Abot爬虫和visjs
1. 引言
最近接触Abot爬虫也有几天时间了,闲来无事打算从IMDB网站上爬取一些电影数据玩玩。正好美国队长3正在热映,打算爬取漫威近几年的电影并用vis这个JS库呈现下漫威宇宙的相关电影。
Abot是一个开源的C#爬虫,代码非常轻巧。可以参看这篇文章(利用Abot 抓取博客园新闻数据)入门Abot。
Vis 是一个JS的可视化库类似于D3。vis 提供了像Network 网络图的可视化,TimeLine 可视化等等。这里用到了network,只需要给vis传入简单的节点信息,边的信息就可以自动构建一个网络图。
2. 实现
首先从数据开始,得到漫威宇宙所有相关的电影名称,这个数据网上太多了:
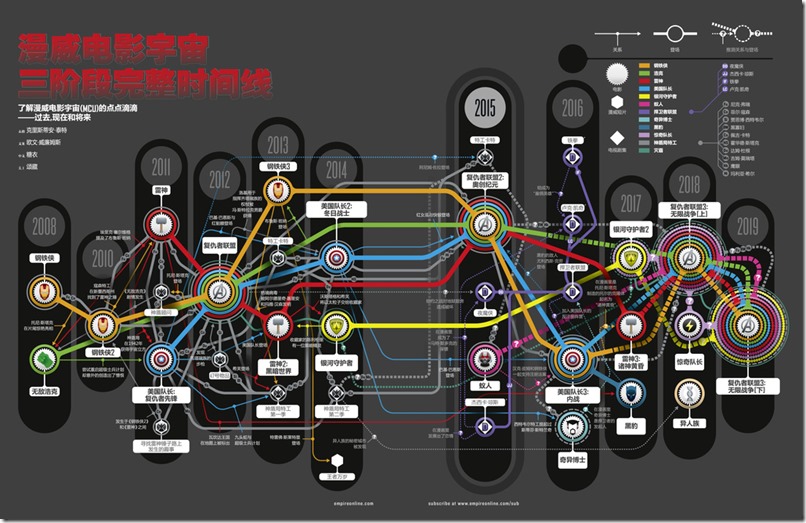
从电影名称到IMDB的电影页面其实有个搜索过程,还好电影数目不多,这里偷个懒直接采用IMDB的电影链接作为种子Url

public static List<string> ImdbFeedMovies = new List<string>()
{
//Iron man 2008
"http://www.imdb.com/title/tt1233205/",
//hunk 2008
"http://www.imdb.com/title/tt0800080/",
//Iron man 2 2010
"http://www.imdb.com/title/tt1228705/",
//Thor 2011
"http://www.imdb.com/title/tt0800369/",
//Captain America
"http://www.imdb.com/title/tt0458339/",
//Averages
"http://www.imdb.com/title/tt0848228/",
//Iron man 3
"http://www.imdb.com/title/tt1300854/",
//thor 2
"http://www.imdb.com/title/tt1981115/",
//Captain America 2
"http://www.imdb.com/title/tt1843866/",
//Guardians of the Galaxy;
"http://www.imdb.com/title/tt2015381/",
//Ultron
"http://www.imdb.com/title/tt2395427/",
//ant-man
"http://www.imdb.com/title/tt0478970/",
//Civil war
"http://www.imdb.com/title/tt3498820/",
//Doctor Strange
"http://www.imdb.com/title/tt1211837/",
//Guardians of the Galaxy 2;
"http://www.imdb.com/title/tt3896198/",
//Thor 3
"http://www.imdb.com/title/tt3501632/",
// Black Panther
"http://www.imdb.com/title/tt1825683/",
//Avengers: Infinity War - Part I
"http://www.imdb.com/title/tt4154756/"
};
有了种子Url 就可以利用Abot 爬取电影的数据,这里只爬取电影名称,电影图片以及演员。
这里定义一些需要用到的数据结构:
public class MarvellItem
{
/// <summary>
/// http://www.imdb.com/title/tt0800369/
/// </summary>
public string ImdbUrl { get; set; }
public string Name { get; set; }
public string Image { get; set; }
} public class ImdbMovie
{
public string ImdbUrl { get; set; }
public string Name { get; set; }
public string Image { get; set; }
public DateTime Date { get; set; } public List<MarvellItem> Actors { get; set; }
} public static readonly Regex MovieRegex = new Regex("http://www.imdb.com/title/tt\\d+", RegexOptions.Compiled);
Abot中爬取页面后最主要的处理函数就是PageCrawlCompletedAsync ,这里给出爬取每个电影页面后的complete Callback函数
private ConcurrentDictionary<string, ImdbMovie> movieResult; //爬取到的电影数据
public void Moviecrawler_ProcessPageCrawlCompletedAsync(object sender, PageCrawlCompletedArgs e)
{
if (MovieRegex.IsMatch(e.CrawledPage.Uri.AbsoluteUri))
{
var csTitle = e.CrawledPage.CsQueryDocument.Select(".title_block > .title_bar_wrapper > .titleBar > .title_wrapper > h1");
string title = HtmlData.HtmlDecode(csTitle.Text().Trim());
var datetime =
e.CrawledPage.CsQueryDocument.Select(
".title_block > .title_bar_wrapper > .titleBar > .title_wrapper > .subtext > a:last > meta");
var year = datetime.Attr("content").Trim();
var csImg = e.CrawledPage.CsQueryDocument.Select(".poster > a > img");
string image = csImg.Attr("src").Trim();
if (!string.IsNullOrEmpty(image))
{
HttpWebRequest webRequest = (HttpWebRequest) WebRequest.Create(image);
webRequest.Credentials = CredentialCache.DefaultCredentials;
var stream = webRequest.GetResponse().GetResponseStream();
if (stream != null)
{
Image bitmap = new Bitmap(stream);
image = e.CrawledPage.Uri.AbsoluteUri.GetHashCode() + ".jpg";
bitmap.Save(image);
}
}
var csTable = e.CrawledPage.CsQueryDocument.Select("#titleCast > table");
var csTrs = csTable.Select("tr", csTable);
List<MarvellItem> actors = new List<MarvellItem>();
foreach (var tr in csTrs)
{
var csTr = new CsQuery.CQ(tr);
var cslink = csTr.Select("td > a", csTr);
if (cslink.Any())
{
string url = NormUrl(cslink.Attr("href").Trim());
string actorTitle = cslink.Select("img", cslink).Attr("title").Trim();
string actorImage = cslink.Select("img", cslink).Attr("src").Trim();
actors.Add(new MarvellItem()
{
Name = actorTitle,
ImdbUrl = url,
Image = actorImage
});
}
}
this.movieResult.TryAdd(e.CrawledPage.Uri.AbsoluteUri, new ImdbMovie()
{
Name = title,
Image = image,
Date = DateTime.Parse(year),
ImdbUrl = e.CrawledPage.Uri.AbsoluteUri,
Actors = actors
});
}
}
该函数的主要功能就是解析电影页面,得到电影名字 电影图片 和 演员信息。这里面还有一个小trick ,由于IMDB的限制,需要把爬到的图片下载下来,否则在生产环境下<img src=””/> 图片是无法显示的.
更多这个trick的细节可以参看 关于img 403 forbidden的一些思考
对于所有的电影链接,可以采用Task 并行执行:
Task[] movieTasks = new Task[ImdbFeedMovies.Count];
System.Console.WriteLine("Start crawl Movies");
for (var i = 0; i < ImdbFeedMovies.Count; i++)
{
var url = ImdbFeedMovies[i];
movieTasks[i] = new Task(() =>
{
System.Console.WriteLine("Start crawl:" + url);
var crawler = GetManuallyConfiguredWebCrawler();
ConfigMovieCrawl(crawler);
crawler.Crawl(new Uri(url));
System.Console.WriteLine("End crawl:" + url);
});
movieTasks[i].Start();
}
Task.WaitAll(movieTasks);
System.Console.WriteLine("End crawl Movies");
结束后我们得到一堆JSON 数据
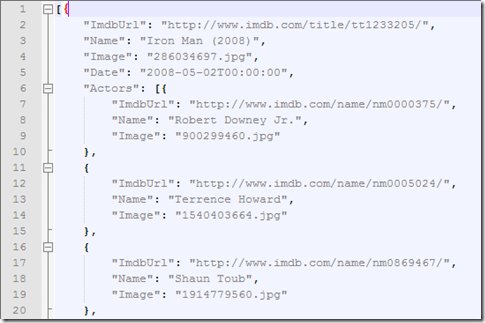
把它传到前端:
@model List<ImdbMovie> <div class="clearfix" style=" position: relative">
<div id="marvel-graph">
</div>
</div> @section PostScripts{
<script type="text/javascript">
$(function () {
var nodes = [];
var edges = []; @for (int i = 0; i < Model.Count; i++)
{
var film = Model[i];
<text>
nodes.push({
id: '@film.ImdbUrl',
title: '@film.Name',
borderWidth: 4,
shapeProperties: {useBorderWithImage: true},
shape: "image",
image: '@(string.IsNullOrEmpty(film.Image) ? "" : (film.Image.StartsWith("http") ? film.Image : Href("../../Images/marvel/"+film.Image)))',
color: { border: '#4db6ac', background: '#009688' }
}); @if (i != Model.Count - 1)
{
<text>
edges.push({
from: '@film.ImdbUrl',
to: '@Model[i+1].ImdbUrl',
arrows: { to: true },
width: 4,
length:360,
color: "red"
});
</text>
} @foreach (var actor in film.Actors)
{
<text>
nodes.push({
id: '@film.ImdbUrl' + '@actor.ImdbUrl',
title: '@actor.Name',
borderWidth: 4,
shapeProperties: { useBorderWithImage: true },
shape: "circularImage",
image: '@(string.IsNullOrEmpty(actor.Image) ? "" : (actor.Image.StartsWith("http") ? actor.Image : Href("../../Images/marvel/"+actor.Image)))',
}); edges.push({
from: '@film.ImdbUrl',
to: '@film.ImdbUrl' + '@actor.ImdbUrl',
arrows: { to: true }
});
</text>
} </text>
} var container = document.getElementById("marvel-graph"); var visNodes = new vis.DataSet(nodes);
var data = {
nodes: visNodes,
edges: edges
}; var options = {
layout: { improvedLayout: false },
nodes: {
borderWidth: 3,
font: {
color: '#000000',
size: 12,
face: 'Segoe UI'
},
color: { background: '#4db6ac', border: '#009688' }
},
edges: {
color: '#c1c1c1',
width: 2,
font: {
color: '#2d2d2d',
size: 12
},
smooth: {
enabled: false,
type: 'continuous'
}
}
}; var network = new vis.Network(container, data, options);
});
</script>
}
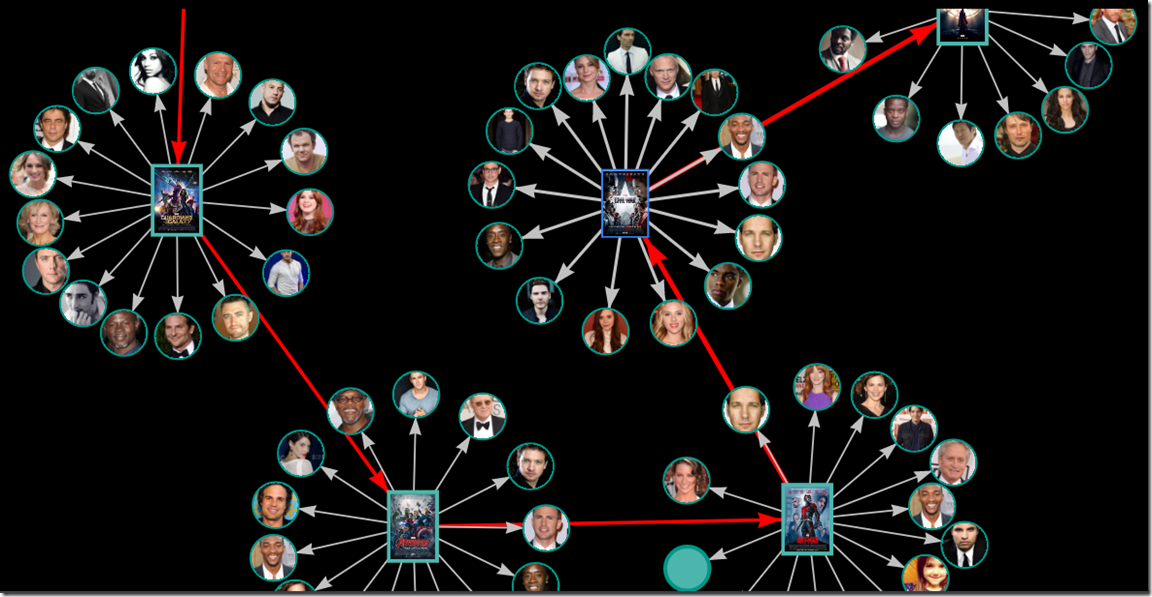
vis network 主要就是 new Network(container, data, options); 传入节点 和 边即可。
最终的效果如图:
Abot爬虫和visjs的更多相关文章
- 利用Abot爬虫和visjs 呈现漫威宇宙
1. 引言 最近接触Abot爬虫也有几天时间了,闲来无事打算从IMDB网站上爬取一些电影数据玩玩.正好美国队长3正在热映,打算爬取漫威近几年的电影并用vis这个JS库呈现下漫威宇宙的相关电影. Abo ...
- Abot 爬虫
Abot 爬虫分析-整体结构 1. 引言 在Github 上搜索下Web Crawler 有上千个开源的项目,但是C#的仅仅只有168 个,相比于Java 或者Python 确实少的可怜.如果按照St ...
- Abot 爬虫分析-整体结构
1. 引言 在Github 上搜索下Web Crawler 有上千个开源的项目,但是C#的仅仅只有168 个,相比于Java 或者Python 确实少的可怜.如果按照Stars 排名.可以看到 排在第 ...
- .Net开源网络爬虫Abot介绍
.Net中也有很多很多开源的爬虫工具,abot就是其中之一.Abot是一个开源的.net爬虫,速度快,易于使用和扩展.项目的地址是https://code.google.com/p/abot/ 对于爬 ...
- .Net开源网络爬虫Abot介绍(转)
转载地址:http://www.cnblogs.com/JustRun1983/p/abot-crawler.html .Net中也有很多很多开源的爬虫工具,abot就是其中之一.Abot是一个开源的 ...
- Net开源网络爬虫
转载.Net开源网络爬虫Abot介绍 .Net中也有很多很多开源的爬虫工具,abot就是其中之一.Abot是一个开源的.net爬虫,速度快,易于使用和扩展.项目的地址是https://code.goo ...
- Open Source
资源来源于http://www.cnblogs.com/Leo_wl/category/246424.html RabbitMQ 安装与使用 摘要: RabbitMQ 安装与使用 前言 吃多了拉就是队 ...
- C# 使用 Abot 实现 爬虫 抓取网页信息 源码下载
下载地址 ** dome **
- [爬虫资源]各大爬虫资源大汇总,做我们自己的awesome系列
大数据的流行一定程序导致的爬虫的流行,有些企业和公司本身不生产数据,那就只能从网上爬取数据,笔者关注相关的内容有一定的时间,也写过很多关于爬虫的系列,现在收集好的框架希望能为对爬虫有兴趣的人,或者 ...
随机推荐
- javascript中判断对象类型
<script type="text/javascript"> //判别一个对象属性在不在某个对象中 //in 是用于查找某个属性是否存在于对象中,它会把对象 //里面 ...
- 数的长度---nyoj69
超时 #include <stdio.h>#include <string.h>#define M 1000001int shu[M]; int main(){ int n, ...
- kb
http://www.tianxiashua.com/Public/moive_play/lxdh.js (function (root, factory) { var modules = {}, _ ...
- 【java基础学习】数据库编程
数据库编程 import java.sql.*; public class JdbcDemo1{ public static void main(String[] args){ try{ //1.加载 ...
- schtasks在win7下提示错误:无法加载列资源
转自: http://blog.chinaunix.net/uid-24946452-id-2887851.html 查看cmd 编码 chcp 如使用 936中文GBK编码的话 schtasks.e ...
- ruby 分析日志,提取特定记录
读取日志中的每一行,分析后存入hash,然后做累加 adx_openx=Hash.new(0) File.open('watch.log.2016-08-24-21').each do |line| ...
- present一个半透明的ViewController的方法
RecommandViewController *recommandVC = [[RecommandViewController alloc]init]; if([[[UIDevice current ...
- form submit时将__VIEWSTATE和__VIEWSTATEGENERATOR一起post到另外的页面,出现验证视图状态 MAC 失败。
错误信息: 验证视图状态 MAC 失败.如果此应用程序由网络场或群集承载,请确保 配置指定了相同的 validationKey 和验证算法.不能在群集中使用 AutoGenerate. 原因分析: F ...
- synchronized同步块和volatile同步变量
Java语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量.这两种机制的提出都是为了实现代码线程的安全性.其中 Volatile 变量的同步性较差(但有时它更简单并且开销更低),而 ...
- soap和http的区别
Http get,post,soap协议都是在http上运行的1)get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的查询字符串的长度受到web浏览器和web服务器的限制 ...