084 HBase的数据迁移(含HDFS的数据迁移)
1.查找命令
bin/hadoop
2.启动两个HDFS集群
hadoop0,hadoop1,都是伪分布式的集群
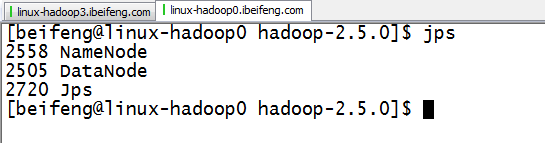
3.启动hadoop3的zookeeper与hbase
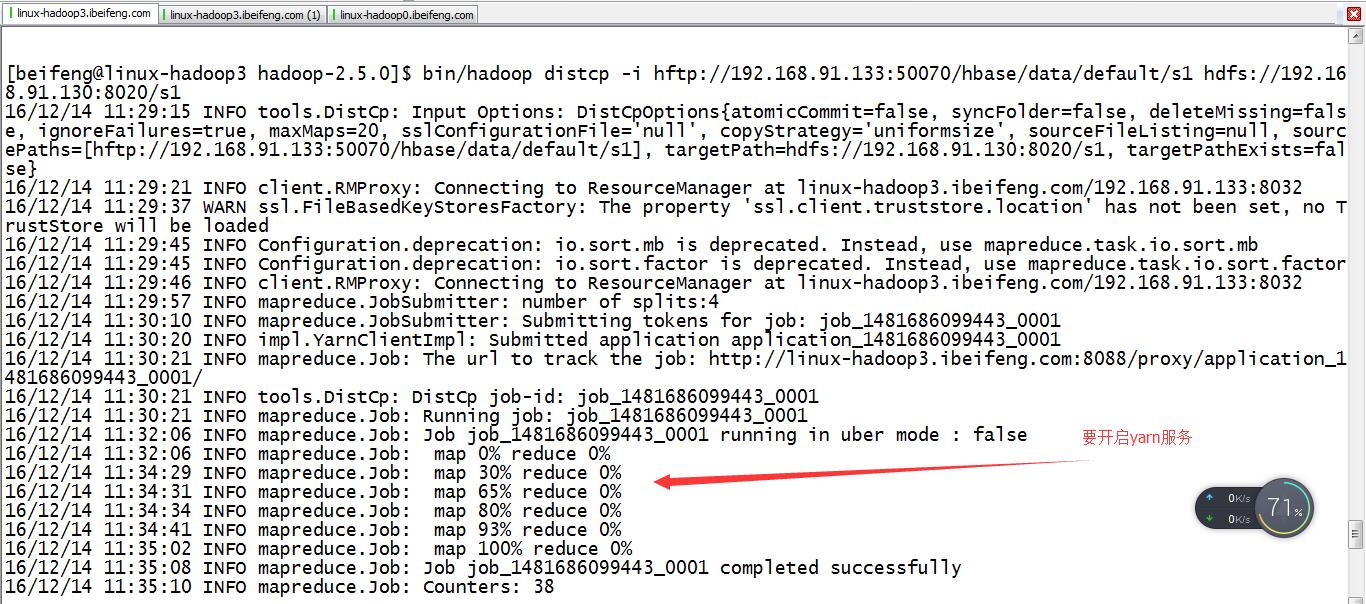
注意点:需要开启yarn服务,因为distcp需要yarn。
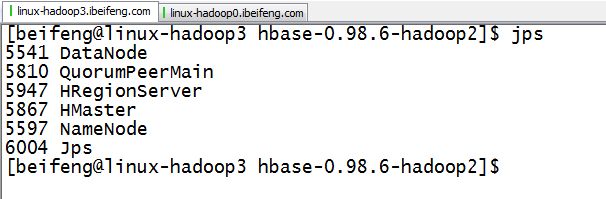
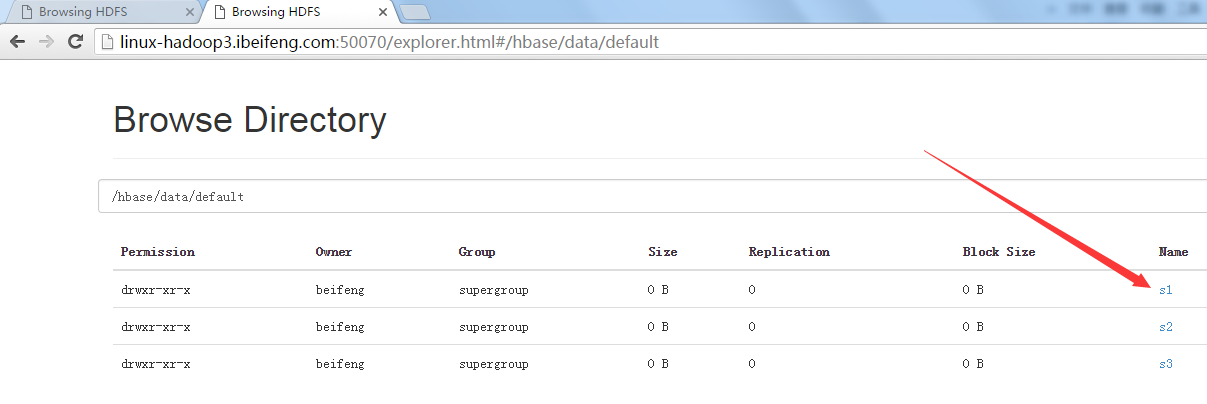
3.在hdfs上可以看到hadoop3上有表s1.
4.官网
下面使用的情况是:不同版本的集群之间进行拷贝,建议查官网。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

5.拷贝hadoop3上的s1到hadoop0
bin/hadoop distcp -i hftp://192.168.91.133:50070/hbase/data/default/s1 hdfs://192.168.91.130:8020/s1
使用hadoop的distcp,因为hbase底层是HDFS,所以要拷贝底层数据,后面关于表,在使用hbase的修复。
hadoop的修复可以看命令bin/hdfs。
hbase的修复命令可以看bin/hbase。
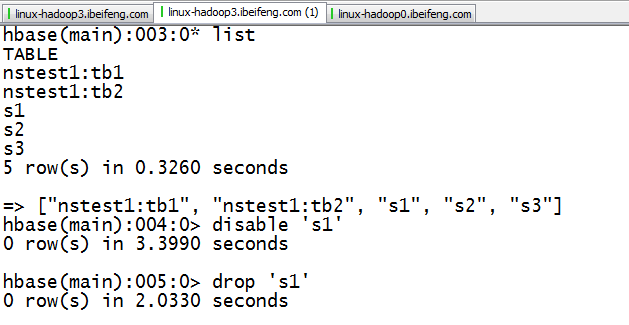
5.删除在hadoop3中的元数据
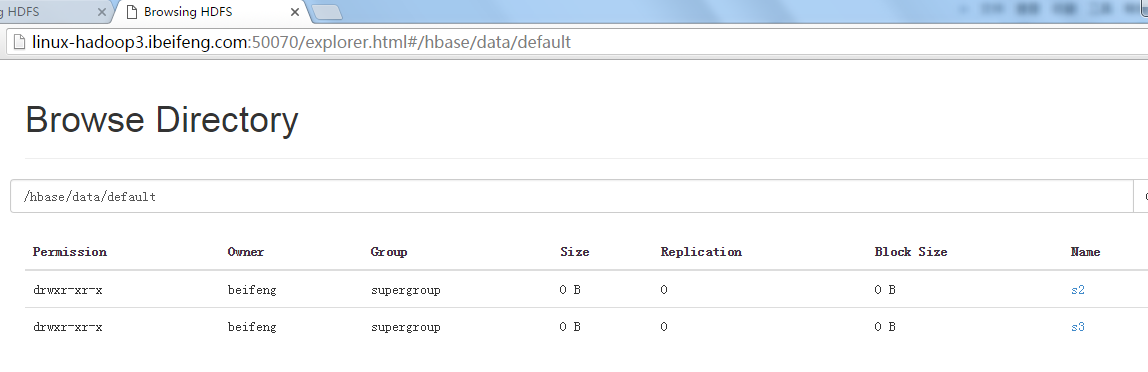
6.在hadoop3的hdfs上同样不再有数据s1
7.重新把数据从hadoop0上迁移到hadoop3上
bin/hadoop distcp -i hftp://192.168.91.130:50070/s1 hdfs://192.168.91.133:8020/hbase/data/default/s1

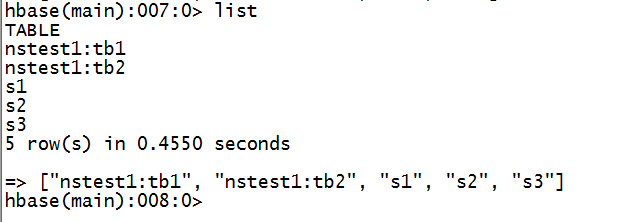
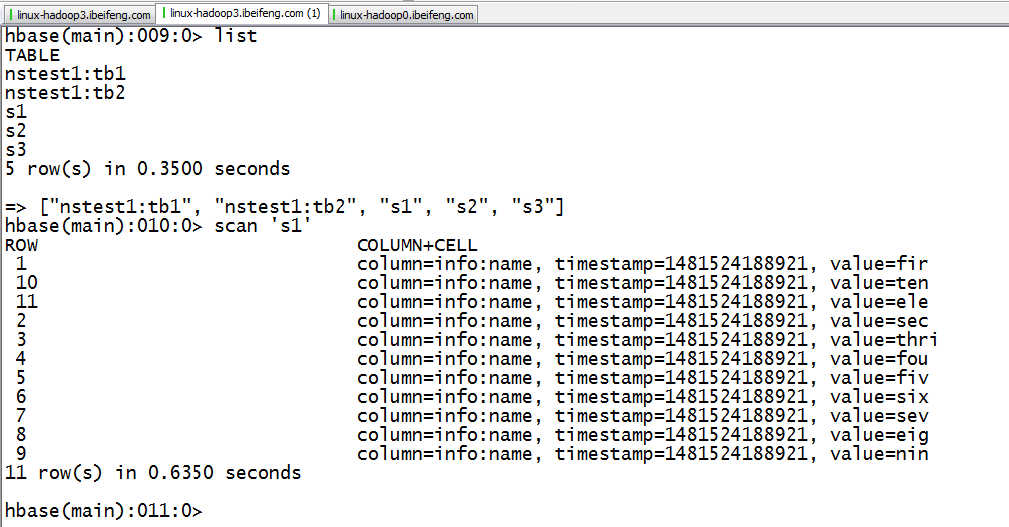
8.hbase中状况
9.修复元数据
bin/hbase hbck -fixAssignments -fixMeta
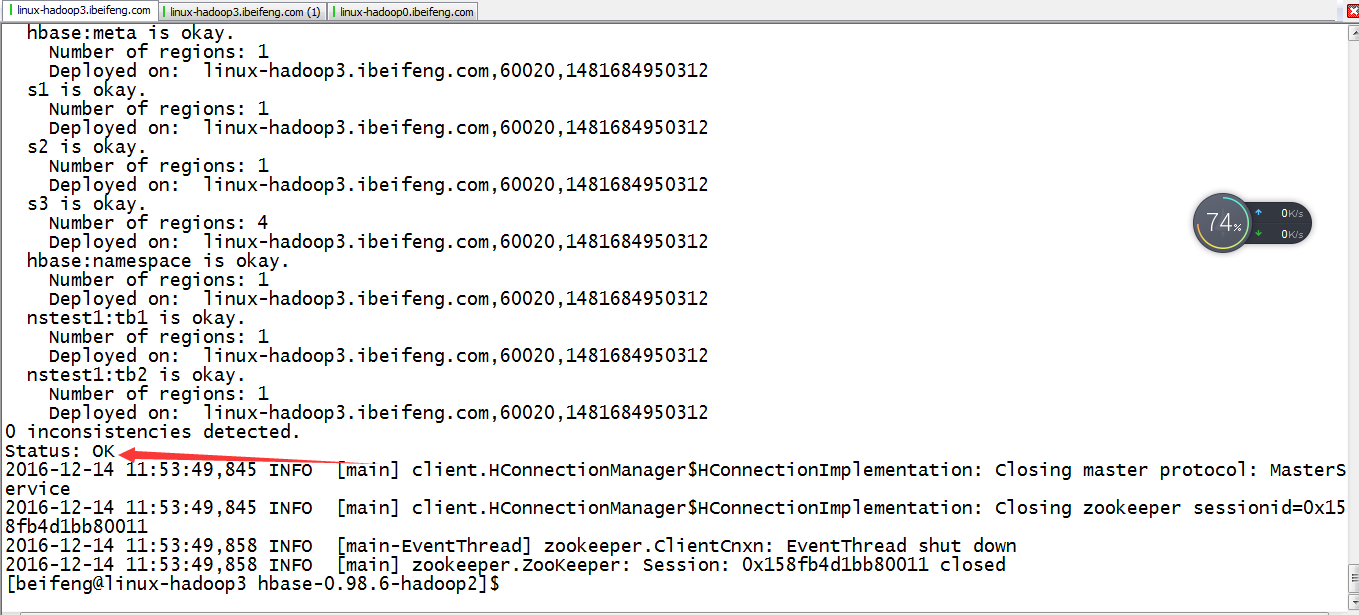
10.使用
084 HBase的数据迁移(含HDFS的数据迁移)的更多相关文章
- HBase的数据迁移(含HDFS的数据迁移)
1.启动两个HDFS集群 hadoop0,hadoop1,都是伪分布式的集群 2.启动hadoop3的zookeeper与hbase 注意点:需要开启yarn服务,因为distcp需要yarn. 3. ...
- 把kafka数据从hbase迁移到hdfs,并按天加载到hive表(hbase与hadoop为不同集群)
需求:由于我们用的阿里云Hbase,按存储收费,现在需要把kafka的数据直接同步到自己搭建的hadoop集群上,(kafka和hadoop集群在同一个局域网),然后对接到hive表中去,表按每天做分 ...
- Hbase实用技巧:全量+增量数据的迁移方法
摘要:本文介绍了一种Hbase迁移的方法,可以在一些特定场景下运用. 背景 在Hbase使用过程中,使用的Hbase集群经常会因为某些原因需要数据迁移.大多数情况下,可以跟用户协商用离线的方式进行迁移 ...
- HBase数据导出到HDFS
一.目的 把hbase中某张表的数据导出到hdfs上一份. 实现方式这里介绍两种:一种是自己写mr程序来完成,一种是使用hbase提供的类来完成. 二.自定义mr程序将hbase数据导出到hdfs上 ...
- 使用MapReduce查询Hbase表指定列簇的全部数据输出到HDFS(一)
package com.bank.service; import java.io.IOException; import org.apache.hadoop.conf.Configuration;im ...
- Sqoop(三)将关系型数据库中的数据导入到HDFS(包括hive,hbase中)
一.说明: 将关系型数据库中的数据导入到 HDFS(包括 Hive, HBase) 中,如果导入的是 Hive,那么当 Hive 中没有对应表时,则自动创建. 二.操作 1.创建一张跟mysql中的i ...
- Hadoop源码分析之客户端向HDFS写数据
转自:http://www.tuicool.com/articles/neUrmu 在上一篇博文中分析了客户端从HDFS读取数据的过程,下面来看看客户端是怎么样向HDFS写数据的,下面的代码将本地文件 ...
- 大数据(1)---大数据及HDFS简述
一.大数据简述 在互联技术飞速发展过程中,越来越多的人融入互联网.也就意味着各个平台的用户所产生的数据也越来越多,可以说是爆炸式的增长,以前传统的数据处理的技术已经无法胜任了.比如淘宝,每天的活跃用户 ...
- hdfs冷热数据分层存储
hdfs如何让某些数据查询快,某些数据查询慢? hdfs冷热数据分层存储 本质: 不同路径制定不同的存储策略. hdfs存储策略 hdfs的存储策略 依赖于底层的存储介质. hdfs支持的存储介质: ...
随机推荐
- <转载>iTerm2使用技巧
原文链接:http://www.cnblogs.com/756623607-zhang/p/7071281.html 1.设置窗口 定位到 [Preferences - Profiles - Wi ...
- Java垃圾回收机制复习
一.如何确定某个对象是“垃圾” 二.典型的垃圾收集算法 三.典型的垃圾收集器 JVM(HotSpot) 7种垃圾收集器的特点及使用场景 https://www.cnblogs.com/chengxuy ...
- 升级版updateOozie.sh
以前的版本检测当天的Tar包,并只能选择1个Tar包进行更新代码,当天生成多个版本时需修改脚本中配置,并不方便. 升级版兼容目录下存在一个或者多个Tar包的情况: 1.单个Tar包时,直接解压缩到当前 ...
- 嵌入式linux系统中,lsusb出现unable to initialize libusb: -99 解决办法 【转】
转自:http://cpbest.blog.163.com/blog/static/41241519201111575726966/ libusb是linux系统中,提供给用户空间访问usb设备的AP ...
- xpath与nodejs解析xml
测试xpath的工具 http://www.freeformatter.com/xpath-tester.html#ad-output http://www.xpathtester.com/test ...
- 【转】Visual Studio——多字节编码与Unicode码
多字节字符与宽字节字符 1) char与wchar_t 我们知道C++基本数据类型中表示字符的有两种:char.wchar_t. char叫多字节字符,一个char占一个字节,之所以叫多字节字符是因为 ...
- Cleaning up old NVIDIA driver files
原文地址:https://www.gameplayinside.com/optimize/cleaning-up-old-nvidia-driver-files-to-save-disk-space/ ...
- 《TCP/IP 详解 卷1:协议》第 3 章:链路层
在体系结构中,我们知道:链路层(或数据链路层)包含为共享相同介质的邻居建立连接的协议和方法,同时,设计链路层的目的是为 IP 模块发送和接受 IP 数据报,链路层可用于携带支持 IP 的辅助性协议,例 ...
- mysql更新字段值提示You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode
1 引言 当更新字段缺少where语句时,mysql会提示一下错误代码: Error Code: 1175. You are using safe update mode and you tried ...
- sklearn调参(验证曲线,可视化不同参数下交叉验证得分)
一 . 原始方法: 思路: 1. 参数从 0+∞ 的一个 区间 取点, 方法如: np.logspace(-10, 0, 10) , np.logspace(-6, -1, 5) 2. 循环调用cr ...