2025第一届轩辕杯Misc详解
Terminal Hacker
一步到位
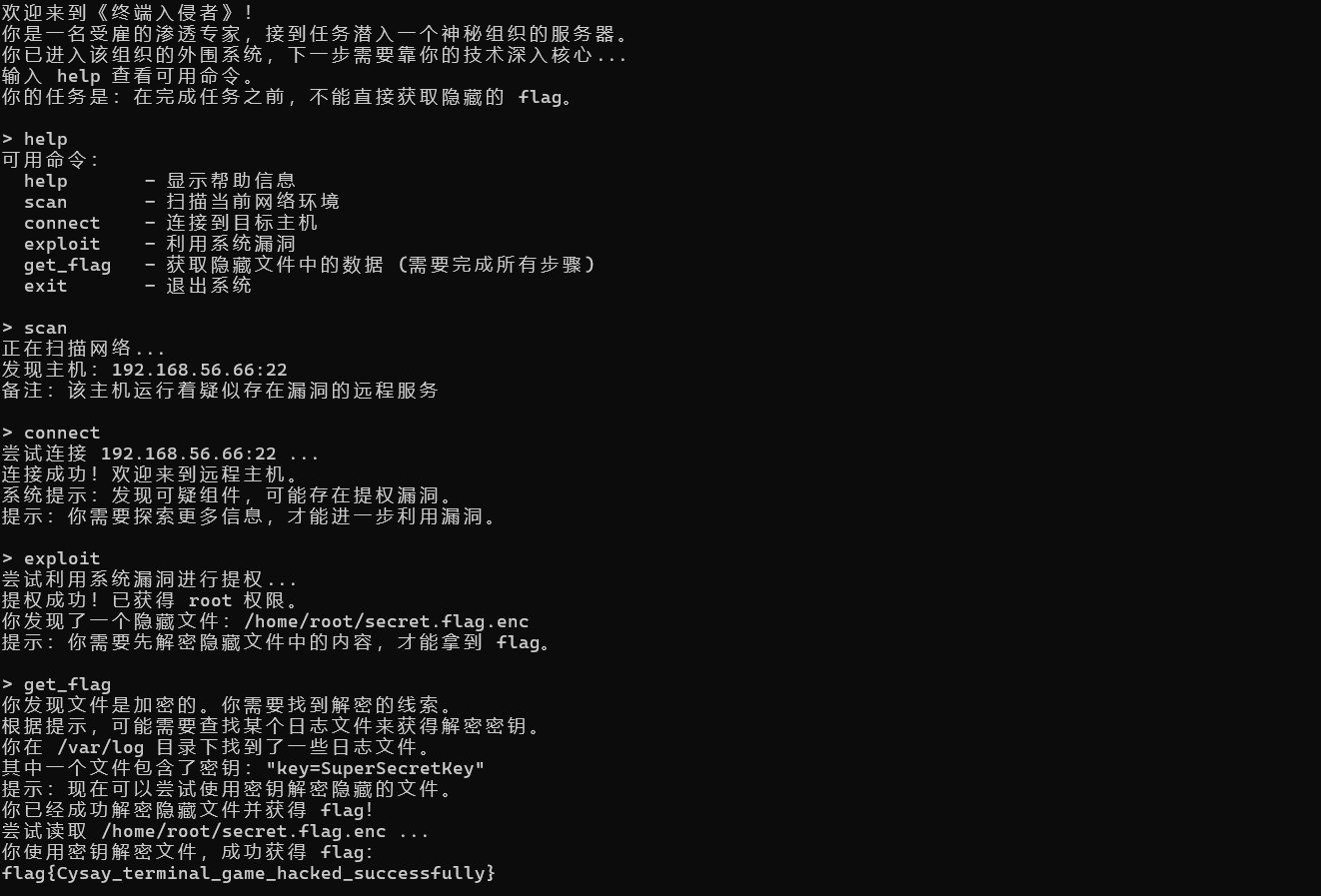
flag{Cysay_terminal_game_hacked_successfully}
哇哇哇瓦
foremost分离
GekkoYoru
随波逐流检测,RGB通道有前半flag

flag{Val0rant_1s_th3_
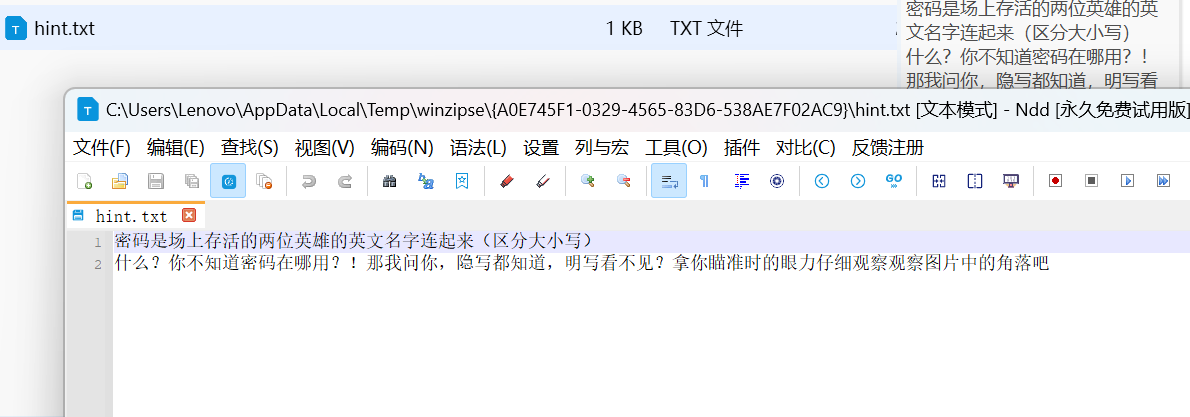
hint提示明文,我们PS打开图片,用取色工具提取信息
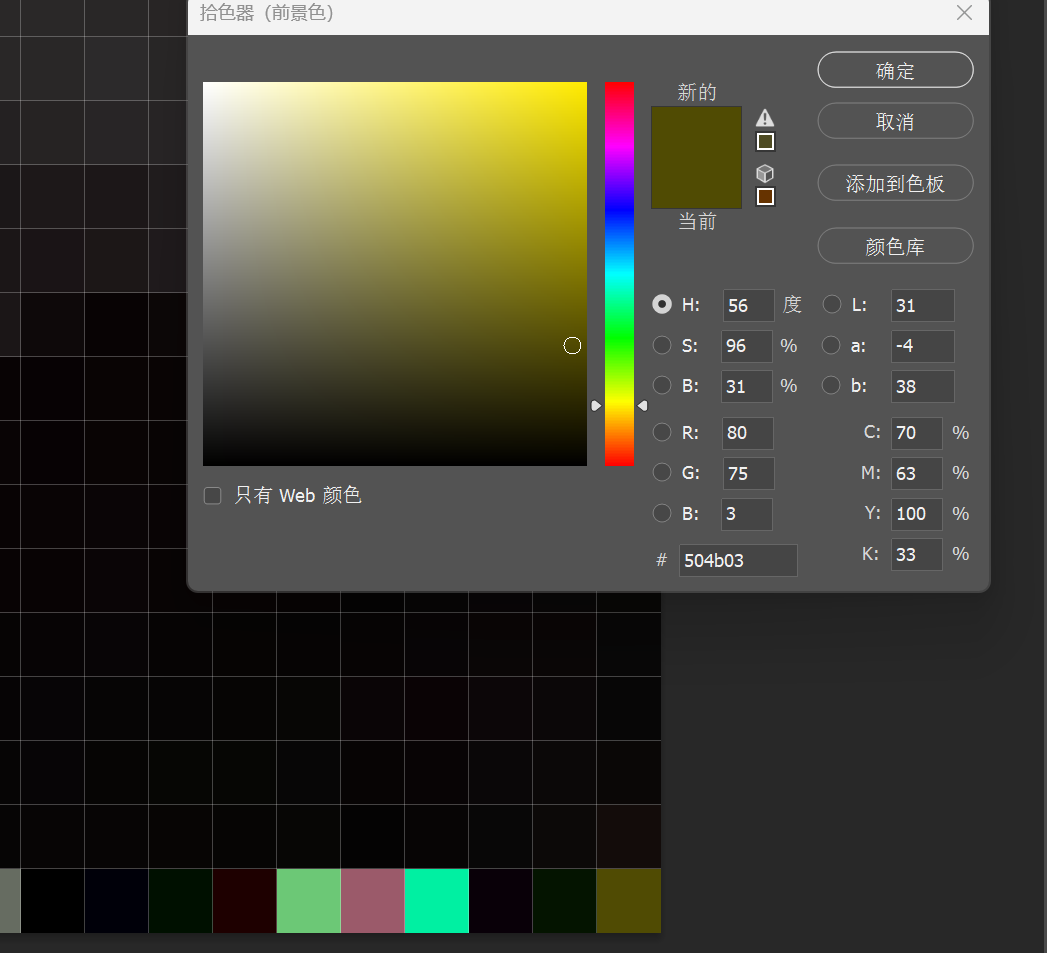
从从右到左提取出来
504b0304140009000800f0a29b5a6a6cc8761e0000001000000009000000666c6167322e7478746a8b34194ebfd04e32f9d34ed7ec544db07161f384b8c0d99bd98be4c634504b07086a6cc8761e00000010000000504b01021f00140009000800f0a29b5a6a6cc8761e00000010000000090024000000000000002000000000000000666c6167322e7478740a00200000000000010018001f18001f6fb7db011f3a80316fb7db01c1e8531a6fb7db01504b050600000000010001005b000000550000000000
压缩包,十六进制导入010另存为zip
打开用密码GekkoYoru解压
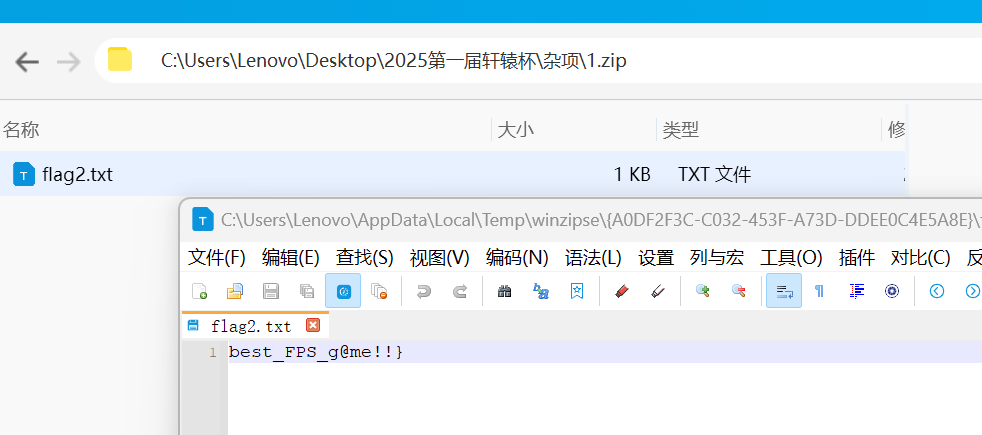
best_FPS_g@me!!}
flag{Val0rant_1s_th3_best_FPS_g@me!!}
数据识别与审计
数字中国产业积分争夺赛总决赛,几乎为原题
txt部分
文件夹拖进vs code,全局搜索一遍(数字0到10,@),出现泄露地址手机号身份证邮箱等
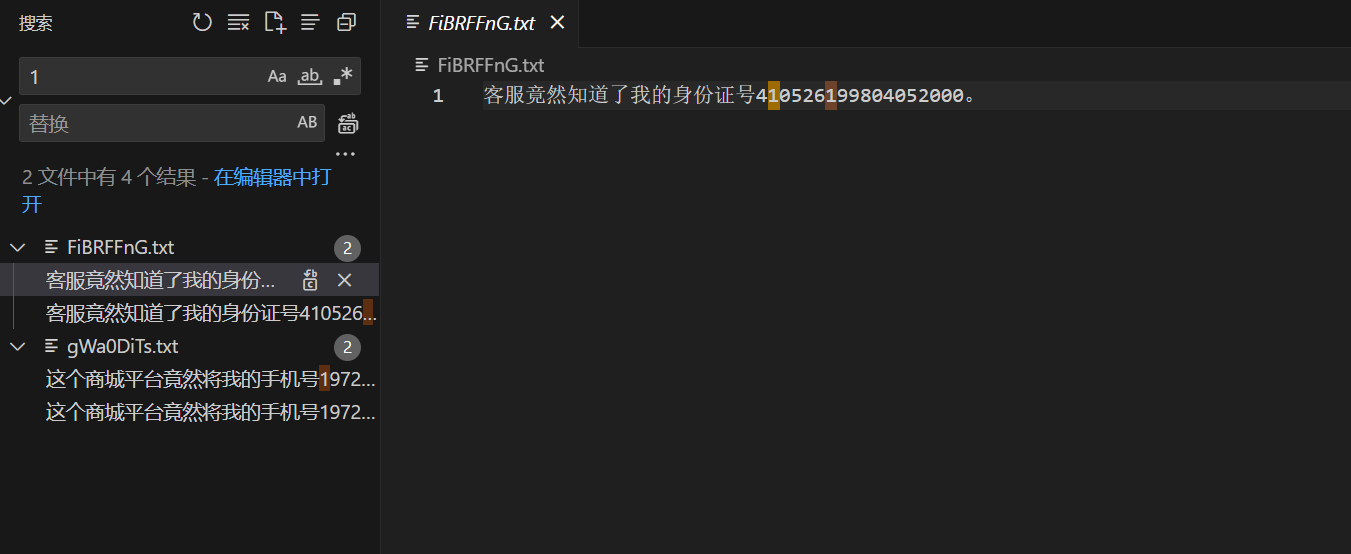
FiBRFFnG.txt
gWa0DiTs.txt
T0BPOXDY.txt
9h0zQJok.txt
Me4CoMw7.txt
png部分
在图片尾部写入了恶意代码,直接编写代码检测图片尾部是否有额外字符串
import os
import struct
def check_png_for_trailing_data(file_path):
"""
检查PNG文件是否在IEND块后有额外数据
参数:
file_path (str): PNG文件路径
返回:
tuple: (是否有额外数据, 额外数据长度, 额外数据前32字节的hex)
"""
with open(file_path, 'rb') as f:
# 检查PNG文件头
header = f.read(8)
if header != b'\x89PNG\r\n\x1a\n':
return (False, 0, None) # 不是有效的PNG文件
# 查找IEND块
iend_found = False
while True:
# 读取块长度 (4字节大端)
chunk_length_data = f.read(4)
if len(chunk_length_data) != 4:
break # 文件结束
chunk_length = struct.unpack('>I', chunk_length_data)[0]
# 读取块类型 (4字节)
chunk_type = f.read(4)
if len(chunk_type) != 4:
break # 文件结束
# 跳过块数据和CRC (4字节)
f.seek(chunk_length + 4, os.SEEK_CUR)
if chunk_type == b'IEND':
iend_found = True
break
if not iend_found:
return (False, 0, None) # 没有找到IEND块
# 检查IEND后是否有数据
remaining_position = f.tell()
f.seek(0, os.SEEK_END)
file_size = f.tell()
if remaining_position == file_size:
return (False, 0, None) # 没有额外数据
extra_data_length = file_size - remaining_position
# 读取前32字节的额外数据作为示例
f.seek(remaining_position, os.SEEK_SET)
sample_data = f.read(min(32, extra_data_length))
return (True, extra_data_length, sample_data.hex())
def scan_directory_for_pngs(directory):
"""
扫描目录中的PNG文件并检查是否有额外数据
参数:
directory (str): 要扫描的目录路径
"""
print(f"扫描目录: {directory}")
print("{:<50} {:<15} {:<32}".format("文件名", "额外数据长度", "前32字节(hex)"))
print("-" * 100)
for root, _, files in os.walk(directory):
for file in files:
if file.lower().endswith('.png'):
file_path = os.path.join(root, file)
has_extra, length, sample = check_png_for_trailing_data(file_path)
if has_extra:
print("{:<50} {:<15} {:<32}".format(
os.path.relpath(file_path, directory),
length,
sample if sample else "无"
))
if __name__ == "__main__":
import sys
if len(sys.argv) != 2:
print("使用方法: python png_checker.py <目录路径>")
sys.exit(1)
target_dir = sys.argv[1]
if not os.path.isdir(target_dir):
print(f"错误: {target_dir} 不是有效目录")
sys.exit(1)
scan_directory_for_pngs(target_dir)
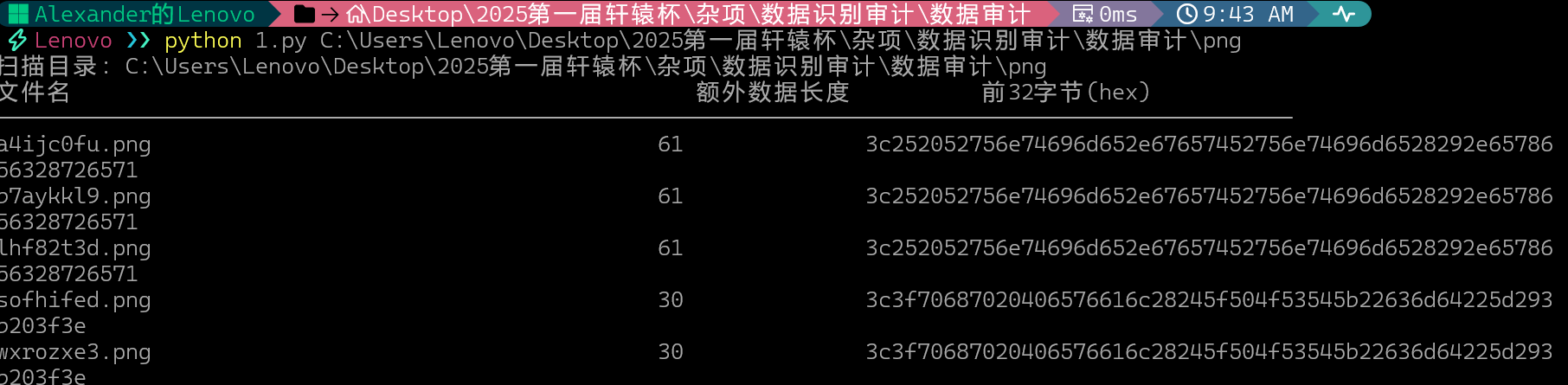
a4ijc0fu.png
b7aykkl9.png
lhf82t3d.png
sofhifed.png
wxrozxe3.png
PDF部分
用微软浏览器打开出现xss弹窗即为威胁文件
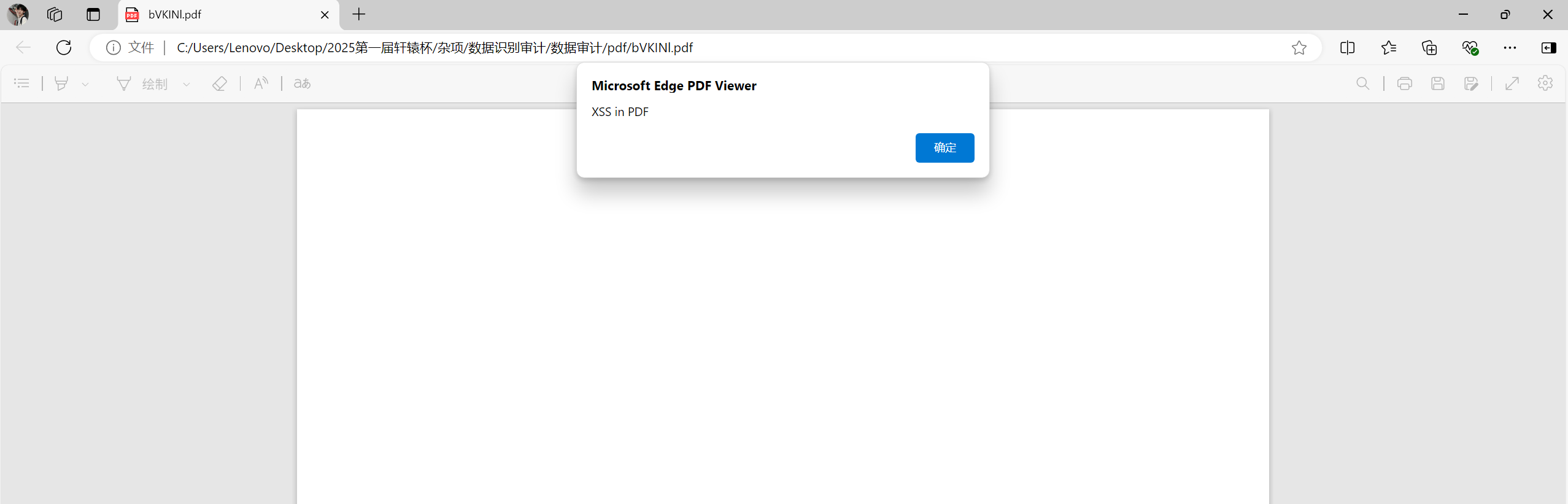
import os
import time # 新增导入time模块
import PyPDF2
def check_pdf_for_dangerous_functions(pdf_path):
"""检查PDF是否包含 eval(), exec(), system() 等危险函数,并返回匹配到的危险函数列表"""
dangerous_functions = [
"eval(", "exec(", "execfile(", # Python 危险函数
"system(", "popen(", "os.system(", "subprocess.call(", # 系统命令执行
"Function(", "eval ", "javascript:", # PDF/JS 相关
"unescape(", "String.fromCharCode(", # JS 混淆代码
"getRuntime()", "ProcessBuilder(", # Java 危险调用
]
found_functions = [] # 存储匹配到的危险函数
try:
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
# 检查 PDF 的文本内容
for page in reader.pages:
text = page.extract_text() or "" # 提取文本
text_lower = text.lower() # 转为小写方便匹配
# 检查是否包含危险函数
for func in dangerous_functions:
if func.lower() in text_lower and func not in found_functions:
found_functions.append(func) # 记录匹配到的危险函数
# 检查 PDF 的二进制内容(更底层扫描)
file.seek(0) # 重新读取文件
raw_content = file.read().decode('latin-1', errors='ignore') # 尝试解码二进制
raw_content_lower = raw_content.lower()
for func in dangerous_functions:
if func.lower() in raw_content_lower and func not in found_functions:
found_functions.append(func) # 记录匹配到的危险函数
return found_functions # 返回所有匹配到的危险函数
except Exception as e:
print(f"️ 检查 {pdf_path} 时出错: {e}")
return [] # 出错时返回空列表
def scan_pdf_folder(folder_path):
"""扫描文件夹中的所有PDF文件,检查危险函数,并输出文件名 + 危险函数"""
dangerous_files = {} # 存储危险文件及其匹配到的函数
for filename in os.listdir(folder_path):
if filename.lower().endswith('.pdf'):
pdf_path = os.path.join(folder_path, filename)
found_functions = check_pdf_for_dangerous_functions(pdf_path)
if found_functions:
dangerous_files[filename] = found_functions
print(f" 发现危险函数 ({filename}): {', '.join(found_functions)}")
else:
print(f" 安全: {filename}")
time.sleep(0.1) # 处理完每个文件后暂停0.1秒
print("\n=== 扫描结果 ===")
if dangerous_files:
print(f"️ 发现 {len(dangerous_files)} 个可能包含危险函数的PDF:")
for file, functions in dangerous_files.items():
print(f"- {file}: {', '.join(functions)}")
else:
print(" 未发现包含危险函数的PDF文件。")
if __name__ == "__main__":
folder_path = "数据审计\\pdf"
if os.path.isdir(folder_path):
scan_pdf_folder(folder_path)
else:
print(" 提供的路径不是有效的文件夹。")
bVKINl.pdf
hnPRx1.pdf
mIR13t.pdf
OGoyOG.pdf
rSG2pW.pdf
wav部分
用openai的whisper功能读取
import os
import whisper
from tqdm import tqdm # 用于显示进度条
def transcribe_wav_files(folder_path, model_size="base", output_file="transcriptions.txt"):
"""
使用Whisper转录文件夹中的所有WAV文件
参数:
folder_path (str): 包含WAV文件的文件夹路径
model_size (str): Whisper模型大小 (tiny, base, small, medium, large)
output_file (str): 保存转录结果的文本文件路径
"""
# 加载Whisper模型
print(f"Loading Whisper {model_size} model...")
model = whisper.load_model(model_size)
# 获取文件夹中的所有WAV文件
wav_files = [f for f in os.listdir(folder_path) if f.lower().endswith('.wav')]
if not wav_files:
print("No WAV files found in the specified folder.")
return
print(f"Found {len(wav_files)} WAV files to process.")
# 打开输出文件准备写入
with open(output_file, 'w', encoding='utf-8') as f_out:
# 处理每个WAV文件
for wav_file in tqdm(wav_files, desc="Processing WAV files"):
file_path = os.path.join(folder_path, wav_file)
try:
# 使用Whisper进行转录
result = model.transcribe(file_path)
# 写入结果到文件
f_out.write(f"File: {wav_file}\n")
f_out.write(f"Transcription: {result['text']}\n\n")
except Exception as e:
print(f"\nError processing {wav_file}: {str(e)}")
f_out.write(f"File: {wav_file}\n")
f_out.write(f"Error: {str(e)}\n\n")
print(f"\nTranscription complete. Results saved to {output_file}")
if __name__ == "__main__":
# 使用示例
folder_path = input("Enter the path to the folder containing WAV files: ")
# 可选:让用户选择模型大小
model_size = input("Choose model size (tiny/base/small/medium/large, default=base): ").strip().lower()
if model_size not in ['tiny', 'base', 'small', 'medium', 'large']:
model_size = "base"
transcribe_wav_files(folder_path, model_size)

精度不准,但是足够识别
Bd2IYe3.wav
bjVwvcC.wav
H0KDChj.wav
ou9E9Mh.wav
UEbzH4X.wav
最后排个序
9h0zQJok.txt, FiBRFFnG.txt, gWa0DiTs.txt, Me4CoMw7.txt, T0BPOXDY.txt,a4ijc0fu.png, b7aykkl9.png, lhf82t3d.png, sofhifed.png, wxrozxe3.png,bVKINl.pdf, hnPRx1.pdf, mIR13t.pdf, OGoyOG.pdf,rSG2pW.pdf,Bd2IYe3.wav, bjVwvcC.wav, H0KDChj.wav, ou9E9Mh.wav, UEbzH4X.wav
md5加密下
flag{234ed8ef5421c5e559420dbf841db68f}
音频的秘密
silenteye解密出zip
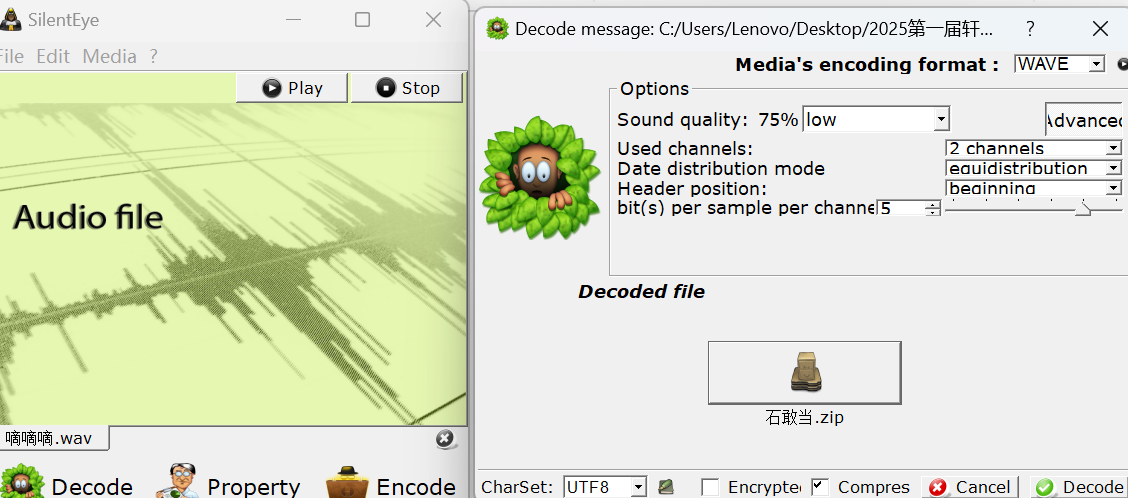
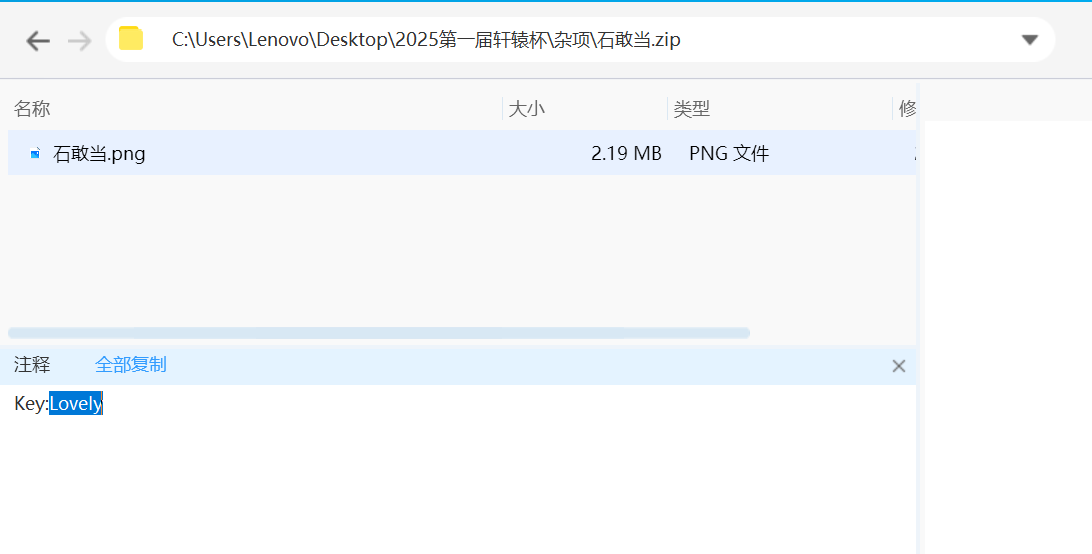
Key:Lovely #后面会用
aapr爆破
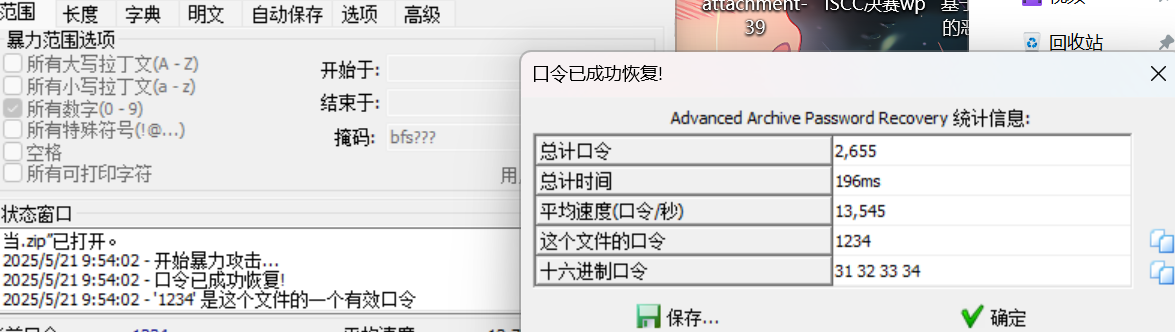
zip密码1234,解压图片
随波逐流检测

RGB通道存在密文
qzvk{Ym_LOVE_MZMP_30vs6@_nanmtc_q0i_J01_1}
用上面的key进行维吉尼亚解密
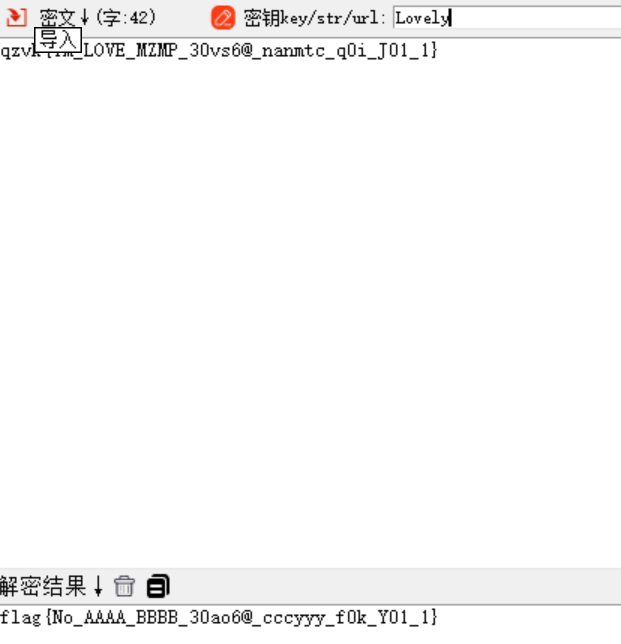
flag{No_AAAA_BBBB_30ao6@_cccyyy_f0k_Y01_1}
隐藏的邀请函
解压docx文件
在Cyyyy.xml中有未知十六进制
直接跟文件名xor得到datamatrix条码
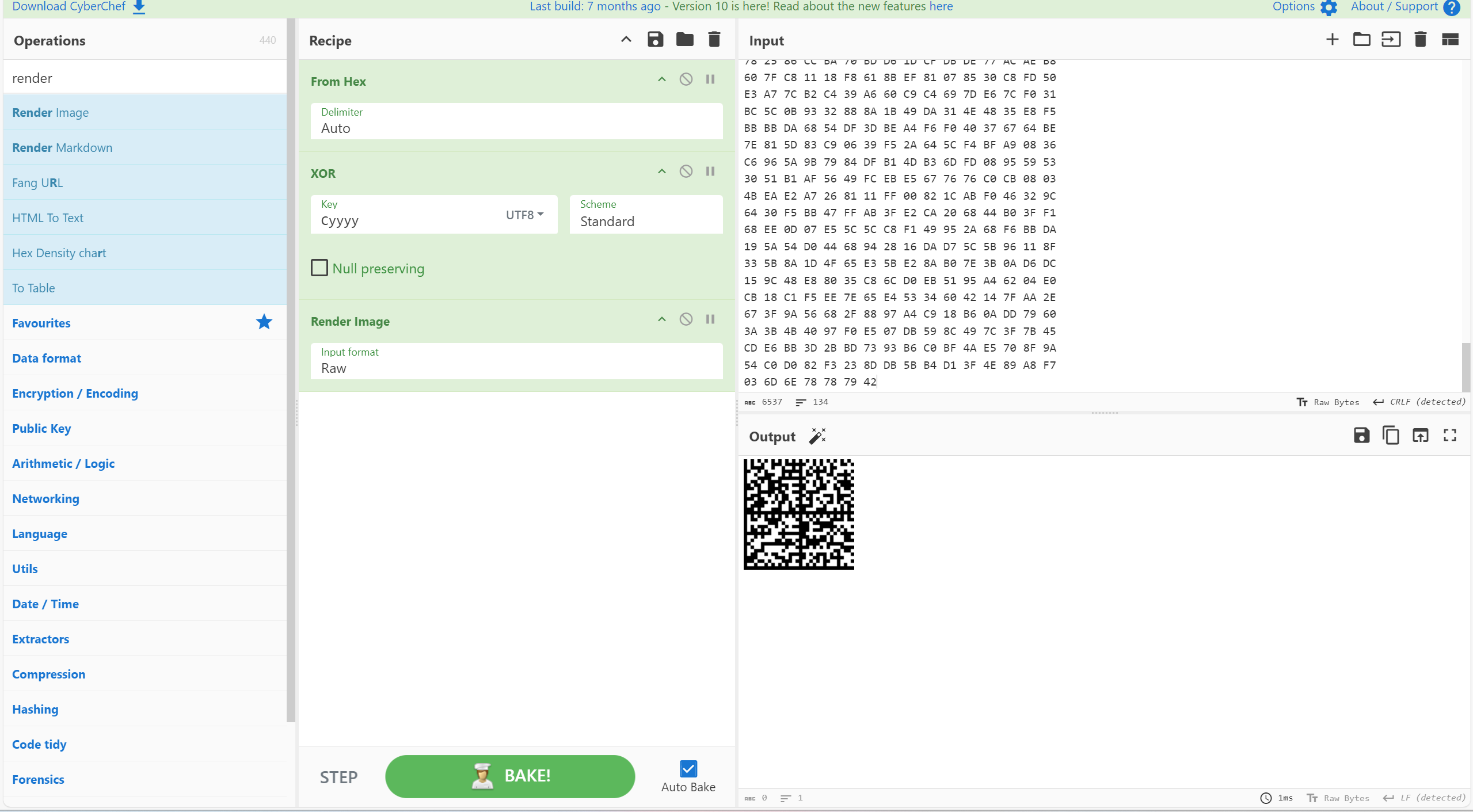
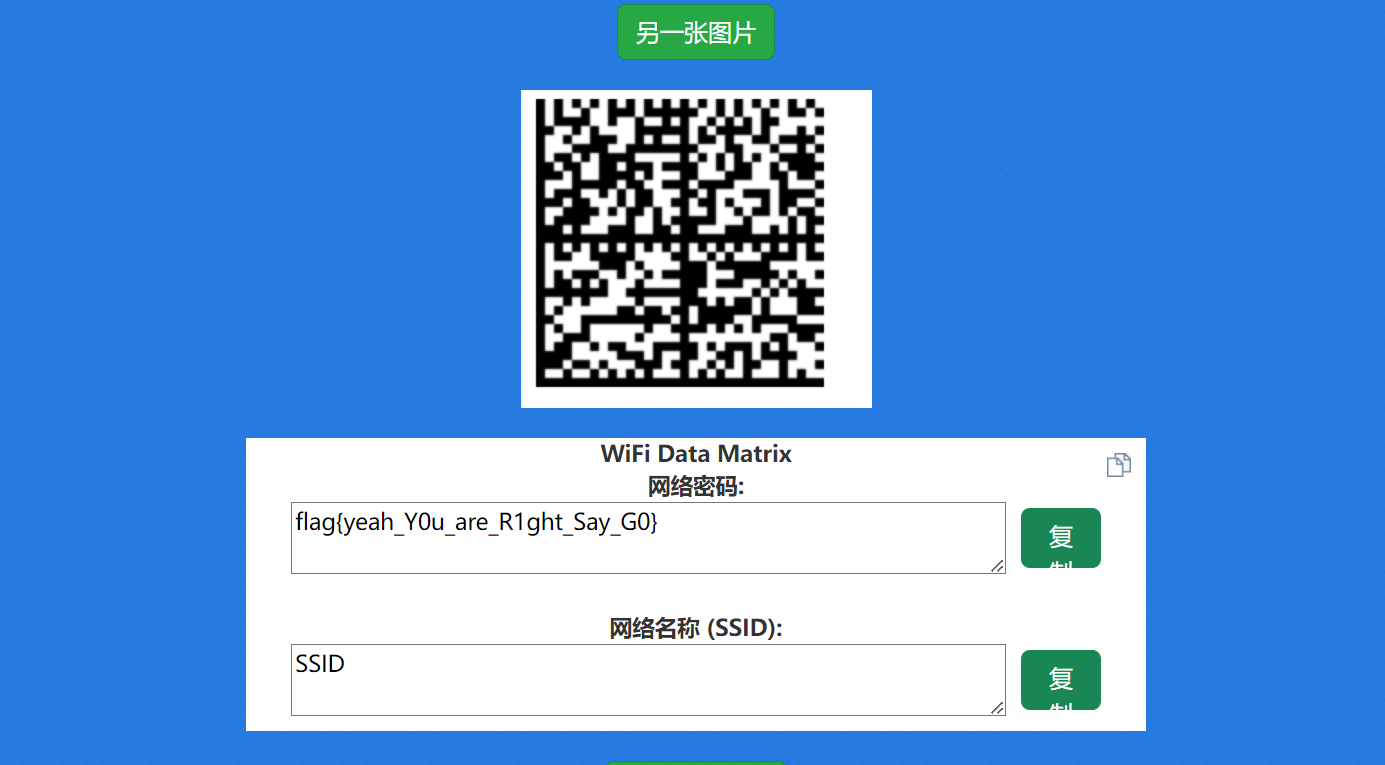
flag{yeah_Y0u_are_R1ght_Say_G0}
一大碗冰粉
lovelymem提取文件
vol3提取
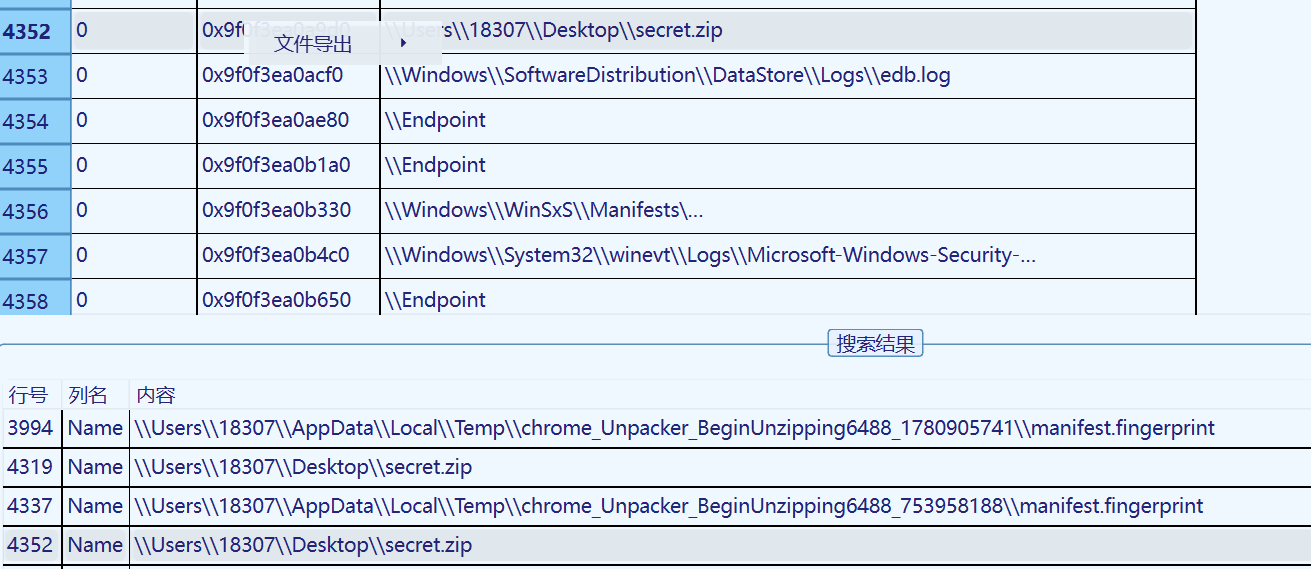
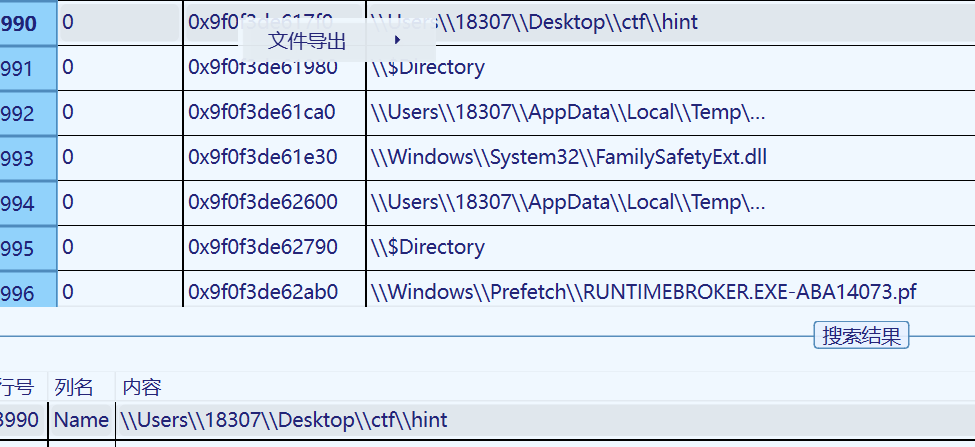
hint提示要我们攻击
直接压缩进行明文攻击
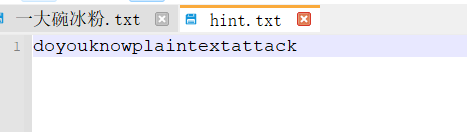
aapr攻击
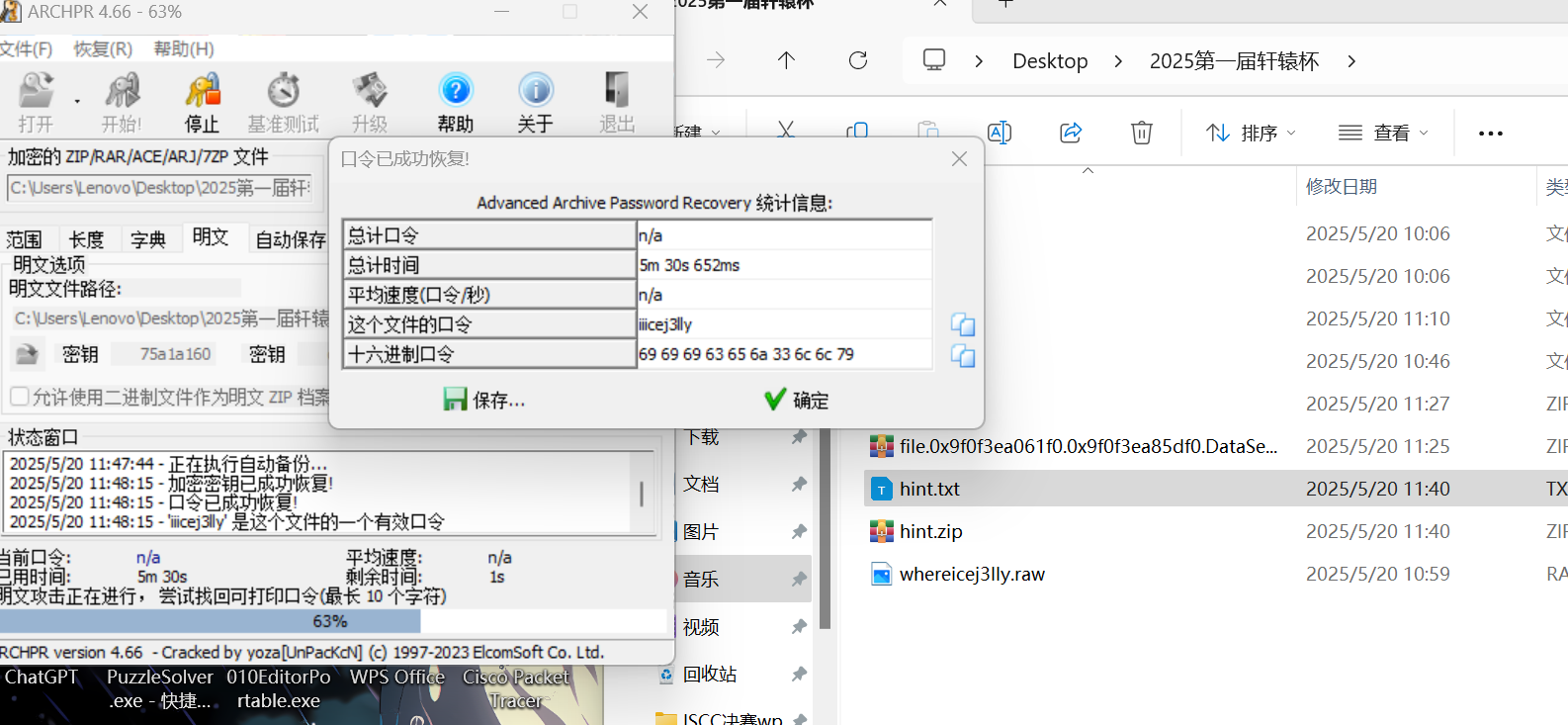
解压得到未知文件
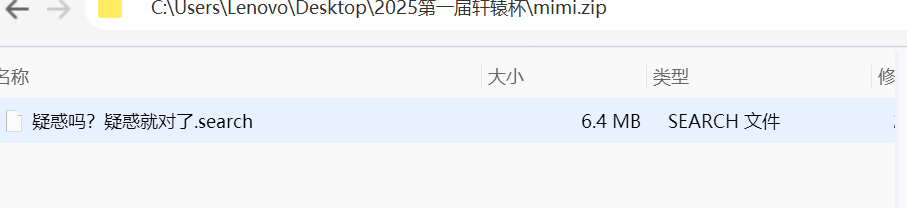
文件名提示疑惑?谐音梗异或xor
得到zip
解压得到一张jpg
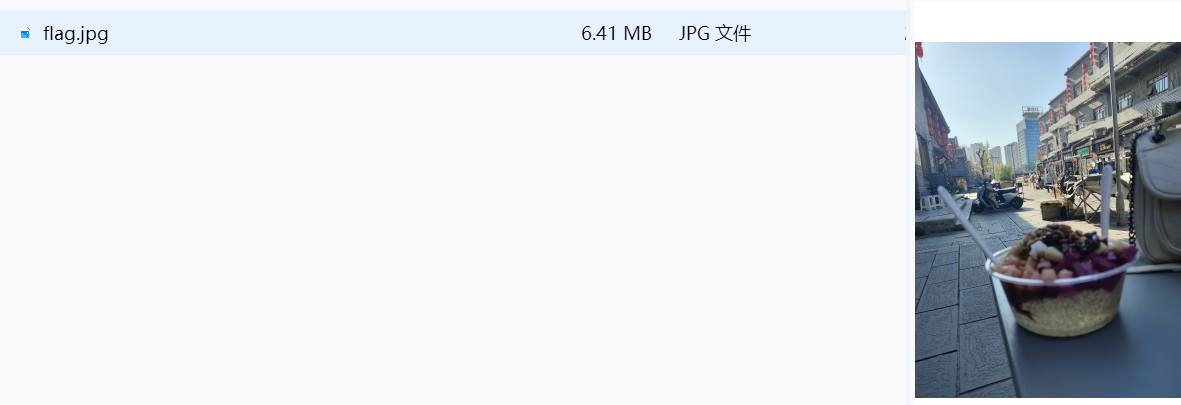

提示flag{xx省xx市xx县/区xx步行街}
直接百度社工搜图得到
flag{江苏省连云港市海州区陇海步行街}
八卦
感谢崔叔233师傅的点播
查看图片exif信息
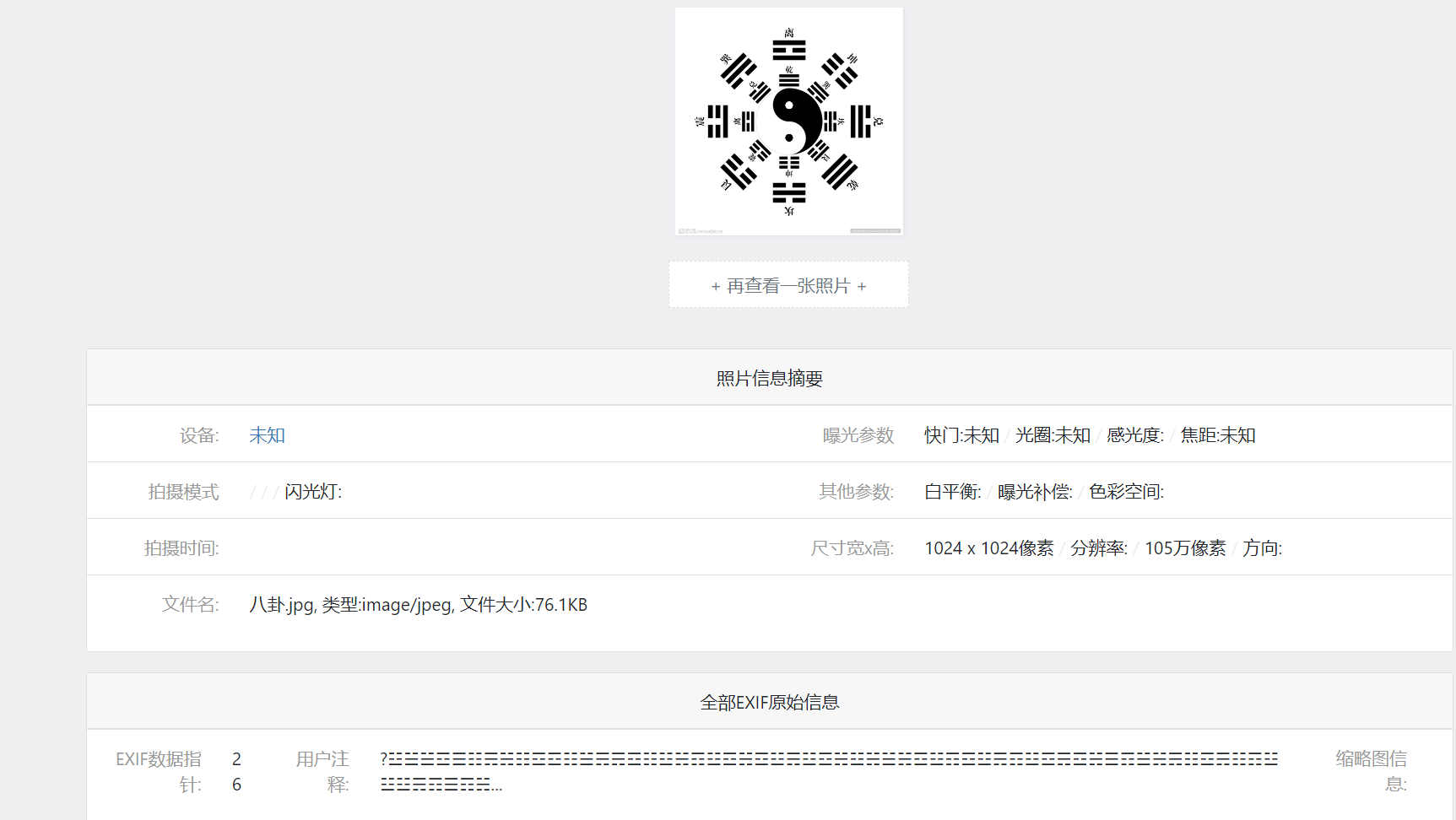
存在注释
☵☱☳☱☱☲☰☷☴☵☷☲☲☷☱☴☴☲☷☳☵☶☳☲☵☲☳☴☳☲☵☳☵☱☵☲☳☶☲☳☴☶☳☲☴☲☵☰☶☱☵☴☷☲☴☷☶☳☳☳☴☶☰☶☵☱☳☲☴☷☰☶☵☶☷☱☶☷☱☵☶☲☵☱☰☶☵☳☵☲☱☱☱☶☱☲☵☱☳☴☷☶☵☵☴☵☷☱☶☶☲☳☶☱☵☳☰☲☳☵☶☳☵☳☶☷☱☲☴☶☳☲☷☳☰☲☶☰☵
转三位二进制
# 定义符号到二进制的映射
hexagram_map = {
'☰': '111', '☱': '110', '☲': '101', '☳': '100',
'☴': '011', '☵': '010', '☶': '001', '☷': '000'
}
# 转换序列
symbols = '☵☱☳☱☱☲☰☷☴☵☷☲☲☷☱☴☴☲☷☳☵☶☳☲☵☲☳☴☳☲☵☳☵☱☵☲☳☶☲☳☴☶☳☲☴☲☵☰☶☱☵☴☷☲☴☷☶☳☳☳☴☶☰☶☵☱☳☲☴☷☰☶☵☶☷☱☶☷☱☵☶☲☵☱☰☶☵☳☵☲☱☱☱☶☱☲☵☱☳☴☷☶☵☵☴☵☷☱☶☶☲☳☶☱☵☳☰☲☳☵☶☳☵☳☶☷☱☲☴☶☳☲☷☳☰☲☶☰☵'
binary_str = ''.join([hexagram_map[s] for s in symbols])
octal_str = ''.join([str(int(binary_str[i:i+3], 2)) for i in range(0, len(binary_str), 3)])
print("二进制:", binary_str)
010110100110110101111000011010000101101000110011011101000100010001100101010101100011100101010100010110010101100001101100011001100101011101010111001110010011000101011000001100100100011001111001010110100101011000111001010001000110001000110010001101010110111001010100010101110110110001110101010110100011000001010010011010000110001001101100001110010100111101100010001100010100001000110101011001100101000100111101001111010
每 8 个为一组,不够 8 个的删掉,最后转成ascii
binary_str = "01011010011011010111100001101000010110100011001101110100010001000110010101010110001110010101010001011001010110000110110001100110010101110101011100111001001100010101100000110010010001100111100101011010010101100011100101000100011000100011001000110101011011100101010001010111011011000111010101011010001100000101001001101000011000100110110000111001010011110110001000110001010000100011010101100110010100010011110100111101"
# 每 8 位一组分割,不足 8 位的丢弃
groups = [binary_str[i:i+8] for i in range(0, len(binary_str), 8) if len(binary_str[i:i+8]) == 8]
# 转换为 ASCII 字符
ascii_str = ''.join([chr(int(group, 2)) for group in groups])
print(ascii_str)
ZmxhZ3tDeV9TYXlfWW91X2FyZV9Db25nTWluZ0Rhbl9Ob1B5fQ==
解个base64即可
flag{Cy_Say_You_are_CongMingDan_NoPy}
2025第一届轩辕杯Misc详解的更多相关文章
- Asp.Net MVC3 简单入门第一季(三)详解Controller之Filter
前言 前面两篇写的比较简单,刚开始写这个系列的时候我面向的对象是刚开始接触Asp.Net MVC的朋友,所以写的尽量简单.所以写的没多少技术含量.把这些技术总结出来,然后一简单的方式让更多的人很好的接 ...
- [转载] Java高新技术第一篇:类加载器详解
本文转载自: http://blog.csdn.net/jiangwei0910410003/article/details/17733153 首先来了解一下字节码和class文件的区别: 我们知道, ...
- Java高新技术第一篇:类加载器详解
首先来了解一下字节码和class文件的区别: 我们知道,新建一个Java对象的时候,JVM要将这个对象对应的字节码加载到内存中,这个字节码的原始信息存放在classpath(就是我们新建Java工程的 ...
- 江西财经大学第一届程序设计竞赛 F题 解方程
链接:https://www.nowcoder.com/acm/contest/115/F来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 32768K,其他语言65536 ...
- 第一行代码阅读笔记---详解分析第一个Android程序
以下是我根据作者的思路,创建的第一个Android应用程序,由于工具强大,代码都自动生成了,如下: package com.example.first_app; import android.os.B ...
- 第一篇:Git操作详解
最近由于项目的需要,我需要负责整个项目的托管,其中涉及到很多Git相关的命令,所以就将之前用到的git相关的命令做了一个总结和归纳.由于开发环境是Linux,所以我接下来的操作命令均针对Linux环境 ...
- OpenStack计费项目Cloudkitty系列详解(一)
云计算是一种按需付费的服务模式,虽然OpenStack前期在计量方面走了些“弯路”,但现在的ceilometer.gnocchi.aodh.panko项目的稳步并进算是让其峰回路转.然而,目前来看Op ...
- POSIX 线程详解(经典必看)
http://www.cnblogs.com/sunminmin/p/4479952.html 总共三部分: 第一部分:POSIX 线程详解 ...
- 《Java面试全解析》505道面试题详解
<Java面试全解析>是我在 GitChat 发布的一门电子书,全书总共有 15 万字和 505 道 Java 面试题解析,目前来说应该是最实用和最全的 Java 面试题解析了. 我本人是 ...
- 《Java面试全解析》1000道面试题大全详解(转)
<Java面试全解析>1000道 面试题大全详解 本人是 2009 年参加编程工作的,一路上在技术公司摸爬滚打,前几年一直在上海,待过的公司有 360 和游久游戏,因为自己家庭的原因,放弃 ...
随机推荐
- allure 报告空白
在pycharm 运行py文件后生成的报告内容空白: 尝试方法 替换allure版本号---不好用 用命令生成.html测试报告,再以浏览器形式打开 ** ** 命令 allure generate ...
- LaTeX使用记录
安装与使用 曾在Windows10下装过MikTeX,并配合vscode插件LaTeX Workshop使用过一段时间:这次转到wsl2中,并使用texlive,所以插件的配置json需要小修改 参考 ...
- (Python)用栈实现计算器的原理及实现
前言 我们日常使用的计算器是怎么实现计算的呢?能自己判断运算符的优先级去计算,能处理括号的匹配,这些都是怎么实现的呢? 一个大家熟知的答案是用栈,好的,那么为什么要用栈?为什么栈能实现呢? 目录 前言 ...
- ModuleNotFoundError: No module named '_bz2'
前言 运行 python 报错:ModuleNotFoundError: No module named '_bz2' when building python 解决 安装在 Ubuntu/Debia ...
- Ollama系列05:Ollama API 使用指南
本文是Ollama系列教程的第5篇,在前面的4篇内容中,给大家分享了如何再本地通过Ollama运行DeepSeek等大模型,演示了chatbox.CherryStudio等UI界面中集成Ollama的 ...
- Hololens2 开发(仿真器)配置
博客地址:https://www.cnblogs.com/zylyehuo/ 参考链接 1.hololens 开发(仿真器)环境配置 2.visual studio 2019安装后添加工作负载 3.H ...
- Docker 运行命令
停止所有的容器 docker stop $(docker ps -aq) 启动所有的容器 docker start $(docker ps -aq) 停止容器 docker stop <容器Na ...
- How to grow old
An individual human existence should be like a river-small at first,narrowly contained within its ba ...
- leetcode每日一题:监控二叉树
引言 今天的每日一题原题是2643. 一最多的行,直接模拟,切除和最大的一行即可.更换成前几天遇到的更有意思的一题来写这个每日一题. 题目 968. 监控二叉树 给定一个二叉树,我们在树的节点上安 ...
- DEF4Delphi-master的安装
保姆教程 d2007的TWEBbrowser因为用的太老的IE内核.现在的浏览器上的功能呈现就卡住了. 那么DEF4Delphi效果非常好. 如何安装后成功运行.很简单.直接去:https://git ...