人工智能大语言模型起源篇,低秩微调(LoRA)

上一篇: 《规模法则(Scaling Law)与参数效率的提高》
序言:您在找工作时会不会经常听到LoRA微调,这项技术的来源就是这里了。
(12)Hu、Shen、Wallis、Allen-Zhu、Li、L Wang、S Wang 和 Chen 于2021年发表的《LoRA: Low-Rank Adaptation of Large Language Models》,https://arxiv.org/abs/2106.09685
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。
低秩适配(LoRA)是微调大型语言模型的一种非常有影响力的方法,它具有参数高效的特点。虽然还有其他一些参数高效的微调方法(见下文的综述),但LoRA特别值得一提,因为它既优雅又非常通用,可以应用于其他类型的模型。
虽然预训练模型的权重在预训练任务上是全秩的,但LoRA的作者指出,当预训练的大型语言模型适配到新任务时,它们具有低“内在维度”。因此,LoRA的核心思想是将权重变化(ΔW)分解成低秩表示,这样可以更高效地使用参数。

LoRA 的示例及其性能来自 https://arxiv.org/abs/2106.09685。
(13)Lialin、Deshpande 和 Rumshisky 于2022年发表的《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》,https://arxiv.org/abs/2303.15647
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。本文综述了40多篇关于参数高效微调方法的论文(包括前缀调优、适配器、低秩适配等流行技术),旨在使微调过程(变得)更加高效,尤其是在计算上。
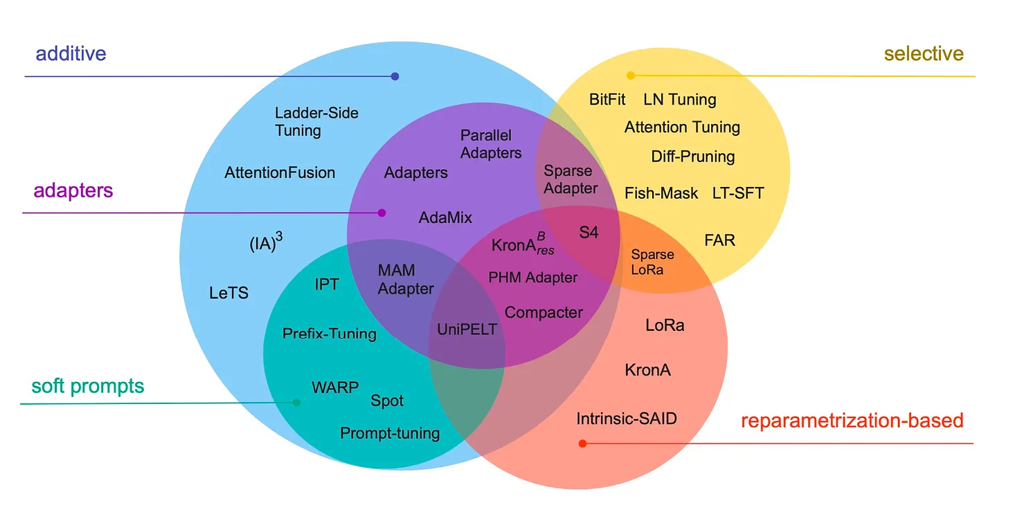
来源:https://arxiv.org/abs/2303.15647
人工智能大语言模型起源篇,低秩微调(LoRA)的更多相关文章
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- DyLoRA:使用动态无搜索低秩适应的预训练模型的参数有效微调
又一个针对LoRA的改进方法: DyLoRA: Parameter-Efficient Tuning of Pretrained Models using Dynamic Search-Free Lo ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- zz【清华NLP】图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐
[清华NLP]图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐 图神经网络研究成为当前深度学习领域的热点.最近,清华大学NLP课题组Jie Zhou, Ganqu Cui, Zhengy ...
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 吴恩达机器学习笔记59-向量化:低秩矩阵分解与均值归一化(Vectorization: Low Rank Matrix Factorization & Mean Normalization)
一.向量化:低秩矩阵分解 之前我们介绍了协同过滤算法,本节介绍该算法的向量化实现,以及说说有关该算法可以做的其他事情. 举例:1.当给出一件产品时,你能否找到与之相关的其它产品.2.一位用户最近看上一 ...
- 【RS】Local Low-Rank Matrix Approximation - LLORMA :局部低秩矩阵近似
[论文标题]Local Low-Rank Matrix Approximation (icml_2013 ) [论文作者]Joonseok Lee,Seungyeon Kim,Guy Lebanon ...
随机推荐
- QT6窗口系统之QT底层窗口QWindow:QT框架中哪些常见窗口是基于QWindow的? 如何实现QT框架栅格窗口?如何实现QT框架OpenGL窗口?
QT6窗口系统之QT底层窗口QWindow:QT框架中哪些常见窗口是基于QWindow的? 如何实现QT框架栅格窗口?如何实现QT框架OpenGL窗口? 简介 本文介绍了QT6窗口系统中的QT底层窗口 ...
- 2024年常用的Net web框架
ASP.NET Core 框架声明:是微软推出的新一代开源.跨平台的 Web 应用框架,用于构建高性能.现代化的 Web 应用程序. 官网地址:https://dotnet.microsoft.com ...
- 【赵渝强老师】大数据分析引擎:Presto
一.什么是Presto? 背景知识:Hive的缺点和Presto的背景 Hive使用MapReduce作为底层计算框架,是专为批处理设计的.但随着数据越来越多,使用Hive进行一个简单的数据查询可能要 ...
- std::vector::reserve
std::vector::reserve 函数在 C++ 中用于预分配内存,避免在元素增加时多次重新分配内存,从而提高性能. 它最常用于需要频繁向 vector 中添加元素,并且可以预估容器的最终大小 ...
- aarch64 和 ARMV8 的区别
aarch64 和 ARMv8 是紧密相关但涵义不同的术语,在解释他们的区别之前,让我们先简单理解它们各自的含义: ARMv8: ARMv8 是指 ARM 架构的第八个版本,这是由 ARM Holdi ...
- window10任务栏图标不见了(如何修复)
1.按 Windows键+ R 2.写 %temp% 在其中,然后单击"确定". 3.删除其中的所有内容以清除临时文件. 4.重启
- Android复习(三)清单文件中的元素——> provider、receiver、service
<provider> 语法: <provider android:authorities="list" android:directBootAware=[&q ...
- HDU-ACM 2024 Day4
T1001 超维攻坚(HDU 7469) 三维凸包,不会. T1002 黑白边游戏(HDU 7470) 显然这道题没有一个固定的最优策略,所以只能 \(\text{dp}\) 决策. 可以倒着做,设 ...
- KubeSphere 镜像构建器(S2I)服务证书过期解决方案
目前 KubeSphere 所有 3.x.x 版本,如果开启了 DevOps 模块并使用了镜像构建器功能(S2I)都会遇到证书过期问题. 解决方法 已开启 DevOps 模块 下载这个更新 S2I 服 ...
- KubeSphere v4 全解析:揭秘您最关心的 12 大热点问题
为了助力大家更顺畅地使用 KubeSphere v4,我们精心汇总了十二个开发者高频关注的热点问题,这些问题全面覆盖了功能特性.性能表现.兼容性考量.安全保障以及升级流程等关键方面.接下来,我们将为大 ...