sklearn调参(验证曲线,可视化不同参数下交叉验证得分)
一 、 原始方法:
思路:
1. 参数从 0+∞ 的一个 区间 取点, 方法如: np.logspace(-10, 0, 10) , np.logspace(-6, -1, 5)
2. 循环调用cross_val_score计算得分。
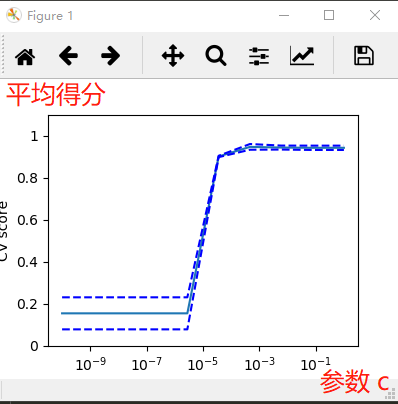
在SVM不同的惩罚参数C下的模型准确率。
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
import numpy as np
from sklearn import datasets, svm
digits = datasets.load_digits()
x = digits.data
y = digits.target
vsc = svm.SVC(kernel='linear') if __name__=='__main__':
c_S = np.logspace(-10, 0, 10)#在范围内取是个对数
# print ("length", len(c_S))
scores = list()
scores_std = list()
for c in c_S:
vsc.C = c
this_scores = cross_val_score(vsc, x, y, n_jobs=4)#多线程 n_jobs,默认三次交叉验证
scores.append(np.mean(this_scores))
scores_std.append(np.std(this_scores))
plt.figure(1, figsize=(4, 3))#绘图
plt.clf()
plt.semilogx(c_S, scores)#划线
plt.semilogx(c_S, np.array(scores)+np.array(scores_std), 'b--')
plt.semilogx(c_S, np.array(scores)-np.array(scores_std), 'b--')
locs, labels = plt.yticks()
plt.yticks(locs, list(map(lambda X: "%g" % X, locs)))#阶段点
plt.ylabel('CV score')
plt.xlabel('parameter C')
plt.ylim(0, 1.1)#范围
plt.show()
效果:
二、高级方法(validation_curve)
思路:
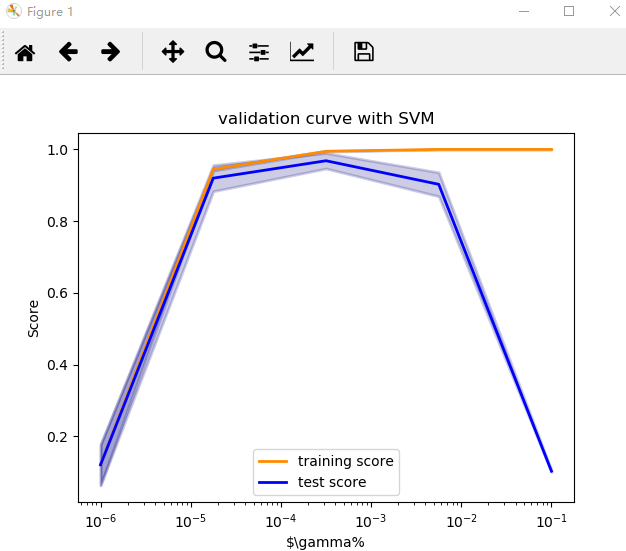
直接用validation_curve获得模型在不同参数下,每次训练得分和测试得分。
from sklearn import svm
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_digits
import numpy as np
import matplotlib.pyplot as plt
digits = load_digits()
X = digits.data
y = digits.target
param_range = np.logspace(-6, -1, 5)
vsc = svm.SVC()
train_score, test_score = validation_curve(vsc, X, y, param_name='gamma', param_range=param_range, cv=10, scoring="accuracy", n_jobs=1)
train_score_mean = np.mean(train_score, axis=1)
train_score_std = np.std(train_score, axis=1)
test_score_mean = np.mean(test_score, axis=1)
test_score_std = np.std(test_score, axis=1)
plt.title("validation curve with SVM")
plt.xlabel("$\gamma%")
plt.ylabel("Score")
plt.ylim()
lw = 2
plt.semilogx(param_range, train_score_mean,label="training score", color="darkorange", lw=lw)
plt.fill_between(param_range, train_score_mean-train_score_std, train_score_mean+train_score_std, alpha=0.2, color="navy", lw=lw)
plt.semilogx(param_range, test_score_mean,label="test score", color="blue", lw=lw)
plt.fill_between(param_range, test_score_mean-test_score_std, test_score_mean+test_score_std, alpha=0.2, color="navy", lw=lw)
plt.legend(loc="best")
plt.show()
结果:
sklearn调参(验证曲线,可视化不同参数下交叉验证得分)的更多相关文章
- 普通交叉验证(OCV)和广义交叉验证(GCV)
普通交叉验证OCV OCV是由Allen(1974)在回归背景下提出的,之后Wahba和Wold(1975)在讨论 了确定多项式回归中多项式次数的背景,在光滑样条背景下提出OCV. Craven和Wa ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
- python 机器学习中模型评估和调参
在做数据处理时,需要用到不同的手法,如特征标准化,主成分分析,等等会重复用到某些参数,sklearn中提供了管道,可以一次性的解决该问题 先展示先通常的做法 import pandas as pd f ...
- k-近邻算法采用for循环调参方法
//2019.08.02下午#机器学习算法中的超参数与模型参数1.超参数:是指机器学习算法运行之前需要指定的参数,是指对于不同机器学习算法属性的决定参数.通常来说,人们所说的调参就是指调节超参数.2. ...
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- GridsearchCV调参
在利用gridseachcv进行调参时,其中关于scoring可以填的参数在SKlearn中没有写清楚,就自己找了下,具体如下: parameters = {'eps':[0.3,0.4,0.5,0. ...
- LSTM调参经验
0.开始训练之前先要做些什么? 在开始调参之前,需要确定方向,所谓方向就是确定了之后,在调参过程中不再更改 1.根据任务需求,结合数据,确定网络结构. 例如对于RNN而言,你的数据是变长还是非变长:输 ...
- 【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参
上一节对XGBoost算法的原理和过程进行了描述,XGBoost在算法优化方面主要在原损失函数中加入了正则项,同时将损失函数的二阶泰勒展开近似展开代替残差(事实上在GBDT中叶子结点的最优值求解也是使 ...
随机推荐
- XML:特殊字符转换
< < 小于号 > > 大于号 & & 和 ' ' 单引号 " " 双引号 实体必须以符号& ...
- zoj3707(Calculate Prime S)解题报告
1.计算(a/b)%c,其中b能整除a 设a=b*r=(bc)*s+b*t 则(b*t)为a除以bc的余数 r=c*s+t 而 (a/b)%c=r%c=t (a%bc)/b=(b*t)/b=t 所以对 ...
- R语言画棒状图(bar chart)和误差棒(error bar)
假设我们现在有CC,CG,GG三种基因型及三种基因型对应的表型,我们现在想要画出不同的基因型对应表型的棒状图及误差棒.整个命令最重要的就是最后一句了,用arrows函数画误差棒.用到的R语言如下: d ...
- Hadoop基础-配置历史服务器
Hadoop基础-配置历史服务器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比 ...
- Unity NavMesh导航网格 初级教程
目的:要实现的功能就是你点击一下地图上的某个地方,人物就向着那个点移动.有点自动寻路的味道. 例子:三国群英传,三国赵云传之类的游戏里面的人物移动就可以用这个实现.还有一个我不太喜欢玩的游戏英雄联盟 ...
- HTTP协议学习笔记---HTTP持久连接和如何正确地关闭HTTP连接
一,持久连接 什么是持久连接?对于HTTP协议而言,它是基于请求响应模型,Client向Server发请求时,先建立一条HTTP连接,Server给Client响应数据后,连接关闭. 当Client发 ...
- CSS魔法(三)浮动、相对定位、绝对定位
浮动 为何需要浮动? 浮动float最开始出现的意义是为了让文字环绕图片而已,但人们发现,如果想要三个块级元素并排显示,都给它们加个float来得会比较方便. 浮动问题? 为何要清除浮动? 很多情况下 ...
- new和delete
和 sizeof 类似,sizeof不是函数,它是一个操作符,它在编译期就完成了计算,在函数运行期间它已经是一个常数值了. int a; sizeof(int) = 4; sizeof(a) = 4; ...
- .NET Framework 系统版本支持表
.tg {border-collapse:collapse;border-spacing:0;border-color:#aabcfe;} .tg td{font-family:Arial, sans ...
- Asp.net MVC Session过期异常的处理
一.使用MVC中的Filter来对Session进行验证 (1)方法1: public class MyAuthorizeAttribute : FilterAttribute, IAuthoriza ...