关于Transformer中Decoder模块是如何预测下一个字符的算法
关于Transformer模型的Encoder-Decoder模块网上介绍的文章非常多,写的非常详尽,可谓汗牛充栋,尤其关于注意力计算这块,不仅给出了公式而且还有具体的计算步骤。关于Transformer模型我觉得大部分文章语焉不详的有两块(可能是我的理解力比较差):
一是关于FNN层的,就是FNN层是如何升维的。 升维使用的核函数是什么?为何升维能提升语义的表达并产生“记忆”功能?为何将维度升4倍,而不是6倍,8倍?
关于FNN层也有一些文章进行解读,大部分都会以CNN的卷积神经网络进行类比:即一个是Token mixer,关注在L这个维度的表达;一个是Channel mixer,专注于d这个维度的表达。至于为何升维4倍,没有什么理论基础,就像8头注意力一样,可能4倍的实验数据效果最好,是性价比最优的选择。
另一个是关于Decoder层最终输出的,就是如何给目标token打分的。相较于注意力机制的计算,大部分文章对最终输出这块几乎都是一笔带过,大体描述为:需要一个线性层(Linear)变换给目标词汇打分,然后使用Softmax对所有分数归一化,从而找出下一个token的概率分布,概率最高的就是要输出的token。
这种描述好像说了什么,但好像什么也没说。就好比说注意力机制就是计算各个token对其它token的打分,从而进行加权求和。大道理大方向是这么回事,但还是无法落地,也就是具体的计算步骤到底是什么?即使是给出了Python代码实现,也是对内部计算的封装,这就意味着你还是无法了解其具体的实现方法。
对于GPT这种Decoder-Only模型,因为没有Encoder模块协助全局语义关系的捕捉,因此其最终的输出要更加困难和复杂。它只能根据前面输入的所有token来预测下一个token。注意力机制解决的是已输入token间的关注度,从而提升各个token对现有上下文的理解程度,但这并意味着能直接预测出下一个token。
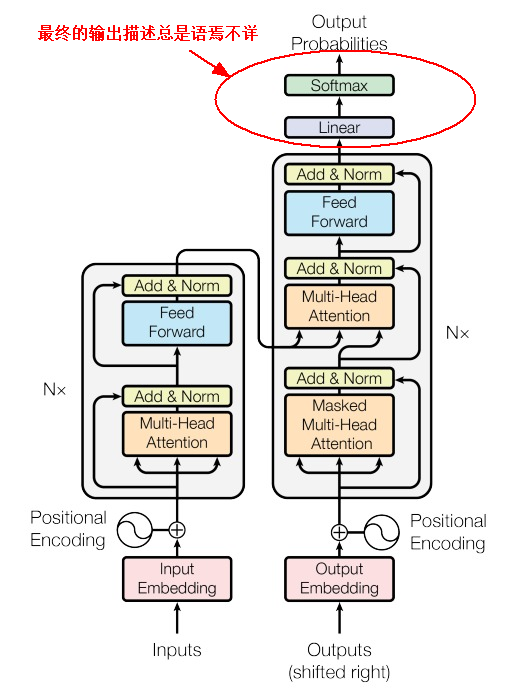
下面给出Decoder层最后输出token的计算方法。
1、假设已输入token: $$ \text{x}_1 、\text{x}_2、\text{x}_3 ,现在要预测下一个token: \text{x}_4 $$
2、经过Decoder模块上述3个token对应的特征向量为: $$\text{z}_1 、 \text{z}_2、\text{z}_3 $$
3、目标词汇表c,共有N个token:
\]
现在的问题是: $$ Decoder层在预测下一个token时,是如何进行线性变换并在目标词汇表c中找出 \text{x}_4 的。 $$
1、计算当前每个输入token x与目标词汇表中每个c的注意力分数
\]
这一个步和注意力机制中的计算方式一样,就是计算当前已输入的每个x与目标词汇所有c的关注度,为了方便描述,不考虑QKV,只是计算向量间的内积:
\]
\]
\]
通过Softmax对关注度分数进行归一化操作。此时每个x会计算出目标词汇的注意力分数“Attenttion Score”。
注:上述的z是x经过Decoder模块运算后包含了注意力信息和上下文语义信息的向量,就是最后一步Linear的输入参数之一(见上图红色框)。
2、使用上述注意力分数来加权目标词汇的值向量并求和
\]
\]
\]
\]
..........
\]
直观的理解就是将每个已输入token x对每个目标词汇c的值向量求和,从而产生新的目标向量: $$\text{z}(c_n)$$。这个新产生的目标向量融合了已输入所有token(本案例中的3个输入x)对其的关注度,并包含了当前上下文的语义信息,这一点非常重要。
到了这一步还是无法预测出下一个token,这时的输出是 N 个目标词汇 c 的新特征向量 $$\text{z}(c_n)$$。此时无法根据该值来预测下一个token。接下来,使用这个加权的上下文向量和当前解码器的隐藏状态来生成针对下一个token的分数,也就是下面最重要的一步,也是目前很多文档语焉不详的地方。
3、如何给每个目标词汇打分
\]
这个公式比较难以理解,其实就是: $$\text{c}_n与新产生的特征向量 \text{z}(c_n)进行内积,公式为: \text{Score}_n=\text{c}_n * \text{z}(c_n)$$
其目的就是计算目标token与该token在当前上下文中产生新特征后的投影大小。为何要这样计算呢?词汇表中的N个词(token)就意味着N个输出,但只有一个目标词汇的特征最能融入当前的上下文,融入新特征的向量与其自己的内积越大,则说明该词最合适。
到了这一步下面的工作就非常简单,只需要通过Softmax对N个目标词汇分数进行归一化,算出概率最大的就是要输出的token。
最后我想说的的是,以上都是我猜的,如果有误概不负责但欢迎指正。
关于Transformer中Decoder模块是如何预测下一个字符的算法的更多相关文章
- NLP之TextRNN(预测下一个单词)
TextRNN @ 目录 TextRNN 1.基本概念 1.1 RNN和CNN的区别 1.2 RNN的几种结构 1.3 多对多的RNN 1.4 RNN的多对多结构 1.5 RNN的多对一结构 1.6 ...
- NLP之Bi-LSTM(在长句中预测下一个单词)
Bi-LSTM @ 目录 Bi-LSTM 1.理论 1.1 基本模型 1.2 Bi-LSTM的特点 2.实验 2.1 实验步骤 2.2 实验模型 1.理论 1.1 基本模型 Bi-LSTM模型分为2个 ...
- cs224d 作业 problem set2 (三) 用RNNLM模型实现Language Model,来预测下一个单词的出现
今天将的还是cs224d 的problem set2 的第三部分习题, 原来国外大学的系统难度真的如此之大,相比之下还是默默地再天朝继续搬砖吧 下面讲述一下RNN语言建模的数学公式: 给出一串连续 ...
- Vue中如何将数据传递到下一个页面(超级简单哒)
先展示效果:注意URL中值是有变化的 一:在goodslist.vue文件夹绑定 <router-link :to="'/goodsinfo/'+subitem.artID" ...
- 关于selenium中的sendKeys()隔几秒发送一个字符
看一下你的IEDriverServer.exe是不是64位的,我也遇到了这样的问题,换成32位的IEDriverServer.exe,瞬间速度快了
- 跟我一起学extjs5(13--运行菜单命令在tabPanel中显示模块)
跟我一起学extjs5(13--运行菜单命令在tabPanel中显示模块) 上面设计好了一个模块的主界面,以下通过菜单命令的运行来把这个模块增加到主界面其中. 在MainModule. ...
- python中的模块和包
模块 一 什么是模块 模块就是一组功能的集合体,可以通过导入模块来复用模块的功能. 比如我在同一个文件夹定义两个.py文件,分别命名为A.py和B.py,那么可以通过在A文件里通过import B来使 ...
- python中re模块的使用(正则表达式)
一.什么是正则表达式? 正则表达式,又称规则表达式,通常被用来检索.替换那些符合某个模式(规则)的文本. 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合, ...
- python 历险记(五)— python 中的模块
目录 前言 基础 模块化程序设计 模块化有哪些好处? 什么是 python 中的模块? 引入模块有几种方式? 模块的查找顺序 模块中包含执行语句的情况 用 dir() 函数来窥探模块 python 的 ...
- tensorflow中slim模块api介绍
tensorflow中slim模块api介绍 翻译 2017年08月29日 20:13:35 http://blog.csdn.net/guvcolie/article/details/77686 ...
随机推荐
- 开源轻量级 IM 框架 MobileIMSDK 的微信小程序端已发布!
一.基本介绍 MobileIMSDK - 微信小程序端是一套基于微信原生 WebSocket 的即时通讯库: 1)超轻量级.无任何第 3 方库依赖(开箱即用): 2)纯 JS 编写.ES6 语法.高度 ...
- dotnet最小webApi开发实践
dotnet最小webApi开发实践 软件开发过程中,经常需要写一些功能验证代码.通常是创建一个console程序来验证测试,但黑呼呼的方脑袋界面,实在是不讨人喜欢. Web开发目前已是网络世界中的主 ...
- Python多分类Logistic回归详解与实践
在机器学习中,Logistic回归是一种基本但非常有效的分类算法.它不仅可以用于二分类问题,还可以扩展应用于多分类问题.本文将详细介绍如何使用Python实现一个多分类的Logistic回归模型,并给 ...
- CDS标准视图:维护计划员组 I_MAINTENANCEPLANNERGROUP
视图名称:维护计划员组 I_MAINTENANCEPLANNERGROUP 视图类型:基础视图 视图代码: 点击查看代码 @EndUserText.label: 'Maintenance Planne ...
- c# yield return
这个函数在处理循环时可以每生成一个数据就返回一个数据让主函数进行处理: static void Main(string[] args) { foreach (var item in GetNumber ...
- docker 使用centos镜像运行javaweb
Docker 是 2014 年最为火爆的技术之一,几乎所有的程序员都听说过它.Docker 是一种"轻量级"容器技术,它几乎动摇了传统虚拟化技术的地位,现在国内外已经有越来越多的公 ...
- Linux 虚拟机中不重启的情况下加新硬盘及扩展根分区容量
我这个系统是Redhat7.7的系统.磁盘占用比较高,需要扩充空用空间,同时又不能关停服务器,或者服务.所以就需要在虚拟机中不重启的情况下加新硬盘及扩展根分区容量. 首先,看一下我这个虚拟机分区占用情 ...
- 2025春秋杯DAY2DAY3部分wp
2025春秋杯DAY2DAY3部分wp DAY2 WEB easy_ser 源码如下 <?php //error_reporting(0); function PassWAF1($data){ ...
- 【忍者算法】从风扇叶片到数组轮转:探索轮转数组问题|LeetCode 189 轮转数组
从风扇叶片到数组轮转:探索轮转数组问题 生活中的算法 想象你在看一个风扇缓缓转动,每次转动三个叶片的距离.原本在上方的叶片转到了右侧,原本在右侧的叶片转到了下方...这就是一个生动的轮转过程.再比如, ...
- FLink自定义Sink,生产的数据导出到mysql
一.自定义生产数据 https://www.cnblogs.com/robots2/p/16048729.html 二.生产转化数据,导出到mysql 2.1 建表语句 CREATE TABLE `v ...