084 HBase的数据迁移(含HDFS的数据迁移)
1.查找命令
bin/hadoop
2.启动两个HDFS集群
hadoop0,hadoop1,都是伪分布式的集群
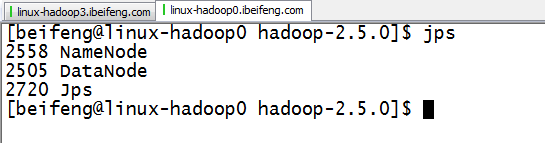
3.启动hadoop3的zookeeper与hbase
注意点:需要开启yarn服务,因为distcp需要yarn。
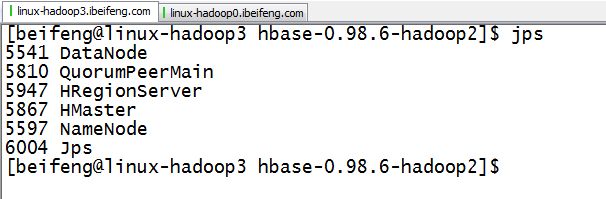
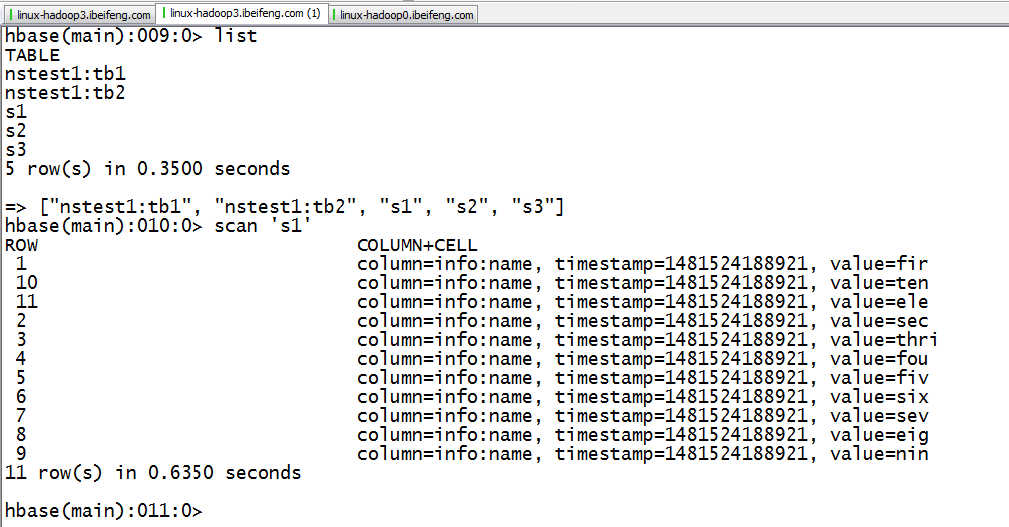
3.在hdfs上可以看到hadoop3上有表s1.
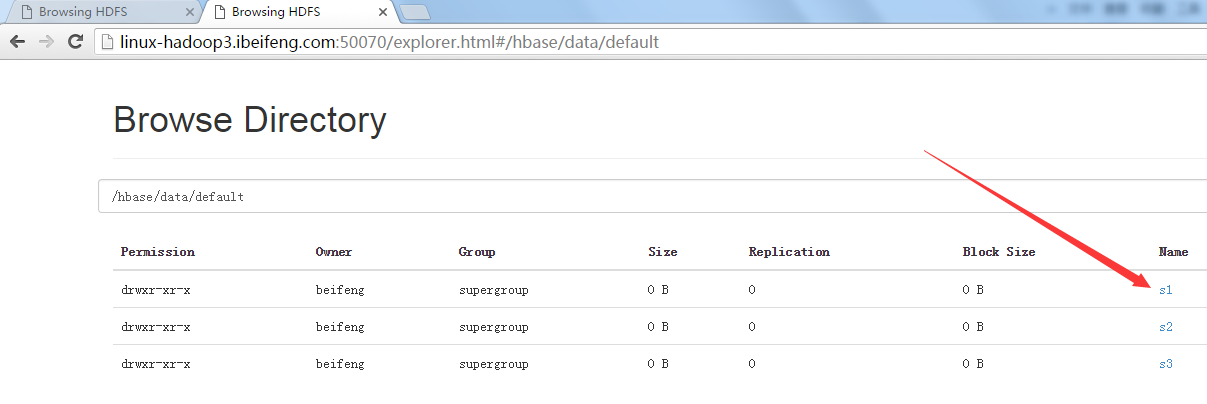
4.官网
下面使用的情况是:不同版本的集群之间进行拷贝,建议查官网。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

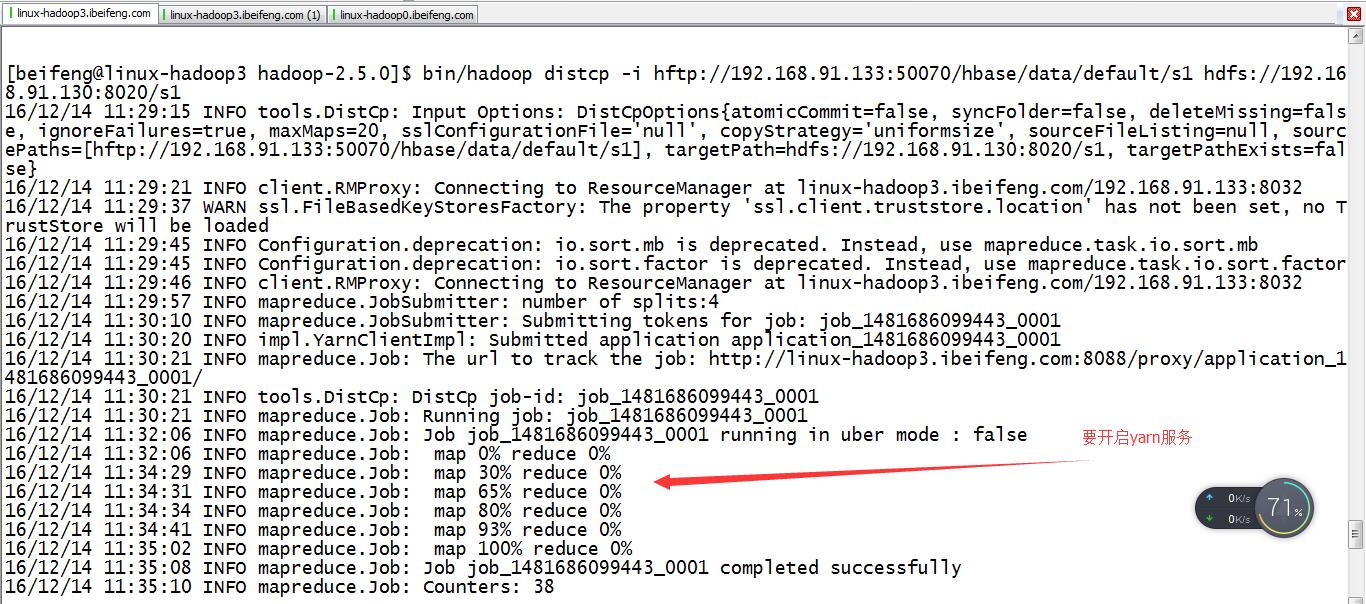
5.拷贝hadoop3上的s1到hadoop0
bin/hadoop distcp -i hftp://192.168.91.133:50070/hbase/data/default/s1 hdfs://192.168.91.130:8020/s1
使用hadoop的distcp,因为hbase底层是HDFS,所以要拷贝底层数据,后面关于表,在使用hbase的修复。
hadoop的修复可以看命令bin/hdfs。
hbase的修复命令可以看bin/hbase。
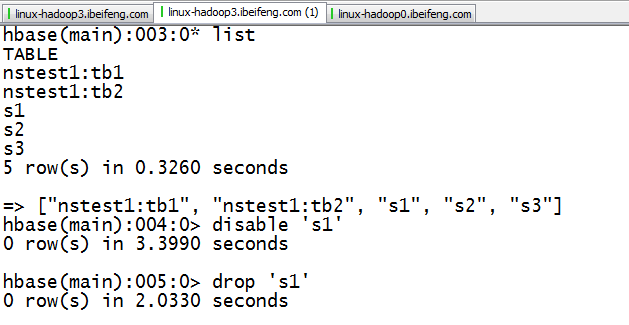
5.删除在hadoop3中的元数据
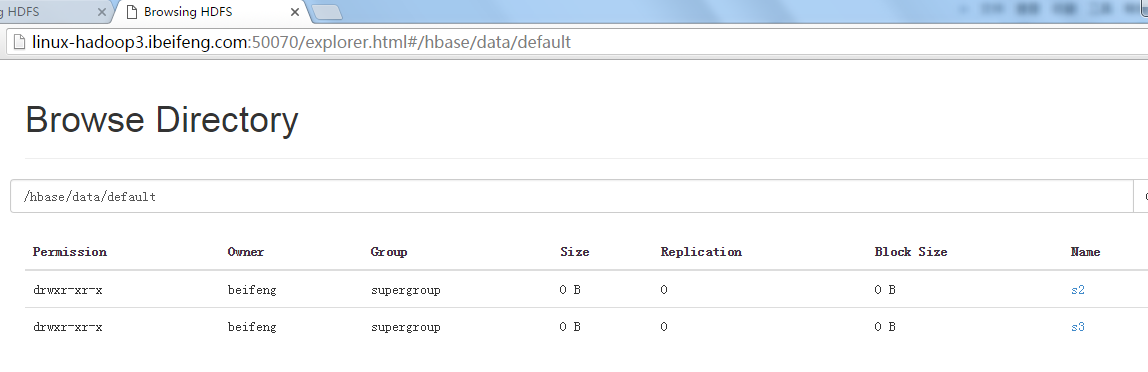
6.在hadoop3的hdfs上同样不再有数据s1
7.重新把数据从hadoop0上迁移到hadoop3上
bin/hadoop distcp -i hftp://192.168.91.130:50070/s1 hdfs://192.168.91.133:8020/hbase/data/default/s1

8.hbase中状况
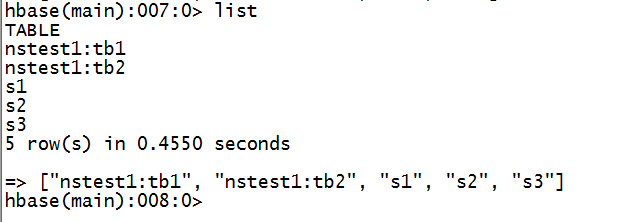
9.修复元数据
bin/hbase hbck -fixAssignments -fixMeta
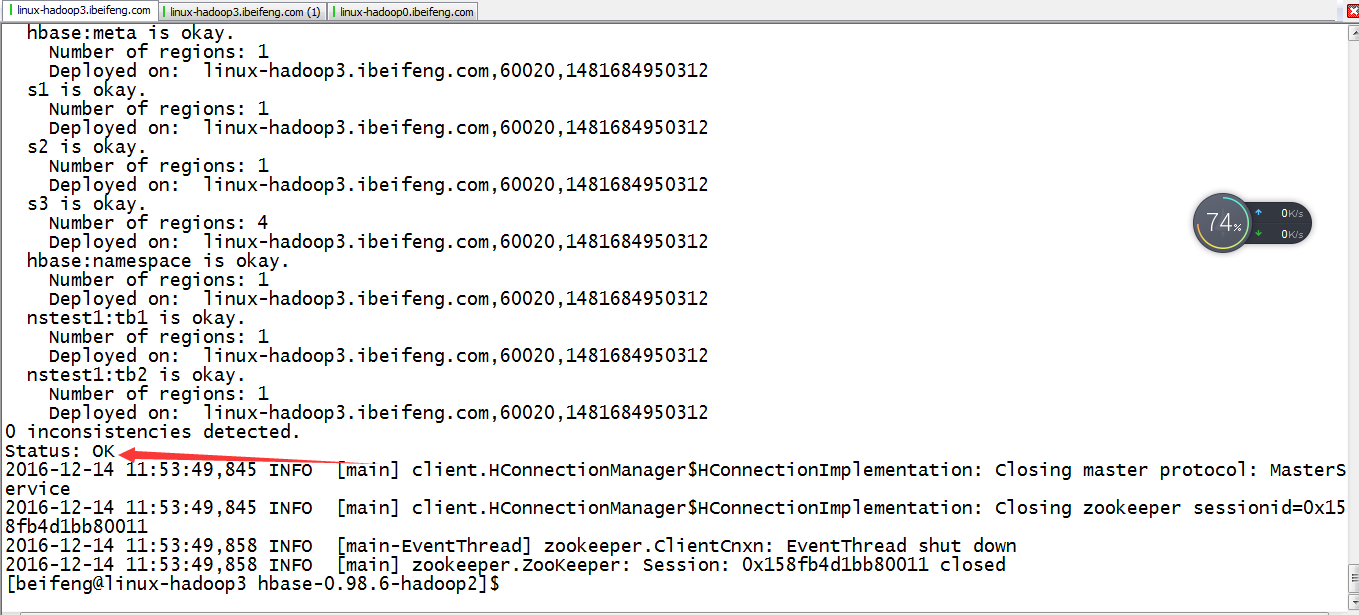
10.使用
084 HBase的数据迁移(含HDFS的数据迁移)的更多相关文章
- HBase的数据迁移(含HDFS的数据迁移)
1.启动两个HDFS集群 hadoop0,hadoop1,都是伪分布式的集群 2.启动hadoop3的zookeeper与hbase 注意点:需要开启yarn服务,因为distcp需要yarn. 3. ...
- 把kafka数据从hbase迁移到hdfs,并按天加载到hive表(hbase与hadoop为不同集群)
需求:由于我们用的阿里云Hbase,按存储收费,现在需要把kafka的数据直接同步到自己搭建的hadoop集群上,(kafka和hadoop集群在同一个局域网),然后对接到hive表中去,表按每天做分 ...
- Hbase实用技巧:全量+增量数据的迁移方法
摘要:本文介绍了一种Hbase迁移的方法,可以在一些特定场景下运用. 背景 在Hbase使用过程中,使用的Hbase集群经常会因为某些原因需要数据迁移.大多数情况下,可以跟用户协商用离线的方式进行迁移 ...
- HBase数据导出到HDFS
一.目的 把hbase中某张表的数据导出到hdfs上一份. 实现方式这里介绍两种:一种是自己写mr程序来完成,一种是使用hbase提供的类来完成. 二.自定义mr程序将hbase数据导出到hdfs上 ...
- 使用MapReduce查询Hbase表指定列簇的全部数据输出到HDFS(一)
package com.bank.service; import java.io.IOException; import org.apache.hadoop.conf.Configuration;im ...
- Sqoop(三)将关系型数据库中的数据导入到HDFS(包括hive,hbase中)
一.说明: 将关系型数据库中的数据导入到 HDFS(包括 Hive, HBase) 中,如果导入的是 Hive,那么当 Hive 中没有对应表时,则自动创建. 二.操作 1.创建一张跟mysql中的i ...
- Hadoop源码分析之客户端向HDFS写数据
转自:http://www.tuicool.com/articles/neUrmu 在上一篇博文中分析了客户端从HDFS读取数据的过程,下面来看看客户端是怎么样向HDFS写数据的,下面的代码将本地文件 ...
- 大数据(1)---大数据及HDFS简述
一.大数据简述 在互联技术飞速发展过程中,越来越多的人融入互联网.也就意味着各个平台的用户所产生的数据也越来越多,可以说是爆炸式的增长,以前传统的数据处理的技术已经无法胜任了.比如淘宝,每天的活跃用户 ...
- hdfs冷热数据分层存储
hdfs如何让某些数据查询快,某些数据查询慢? hdfs冷热数据分层存储 本质: 不同路径制定不同的存储策略. hdfs存储策略 hdfs的存储策略 依赖于底层的存储介质. hdfs支持的存储介质: ...
随机推荐
- java操作Hbase
public class Test { public Connection connection; // 用HBaseconfiguration初始化配置信息是会自动加载当前应用的classpath下 ...
- js设置div透明度
原生js设置透明度 为了兼容IE与其他浏览器对透明度的设置,我们需要对以上两种样式分别进行设置: 复制代码代码如下: var alpha = 30; //透明度值变量 var oDiv = docum ...
- flash GC
所有应用程序都要管理内存.应用程序的内存管理包括用于确定何时分配内存,分配多少内存,何时将内容放入回收站,以及何时清空回收站的准则.MMgc是 Flash Player用于几乎所有内存分配工作的通用内 ...
- 给bootstrap table设置行列单元格样式
1.根据单元格或者行内其他单元格的内容,给该单元格设置一定的css样式 columns: [{ field: 'index', title: '序号', align:"center" ...
- Fragment与Activity之间的相互通信
https://blog.csdn.net/u012702547/article/details/49786417 https://blog.csdn.net/carson_ho/article/de ...
- oracle查询所有的表明
如果是用该用户登录使用以下语句: SELECT * FROM USER_TABLES; 如果是用其他用户: SELECT * FROM ALL_TABLES WHERE OWNER='USER_NAM ...
- SpringBoot PUT请求
(1)配置HiddenHttpMethodFilter(SpringMVC需要配置,SpringBoot已经为我们自动配置了) (2)在视图页面创建一个Post Form表单,在表单中创建一个inpu ...
- Majority Element(169) && Majority Element II(229)
寻找多数元素这一问题主要运用了:Majority Vote Alogrithm(最大投票算法)1.Majority Element 1)description Given an array of si ...
- windows系统中hosts文件位置
C:\Windows\System32\drivers\etc\hosts 10.0.0.213 mr1.bic.zte.com 10.0.0.2 mr2.bic.zte.com 10.0.0.102 ...
- Epoll模型
Epoll模型 相比于select,epoll最大的好处在于它不会随着监听fd数目的增长而降低效率.因为在内核中的select实现中,它是采用轮询来处理的,轮询的fd数目越多,自然耗时越多.并且,在l ...