利用Abot爬虫和visjs 呈现漫威宇宙
1. 引言
最近接触Abot爬虫也有几天时间了,闲来无事打算从IMDB网站上爬取一些电影数据玩玩。正好美国队长3正在热映,打算爬取漫威近几年的电影并用vis这个JS库呈现下漫威宇宙的相关电影。
Abot是一个开源的C#爬虫,代码非常轻巧。可以参看这篇文章(利用Abot 抓取博客园新闻数据)入门Abot。
Vis 是一个JS的可视化库类似于D3。vis 提供了像Network 网络图的可视化,TimeLine 可视化等等。这里用到了network,只需要给vis传入简单的节点信息,边的信息就可以自动构建一个网络图。
2. 实现
首先从数据开始,得到漫威宇宙所有相关的电影名称,这个数据网上太多了:
从电影名称到IMDB的电影页面其实有个搜索过程,还好电影数目不多,这里偷个懒直接采用IMDB的电影链接作为种子Url
public static List<string> ImdbFeedMovies = new List<string>()
{
//Iron man 2008
"http://www.imdb.com/title/tt1233205/",
//hunk 2008
"http://www.imdb.com/title/tt0800080/",
//Iron man 2 2010
"http://www.imdb.com/title/tt1228705/",
//Thor 2011
"http://www.imdb.com/title/tt0800369/",
//Captain America
"http://www.imdb.com/title/tt0458339/",
//Averages
"http://www.imdb.com/title/tt0848228/",
//Iron man 3
"http://www.imdb.com/title/tt1300854/",
//thor 2
"http://www.imdb.com/title/tt1981115/",
//Captain America 2
"http://www.imdb.com/title/tt1843866/",
//Guardians of the Galaxy;
"http://www.imdb.com/title/tt2015381/",
//Ultron
"http://www.imdb.com/title/tt2395427/",
//ant-man
"http://www.imdb.com/title/tt0478970/",
//Civil war
"http://www.imdb.com/title/tt3498820/",
//Doctor Strange
"http://www.imdb.com/title/tt1211837/",
//Guardians of the Galaxy 2;
"http://www.imdb.com/title/tt3896198/",
//Thor 3
"http://www.imdb.com/title/tt3501632/",
// Black Panther
"http://www.imdb.com/title/tt1825683/",
//Avengers: Infinity War - Part I
"http://www.imdb.com/title/tt4154756/"
};
有了种子Url 就可以利用Abot 爬取电影的数据,这里只爬取电影名称,电影图片以及演员。
这里定义一些需要用到的数据结构:
public class MarvellItem
{
/// <summary>
/// http://www.imdb.com/title/tt0800369/
/// </summary>
public string ImdbUrl { get; set; }
public string Name { get; set; }
public string Image { get; set; }
} public class ImdbMovie
{
public string ImdbUrl { get; set; }
public string Name { get; set; }
public string Image { get; set; }
public DateTime Date { get; set; } public List<MarvellItem> Actors { get; set; }
} public static readonly Regex MovieRegex = new Regex("http://www.imdb.com/title/tt\\d+", RegexOptions.Compiled);
Abot中爬取页面后最主要的处理函数就是PageCrawlCompletedAsync ,这里给出爬取每个电影页面后的complete Callback函数
private ConcurrentDictionary<string, ImdbMovie> movieResult; //爬取到的电影数据
public void Moviecrawler_ProcessPageCrawlCompletedAsync(object sender, PageCrawlCompletedArgs e)
{
if (MovieRegex.IsMatch(e.CrawledPage.Uri.AbsoluteUri))
{
var csTitle = e.CrawledPage.CsQueryDocument.Select(".title_block > .title_bar_wrapper > .titleBar > .title_wrapper > h1");
string title = HtmlData.HtmlDecode(csTitle.Text().Trim());
var datetime =
e.CrawledPage.CsQueryDocument.Select(
".title_block > .title_bar_wrapper > .titleBar > .title_wrapper > .subtext > a:last > meta");
var year = datetime.Attr("content").Trim();
var csImg = e.CrawledPage.CsQueryDocument.Select(".poster > a > img");
string image = csImg.Attr("src").Trim();
if (!string.IsNullOrEmpty(image))
{
HttpWebRequest webRequest = (HttpWebRequest) WebRequest.Create(image);
webRequest.Credentials = CredentialCache.DefaultCredentials;
var stream = webRequest.GetResponse().GetResponseStream();
if (stream != null)
{
Image bitmap = new Bitmap(stream);
image = e.CrawledPage.Uri.AbsoluteUri.GetHashCode() + ".jpg";
bitmap.Save(image);
}
}
var csTable = e.CrawledPage.CsQueryDocument.Select("#titleCast > table");
var csTrs = csTable.Select("tr", csTable);
List<MarvellItem> actors = new List<MarvellItem>();
foreach (var tr in csTrs)
{
var csTr = new CsQuery.CQ(tr);
var cslink = csTr.Select("td > a", csTr);
if (cslink.Any())
{
string url = NormUrl(cslink.Attr("href").Trim());
string actorTitle = cslink.Select("img", cslink).Attr("title").Trim();
string actorImage = cslink.Select("img", cslink).Attr("src").Trim();
actors.Add(new MarvellItem()
{
Name = actorTitle,
ImdbUrl = url,
Image = actorImage
});
}
}
this.movieResult.TryAdd(e.CrawledPage.Uri.AbsoluteUri, new ImdbMovie()
{
Name = title,
Image = image,
Date = DateTime.Parse(year),
ImdbUrl = e.CrawledPage.Uri.AbsoluteUri,
Actors = actors
});
}
}
该函数的主要功能就是解析电影页面,得到电影名字 电影图片 和 演员信息。这里面还有一个小trick ,由于IMDB的限制,需要把爬到的图片下载下来,否则在生产环境下<img src=””/> 图片是无法显示的.
更多这个trick的细节可以参看 关于img 403 forbidden的一些思考
对于所有的电影链接,可以采用Task 并行执行:
Task[] movieTasks = new Task[ImdbFeedMovies.Count];
System.Console.WriteLine("Start crawl Movies");
for (var i = 0; i < ImdbFeedMovies.Count; i++)
{
var url = ImdbFeedMovies[i];
movieTasks[i] = new Task(() =>
{
System.Console.WriteLine("Start crawl:" + url);
var crawler = GetManuallyConfiguredWebCrawler();
ConfigMovieCrawl(crawler);
crawler.Crawl(new Uri(url));
System.Console.WriteLine("End crawl:" + url);
});
movieTasks[i].Start();
}
Task.WaitAll(movieTasks);
System.Console.WriteLine("End crawl Movies");
结束后我们得到一堆JSON 数据
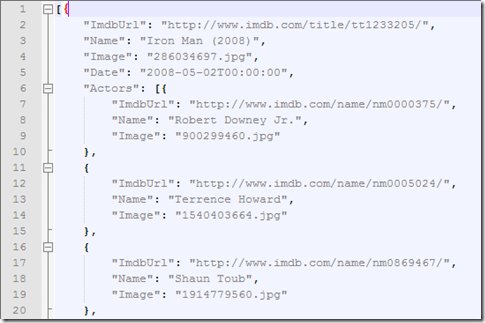
把它传到前端:
@model List<ImdbMovie> <div class="clearfix" style="background-color: black; position: relative">
<div id="marvel-graph">
</div>
</div> @section PostScripts{
<script type="text/javascript">
$(function () {
var nodes = [];
var edges = []; @for (int i = 0; i < Model.Count; i++)
{
var film = Model[i];
<text>
nodes.push({
id: '@film.ImdbUrl',
title: '@film.Name',
borderWidth: 4,
shapeProperties: {useBorderWithImage: true},
shape: "image",
image: '@(string.IsNullOrEmpty(film.Image) ? "" : (film.Image.StartsWith("http") ? film.Image : Href("../../Images/marvel/"+film.Image)))',
color: { border: '#4db6ac', background: '#009688' }
}); @if (i != Model.Count - 1)
{
<text>
edges.push({
from: '@film.ImdbUrl',
to: '@Model[i+1].ImdbUrl',
arrows: { to: true },
width: 4,
length:360,
color: "red"
});
</text>
} @foreach (var actor in film.Actors)
{
<text>
nodes.push({
id: '@film.ImdbUrl' + '@actor.ImdbUrl',
title: '@actor.Name',
borderWidth: 4,
shapeProperties: { useBorderWithImage: true },
shape: "circularImage",
image: '@(string.IsNullOrEmpty(actor.Image) ? "" : (actor.Image.StartsWith("http") ? actor.Image : Href("../../Images/marvel/"+actor.Image)))',
}); edges.push({
from: '@film.ImdbUrl',
to: '@film.ImdbUrl' + '@actor.ImdbUrl',
arrows: { to: true }
});
</text>
} </text>
} var container = document.getElementById("marvel-graph"); var visNodes = new vis.DataSet(nodes);
var data = {
nodes: visNodes,
edges: edges
}; var options = {
layout: { improvedLayout: false },
nodes: {
borderWidth: 3,
font: {
color: '#000000',
size: 12,
face: 'Segoe UI'
},
color: { background: '#4db6ac', border: '#009688' }
},
edges: {
color: '#c1c1c1',
width: 2,
font: {
color: '#2d2d2d',
size: 12
},
smooth: {
enabled: false,
type: 'continuous'
}
}
}; var network = new vis.Network(container, data, options);
});
</script>
}
vis network 主要就是 new Network(container, data, options); 传入节点 和 边即可。
最终的效果如图:
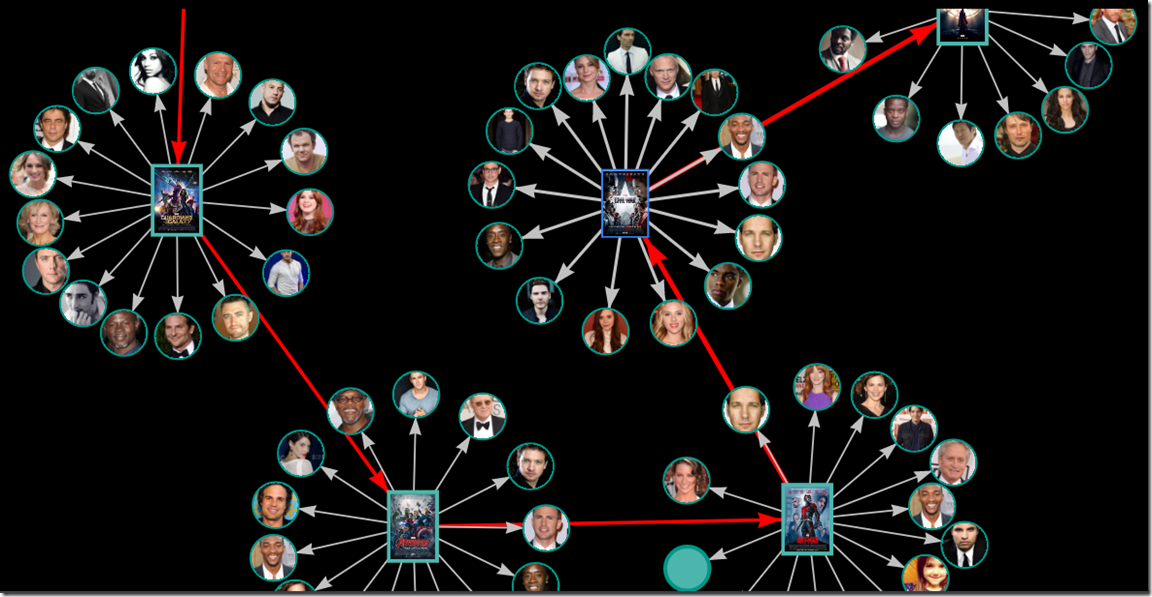
欢迎访问我的个人主页 51zhang.net 网站还在不断开发中…..
利用Abot爬虫和visjs 呈现漫威宇宙的更多相关文章
- Abot爬虫和visjs
1. 引言 最近接触Abot爬虫也有几天时间了,闲来无事打算从IMDB网站上爬取一些电影数据玩玩.正好美国队长3正在热映,打算爬取漫威近几年的电影并用vis这个JS库呈现下漫威宇宙的相关电影. Abo ...
- Abot 爬虫
Abot 爬虫分析-整体结构 1. 引言 在Github 上搜索下Web Crawler 有上千个开源的项目,但是C#的仅仅只有168 个,相比于Java 或者Python 确实少的可怜.如果按照St ...
- 利用简易爬虫完成一道基础CTF题
利用简易爬虫完成一道基础CTF题 声明:本文主要写给新手,侧重于表现使用爬虫爬取页面并提交数据的大致过程,所以没有对一些东西解释的很详细,比如表单,post,get方法,感兴趣的可以私信或评论给我.如 ...
- 企业级Python开发大佬利用网络爬虫技术实现自动发送天气预告邮件
前天小编带大家利用Python网络爬虫采集了天气网的实时信息,今天小编带大家更进一步,将采集到的天气信息直接发送到邮箱,带大家一起嗨~~拓展来说,这个功能放在企业级角度来看,只要我们拥有客户的邮箱,之 ...
- Abot 爬虫分析-整体结构
1. 引言 在Github 上搜索下Web Crawler 有上千个开源的项目,但是C#的仅仅只有168 个,相比于Java 或者Python 确实少的可怜.如果按照Stars 排名.可以看到 排在第 ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- 如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7 思路: 1.先选取你要爬取的电影 2.用vip解析工具解析,获取地址 3.写好脚本,下载片断 4.将片断利用电脑合成 需要的python模块: ##第一 ...
- 利用python3 爬虫 定制版妹子图mzitu爬取
在刚开始学爬虫的时候,用来练手的基础爬虫就是爬取各种妹子图片,前几天同时说了这个,便准备随便写一个...最后发现真是三天不练..什么都记不住了!!所以花了政治一天重新写了一个爬虫程序,并且支持按照时间 ...
- 如何利用 Python 爬虫实现给微信群发新闻早报?(详细)
1. 场景 经常有小伙伴在交流群问我,每天的早报新闻是怎么获取的? 其实,早期使用的方案,是利用爬虫获取到一些新闻网站的标题,然后做了一些简单的数据清洗,最后利用 itchat 发送到指定的社群中. ...
随机推荐
- openseadragon.js与deep zoom java实现艺术品图片展示
openseadragon.js 是一款用来做图像缩放的插件,它可以用来做图片展示,做展示的插件很多,也很优秀,但大多数都解决不了图片尺寸过大的问题. 艺术品图像展示就是最简单的例子,展示此类图片一般 ...
- Dynamics CRM 2013 installation
原创地址:http://www.cnblogs.com/jfzhu/p/3445820.html 转载请注明出处 一 硬件要求 1. CRM Server 下表对硬件的要求是假定Microsoft S ...
- Enterprise Architect的共享Respository设置,postgresql数据库
Enterprise Architect有一个很实用的共享,在设计UML图的时候,可以连接到一个数据库服务器,将所有的画图数据共享在上面,所有连到这个server的人,都可以看到 别人的图,图中的元素 ...
- Http基础
Http基础 这篇文章是讲Android网络请求的先导文章,主要讲Http工作流程,请求报文和响应报文的格式,以及GET和POST方法的具体含义. Http工作流程 HTTP是一个客户端和服务器端请求 ...
- cxf restful
Restful 服务端 1 创建好pojo.dao.service, dao进行数据库操作,service提供服务 @Path("/roomservice") @Produces( ...
- 每天一个linux命令(54):ping命令
Linux系统的ping命令是常用的网络命令,它通常用来测试与目标主机的连通性,我们经常会说“ping一下某机器,看是不是开着”.不能打开网页时会说“你先ping网关地址192.168.1.1试试”. ...
- Redis笔记,安装和常用命令
转载于:http://www.itxuexiwang.com/a/shujukujishu/redis/2016/0216/96.html?1455870708 一.redis简单介绍 redis是N ...
- java基础 数组14
已知2个一维数组:a[]={3,4,5,6,7},b[]={1,2,3,4,5,6,7}:把数组a与数组b 对应的元素乘积再赋值给数组b,如:b[2]=a[2]*b[2]:最后输出数组b的元素.
- Fiddler (六) 最常用的快捷键
使用QuickExec Fiddler2成了网页调试必备的工具,抓包看数据.Fiddler2自带命令行控制,并提供以下用法. Fiddler的快捷命令框让你快速的输入脚本命令. 键盘快捷键 按ALT+ ...
- Atititi tesseract使用总结
Atititi tesseract使用总结 消除bug,优化,重新发布.当前版本为3.02 项目下载地址为:http://code.google.com/p/tesseract-ocr. Window ...