机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering)
1.1 无监督学习: 简介
在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签,我们需要据此拟合一个假设函数。与此不同的是,在非监督学习中,我们的数据没有附带任何标签,我们拿到的数据就是这样的:
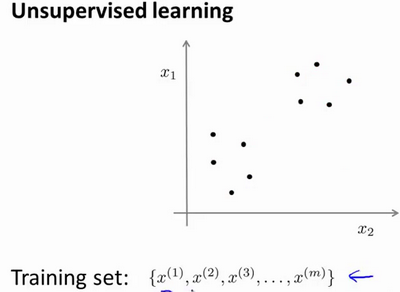
在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法,快去为我们找找这个数据的内在结构给定数据。我们可能需要某种算法帮助我们寻找一种结构。图上的数据看起来可以分成 两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
这将是我们介绍的第一个非监督学习算法。当然,此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者其他的一些模式,而不只是簇。
1.11 聚类算法用途

1.2 K-均值算法
K-均值 是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-均值 是一个迭代算法,假设我们想要将数据 聚类成n个组,其方法为:
首先选择 K 个随机的点,称为聚类中心(cluster centroids);
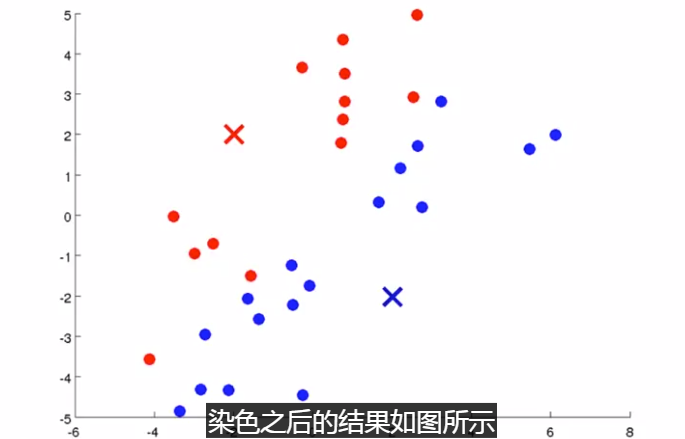
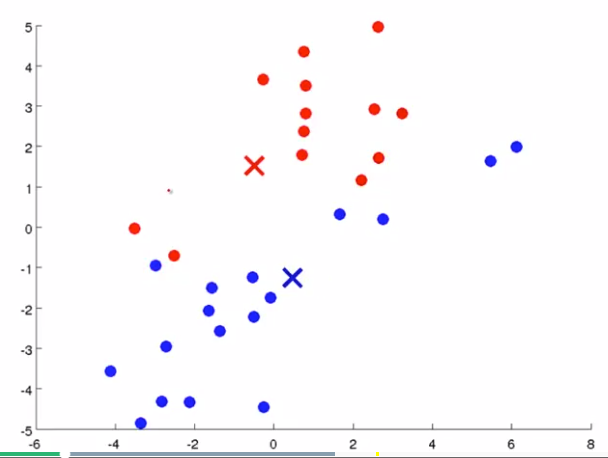
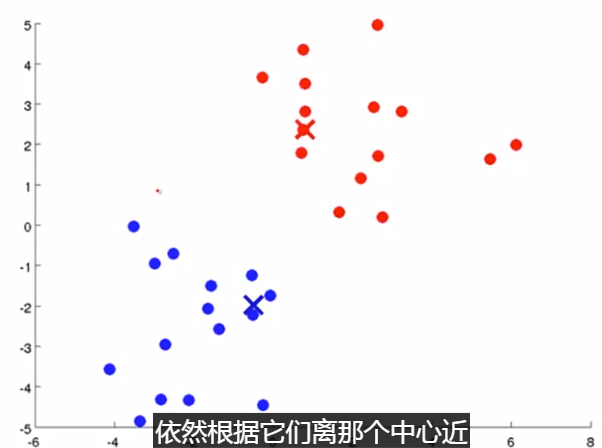
簇分配:对于数据集中的每一个数据,按照 距离 K个中心点的距离,将其 与距离最近的中心点 关联起来,与 同一个中心点 关联的所有点聚成一类。
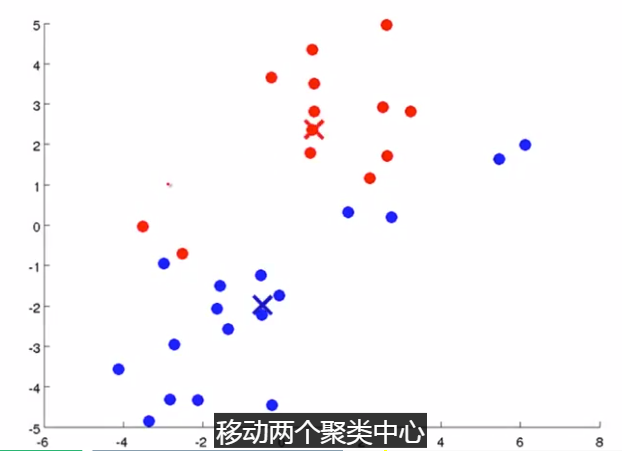
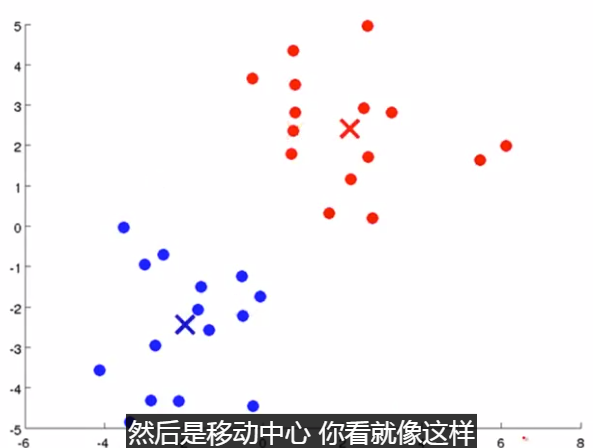
移动聚类中心:计算每一个组的平均值,将该组 所关联的中心点 移动到 该组平均值的位置。
重复步骤2-4直至中心点不再变化。
下面是一个聚类示例:
(簇分配) (移动聚类中心)

重复该步骤。

Repeat {
for i = to m # 簇分配
c(i) := index (form to K) of cluster centroid closest to x(i) # 是接近 哪一个聚类中心 k; c(i) = min_k:||x^(i) - u_k||^2
for k = to K # 移动聚类中心
μk := average (mean) of points assigned to cluster k
}

注意:
没有分配点的聚类中心直接删除;
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在 没有非常明显区分的组群 的情况下也可以。
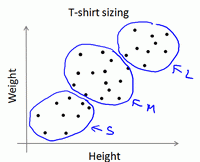
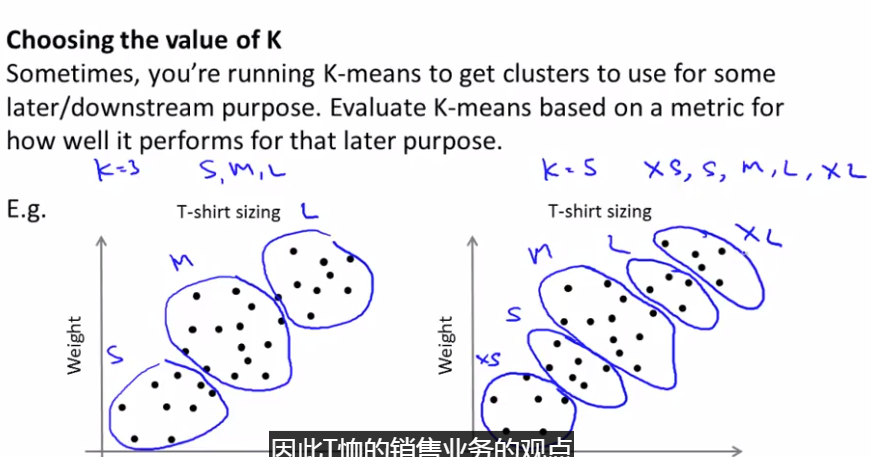
下图所示的数据集包含 身高和体重 两项特征构成的,利用K-均值算法将数据分为三类,用于帮助确定将要生产的T-恤衫的三种尺寸。
1.3 优化目标
K-均值最小化问题:最小化 所有的数据点 与 其所关联的聚类中心点 之间的 距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
$$J(c^{(1)},...,c^{(m)},μ_1,...,μ_K)=\dfrac {1}{m}\sum^{m}_{i=1}\left\| X^{\left( i\right) }-\mu_{c^{(i)}}\right\| ^{2}$$
其中 ${{\mu }_{{{c}^{(i)}}}}$ 代表与 ${{x}^{(i)}}$ 最近的聚类中心点。
优化目标:
- 找出使得代价函数最小的 $c^{(1)}$,$c^{(2)}$,...,$c^{(m)}$ 和 $μ^1$,$μ^2$,...,$μ^k$:
 (代价函数会一直变小,不可能上升)
(代价函数会一直变小,不可能上升)


1.4 随机初始化
在运行K-均值算法的之前,我们首先要 随机初始化 所有的聚类中心点,下面介绍怎样做:
- 我们应该选择 $K<m$,即 聚类中心点的个数 要小于 所有训练集实例的数量
- 随机选择 $K$ 个训练实例,然后令 $K$ 个聚类中心分别与这 $K$ 个训练实例相等
K-均值 的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。

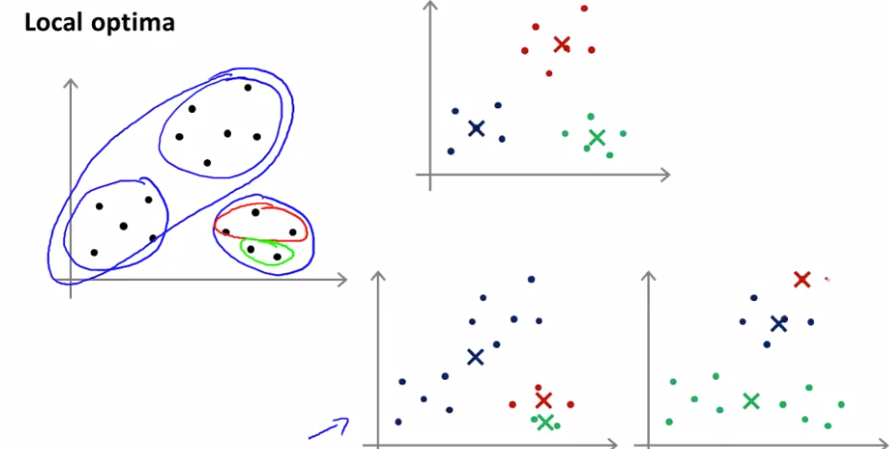
尝试多次随机初始化

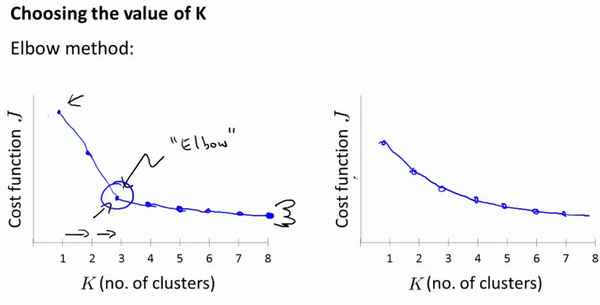
1.5 选择聚类数
没有所谓最好的 选择聚类数目 的方法,通常是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能 最好 服务于该目的 的聚类数。
当人们在讨论,选择聚类数目 的方法时, “肘部法则”:
改变 K 值,也就是 聚类类别数目的总数。我们用一个聚类来运行 K均值聚类方法。
这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数或者计算畸变函数 J 。K 代表聚类数字。
机器学习课程-第8周-聚类(Clustering)—K-Mean算法的更多相关文章
- 机器学习(九)-------- 聚类(Clustering) K-均值算法 K-Means
无监督学习 没有标签 聚类(Clustering) 图上的数据看起来可以分成两个分开的点集(称为簇),这就是为聚类算法. 此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- 机器学习课程-第7周-支持向量机(Support Vector Machines)
1. 优化目标 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的 ...
- Andrew Ng机器学习课程,第一周作业,python版本
Liner Regression 1.梯度下降算法 Cost Function 对其求导: theta更新函数: 代码如下: from numpy import * import numpy as n ...
- Andrew Ng机器学习课程笔记--汇总
笔记总结,各章节主要内容已总结在标题之中 Andrew Ng机器学习课程笔记–week1(机器学习简介&线性回归模型) Andrew Ng机器学习课程笔记--week2(多元线性回归& ...
- SIGAI机器学习第二十四集 聚类算法1
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用. 大纲: 聚类问题简介聚类算法的分类层次聚类算法 ...
- 机器学习之&&Andrew Ng课程复习--- 聚类——Clustering
第十三章.聚类--Clustering ******************************************************************************** ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 13—Clustering 聚类
Lecture 13 聚类 Clustering 13.1 无监督学习简介 Unsupervised Learning Introduction 现在开始学习第一个无监督学习算法:聚类.我们的数据没 ...
- Stanford机器学习笔记-9. 聚类(Clustering)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
随机推荐
- 转帖--计算机网络基础知识大总汇 https://www.jianshu.com/p/674fb7ec1e2c?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
计算机网络基础知识大总汇 龙猫小爷 关注 2016.09.14 23:01* 字数 12761 阅读 30639评论 35喜欢 720 一.什么是TCP/IP 网络和协议 1. TCP/IP是 ...
- python学习笔记四——循环及冒泡排序
3.3.3 break 和 continue语句 break:跳出整个循环 continue:跳出当前循环继续后面的循环 例: x=int(input("please input the ' ...
- python之FTP上传和下载
# FTP操作 import ftplib host = '192.168.20.191' username = 'ftpuser' password = 'ftp123' file = '1.txt ...
- Lodop打印设计(PRINT_DESIGN)里的快捷键
Lodop打印控件,给开发人员提供了可视化编辑工具,编辑后可生成代码,然后复制到自己程序代码中,让开发更简单,打印设计中有一些快捷键也能让开发更便捷. 打印设计快捷键:ctrl 多个选中Shift 左 ...
- jdk1.8 HashMap扩容原理详解
JDK1.7中,resize时,index取得时,全部采用重新hash的方式进行了.JDK1.8对这个进行了改善. 以前要确定index的时候用的是(e.hash & oldCap-1),是取 ...
- codeforces518B
Tanya and Postcard CodeForces - 518B 有个小女孩决定给他的爸爸寄明信片.她已经想好了一句话(即长度为n的字符串s),包括大写和小写英文字母.但是他不会写字,所以她决 ...
- 【刷题】AtCoder Regular Contest 003
A.GPA計算 题意:\(n\) 个人,一个字符串表示每个人的等第,每种等第对应一种分数.问平均分 做法:算 #include<bits/stdc++.h> #define ui unsi ...
- LOJ #6270. 数据结构板子题 (离线+树状数组)
题意 有 \(n\) 个区间,第 \(i\) 个区间是 \([l_i,r_i]\) ,它的长度是 \(r_i-l_i\) . 有 \(q\) 个询问,每个询问给定 \(L,R,K\) ,询问被 \([ ...
- Spring Cloud(五) --- zuul
微服务网关 在微服务架构中,后端服务往往不直接开放给调用端,而是通过一个API网关根据请求的url,路由到相应的服务.当添加API网关后,在第三方调用端和服务提供方之间就创建了一面墙,这面墙直接与调用 ...
- 读取2007以上版本的excel(xslx格式)
maven项目依赖jar包 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi ...