- Spark:spark df插入hive表后小文件数量多,如何合并?
在做spark开发过程中,时不时的就有可能遇到租户的hive库目录下的文件个数超出了最大限制问题. 一般情况下通过hive的参数设置: val conf = new SparkConf().setAp ...
- spark sql/hive小文件问题
针对hive on mapreduce 1:我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并: 参数详细内容可参考官网:https://cwiki.apache.org/conflue ...
随机推荐
- DataDictionaryTool 一款生成数据库字典工具支持mysql和oracle
因为常常查看mysql数据结构,频繁操作.很不爽,于是想把数据表制作成数据字典,于是网上搜的一款工具 DataDictionaryTool ,最终制作成功,分享给大家! 1,此工具需要安装jre ,简 ...
- [视频转换] C#VideoConvert视频转换帮助类 (转载)
点击下载 VideoConvert.zip 主要功能如下 .获取文件的名字 .获取文件扩展名 .获取文件类型 .视频格式转为Flv .生成Flv视频的缩略图 .转换文件并保存在指定文件夹下 .转换文件 ...
- [Mime] MimeHeaders--MimeHeader帮助类 (转载)
点击下载 MimeHeaders.rar 这个类是关于Mime的Headers类看下面代码吧 /// <summary> /// 类说明:Assistant /// 编 码 人:苏飞 // ...
- C#中Hashtable、Dictionary详解以及写入和读取对比
转载:http://www.cnblogs.com/chengxingliang/archive/2013/04/15/3020428.html 在本文中将从基础角度讲解HashTable.Dicti ...
- CoreAnimation6-基于定时器的动画和性能调优
基于定时器的动画 定时帧 动画看起来是用来显示一段连续的运动过程,但实际上当在固定位置上展示像素的时候并不能做到这一点.一般来说这种显示都无法做到连续的移动,能做的仅仅是足够快地展示一系列静态图片,只 ...
- 使用Gulp构建本地开发Web服务器
前端模拟ajax,就需要配置web服务器(apache,iis,nginx),有点麻烦 代码有一点点修改,就需要F5刷新页面很麻烦 Gulp + Gulp-connect + watch + live ...
- 345. Reverse Vowels of a String(C++)
345. Reverse Vowels of a String Write a function that takes a string as input and reverse only the v ...
- jQuery EasyUI 1.4.4 Combobox无法检索中文输入的问题
在项目里使用了EasyUI的Combobox,当ComboBox的item是英文时,都能正常检索出对应项,但是如果使用中文输入法输入几个字母然后通过按shift键输入时,奇怪的事情发生了,combob ...
- 关于js的callback回调函数的理解
回调函数的处理逻辑理解:所谓的回调函数处理逻辑,其实就是先将回调函数的代码 冻结(或者理解为闲置),接着将这个回调函数的代码放到回调函数管理器的队列里面. 待回调函数被触发调用的时候,对应的回调函数的 ...
- C语言学习笔记(一):数组传递时退化为指针
这几天闲来无事,写了一个数组元素排序函数如下: #include <stdio.h> #include <stdlib.h> void ArraySort(int array[ ...