《R语言实战》读书笔记-- 第六章 基本图形
首先写第二部分的前言。
第二部分用来介绍获取数据基本信息的图形技术和统计方法。
本章主要内容
条形图、箱型图、点图
饼图和扇形图
直方图和核密度图
分析数据第一步就是要观察它,用可视化的方式是最好的。本章的主题有两个
1、将变量的分布作可视化展示
2、通过结果变量进行跨组比较
下面从不同的图形开始探索数据。
6.1条形图
6.1.1简单地条形图
条形图是通过条形展示离散变量的频数分布。函数是barplot:
barplot(height) height是主要参数,horiz = TRUE就是横向条形图。
height可以是数值向量或者矩阵。向量的话就是向量每个元素的分布,矩阵的话是按照列一个一个往上加,就是堆叠。
如果要绘制的变量是因子或者有序因子,可以使用plot函数,直接画出条形统计图,形式为plot(因子),书上的例子plot(Arthritis$Improved)。
6.1.2堆砌条形图和分组条形图
barplot后面加矩阵时,如果beside = FALSE 得到一个堆砌条形图,若为TRUE,则为分组条形图。下面是示例:
opar <- par(no.readonly = TRUE)
par(mfrow = c(,))
library(vcd)
counts <- table(Arthritis$Improved,Arthritis$Treatment) barplot(counts,
main = "Stacked Bar Plot",
xlab = "Treatment",ylab = "Frequency",
col = c("red","yellow","green"),
legend = rownames(counts)) barplot(counts,
main = "Grouped Bar Plot",
xlab = "Treatment",ylab = "Frequency",
col = c("red","yellow","green"),
legend = rownames(counts),
beside = TRUE)
par(opar)
下面是结果:
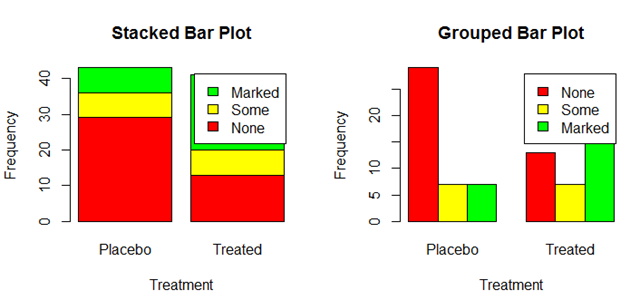
注意上面的代码中,添加图例的命令只有在对矩阵作用时才能用。
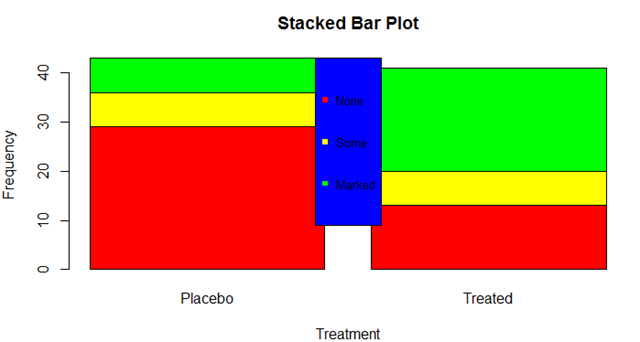
自然可以对图例进行一下设置(乱弄的,熟悉一下命令):
barplot(counts,
main = "Stacked Bar Plot",
xlab = "Treatment",ylab = "Frequency",
col = c("red","yellow","green")
) legend("top",legend = rownames(counts),
col = c("red","yellow","green"),cex = 0.8,
pch = rep(,),bg = "blue")
6.1.3均值条形图
条形图不一定全都进行数据频数的展示,还可以将均值、中位数方差等传递给barplot函数。
states <- data.frame(state.region,state.x77)
means <- aggregate(states$Illiteracy,by = list(state.region),
FUN =mean)
means <- means[order(means$x),]
barplot(means$x,names.arg = means$Group.)
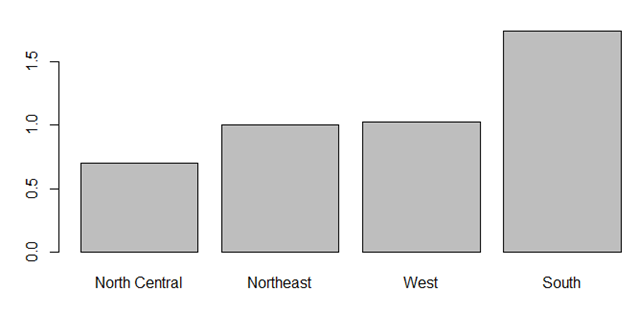
其实本质是一样的。lines(means$x)可以在上面图中顶端加一条折线,gplots包中barplot2函数可以作更复杂的图。
6.1.4条形图的微调
6.1.5棘状图
棘状图对堆砌条形图进行重缩放,每个条形的高度均为1,不同的频数对应着比例。vcd包中的spine函数可以做棘状图。
library(vcd)
counts <- table(Arthritis$Treatment,Arthritis$Improved)
spine(counts,main = "Spinogram Example")
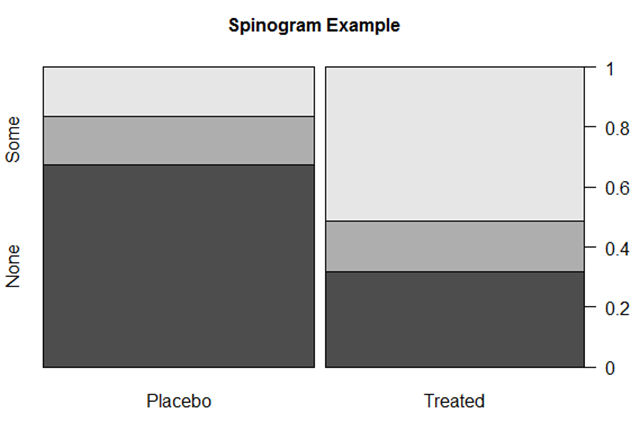
6.2饼图
书上上来就说饼图不是很常用,R中关于饼图的选型不多.
pie函数:
pie(x, labels = names(x), edges = , radius = 0.8,
clockwise = FALSE, init.angle = if(clockwise) else ,
density = NULL, angle = , col = NULL, border = NULL,
lty = NULL, main = NULL, ...)
#主要参数当然是x和labels,其中x是非负数值型变量,表示面积,labels是名称.
下面是一个例子:
par(mfrow = c(,))
slices <- c(,,,,)
lbls <- c("US","UK","Australia","Germany","France")
pie(slices,labels = lbls,
main = "Simple Pie Chart") pct <- round(slices/sum(slices)*)
lbls2 <- paste(lbls," ",pct,"%",sep="")
pie(slices,labels = lbls2,
col = rainbow(length(lbls2)),
main = "Pie Chart with Percentages") library(plotrix)
pie3D(slices,labels=lbls2,explode = 0.1,
mian = "3D Pie Chart") mytable <- table(state.region)
lbls3 <- paste(names(mytable),"\n",mytable,sep="")
pie(mytable,labels = lbls3,
main = "Pie Chart from a Table\n(with sample sizes)")
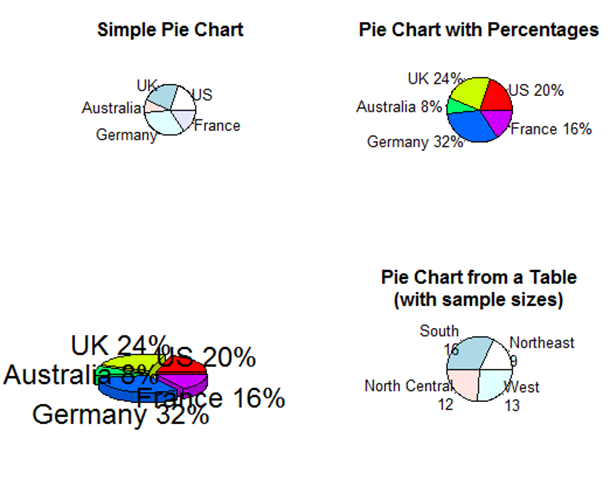
注意上面的例子中,plotrix中的pie3D函数,可以画立体饼图.
饼图不太容易看出相对的比例大小,为改善这种情况,有 fan.plot 扇形图来展现大小关系.在plotrix包中,fan.plot函数可以实现.
fan.plot(slices,labels = lbls,main = "Fan Plot")
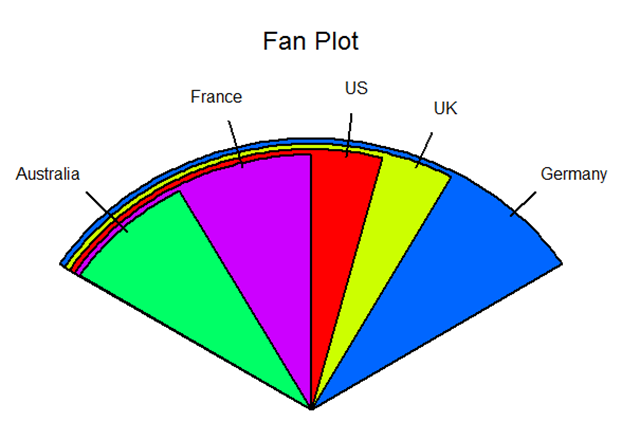
上面的例子中,扇形张开角的大小就是相对比例关系,而半径大小无所谓.
6.3直方图
直方图通过将值域分为几组,Y值显示频数。用hist函数生成:
hist(x, breaks = "Sturges",
freq = NULL, probability = !freq,
include.lowest = TRUE, right = TRUE,
density = NULL, angle = , col = NULL, border = NULL,
main = paste("Histogram of" , xname),
xlim = range(breaks), ylim = NULL,
xlab = xname, ylab,
axes = TRUE, plot = TRUE, labels = FALSE,
nclass = NULL, warn.unused = TRUE, ...)
#这里的x是一个数值向量,矩阵也可以;breaks是设置组数;
#freq是一个逻辑值,表示是否归一化数据 其他参数用到再说
下面是一个例子:
par(mfrow=c(,)) hist(mtcars$mpg)
hist(mtcars$mpg,
breaks = ,
col = "red",
xlab = "Miles Per Gallon",
main = "Colored histgram with 12 bins")
hist(mtcars$mpg,
freq = FALSE, #FALSE是将数据归一化
breaks = ,
col = "red",
xlab = "Miles Per Gallon",
main = "Histogram,rug plot,density")
rug(jitter(mtcars$mpg))
lines(density(mtcars$mpg),col = "blue",lwd = )
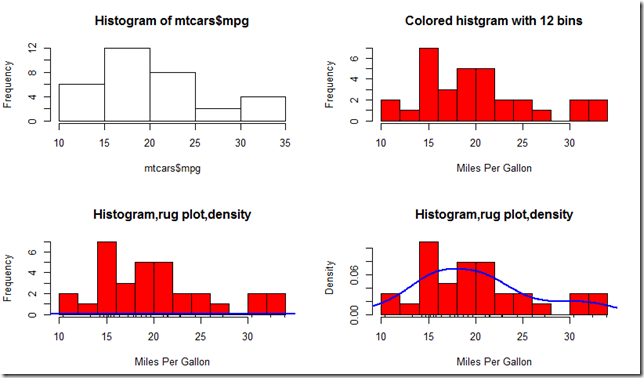
需要写几个函数:
lines(x, y = NULL, type = "l", ...)
#向图形中添加曲线,lines(x,cos(x)),不会另起一幅图形界面
rug函数:添加“地毯”
rug(x, ticksize = 0.03, side = 1, lwd = 0.5, col = par("fg"),
quiet = getOption("warn") < 0, ...)
#应该就是第三幅图中横轴下面的短线。通常和jitter连用,这是为了避免线的重叠。
jitter函数:为数值向量添加一个扰动
jitter(x, factor = 1, amount = NULL)
#x是数值向量,factor是一个数值,与amount一起决定波动范围,amount是波动的范围设置。其实,这个函数相当于
r <- x + runif(n, -a, a)。
density函数:
density(x, bw = "nrd0", adjust = 1,
kernel = c("gaussian", "epanechnikov", "rectangular",
"triangular", "biweight",
"cosine", "optcosine"),
weights = NULL, window = kernel, width,
give.Rkern = FALSE,
n = 512, from, to, cut = 3, na.rm = FALSE, ...)
是一个核密度函数,通常与画图函数一起用.下面写写核密度估计.
核密度估计是非参数估计的一种,是用来估计一组数的规律用的,所谓非参数,就是不假定数据服从某种分布,而只是利用已知的数据进行分布估计。比如用一个点附近的几个点的均值作为此处的值。有一些核函数可以确定估计方式。最重要的是带宽的选取,有一个公式可以用来评价规律的好坏。
上面的函数中,x是数据,bw是带宽,adjust是与带宽相关的值,共同决定带宽。
还要看一下box函数:
为已经画出的图形周边添加一个盒子,可以设置线型、颜色等。
6.4核密度图
用plot(density(x))来画核密度图。例子:
par(mfrow = c(,))
d <- density(mtcars$mpg)
plot(d) d <- density(mtcars$mpg)
plot(d,main = "Kernel Density of Miles Per Gallon")
polygon(d,col = "red",border = "blue")
rug(mtcars$mpg,col = "brown") #注意这里有个函数:polygon 这是一个画多边形的函数
polygon(x, y = NULL, density = NULL, angle = 45,
border = NULL, col = NA, lty = par("lty"),
..., fillOddEven = FALSE)
#其中x、y是包含多边形顶点的向量,density是密度的设置,其他比较平凡。
d <- density(mtcars$mpg)
plot(d,main = "Kernel Density of Miles Per Gallon")
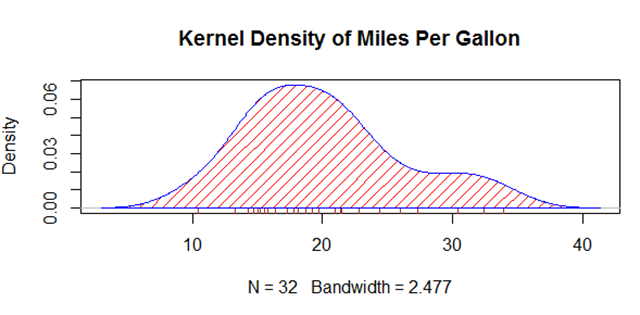
polygon(d,density = 10,col = "red",border = "blue") #注意这里加上了线的密度,图形见下面斜线图。
rug(mtcars$mpg,col = "brown")
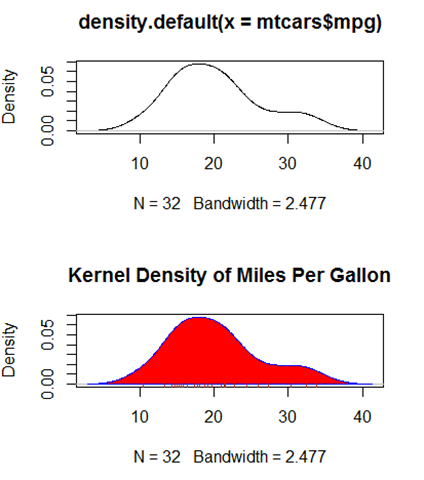
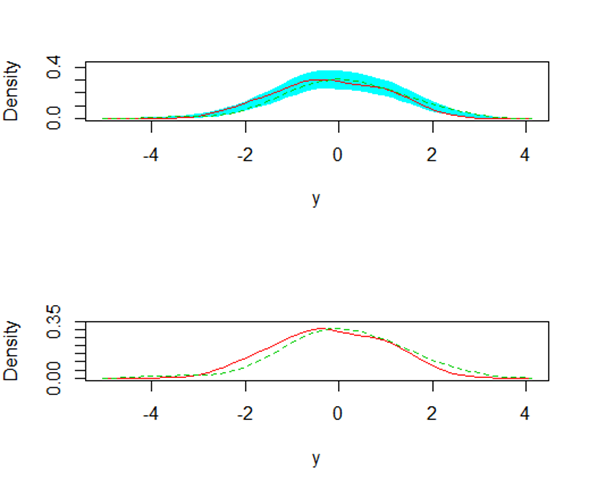
下面注意了,书上说和密度图可以比较组间差距,确实是这样,来看一下,感觉这个挺有用。利用sm包中的sm.density.compare函数进行操作。
sm.density.compare(x, group, h, model = "none", ...)
#x是一个数值向量,group是分组因子向量,关于model,下面两个图是一个对比:
y <- rnorm(100)
g <- rep(1:2, rep(50,2))
sm.density.compare(y, g, model
="equal") #一个跟bootstrap相等假设检验相关的量,还会显示一个适当带子
sm.density.compare(y, g, model="none") #画简单图
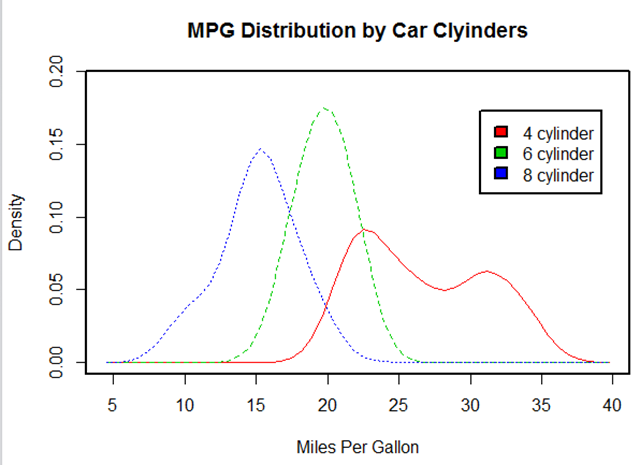
par(lwd = )
library(sm) cyl.f <- factor(mtcars$cyl,levels = c(,,),
labels = c("4 cylinder","6 cylinder","8 cylinder")) sm.density.compare(mtcars$mpg,mtcars$cyl,xlab = "Miles Per Gallon")
title(main = "MPG Distribution by Car Clyinders")
colfill <- c(:(+length(levels(cyl.f)))) #注意这里有一个levels函数,提取因子中的levels
legend(locator(),levels(cyl.f),fill=colfill) #这里的locator函数是用鼠标点击确定位置
箱线图是一项可视化分布和组间差异的手段,并且很常用。
6.5箱线图
箱线图绘制连续型变量的五个数 最小数、.25四分位数、中位数、.75分位数、最大值。还可以显示离群点 正负1.5*IQR 以外的值,其中IQR是四分位距(上下四分之一分位数之差)。boxplot函数:
boxplot(x, ..., range = 1.5, width = NULL, varwidth = FALSE,
notch = FALSE, outline = TRUE, names, plot = TRUE,
border = par("fg"), col = NULL, log = "",
pars = list(boxwex = 0.8, staplewex = 0.5, outwex = 0.5),
horizontal = FALSE, add = FALSE, at = NULL)
#参数比价直观,用的时候差
可以使用boxplot.stats(x)可以显示箱线图的各种统计量。
6.5.1使用并列箱线图进行跨足比较
boxplot函数:
boxplot(formula, data = NULL, ..., subset, na.action = NULL)
#这里的formula是公式,而data是列表或者数据框。
#示例函数 y~A 将为类别变量A的每个值并列的生成数值型变量y的箱线图。y~A*B 将为变量A和B所有水平的两两组合生成数值型变量y的箱线图。
#参数 varwidth = TRUE 是使箱线图的宽度与样本使大小的平方根 成正比。
例子:
boxplot(mpg~cyl,data = mtcars,
notch = TRUE,
varwidth = TRUE,
col = "red",
main = "Car Mileage Data",
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon")
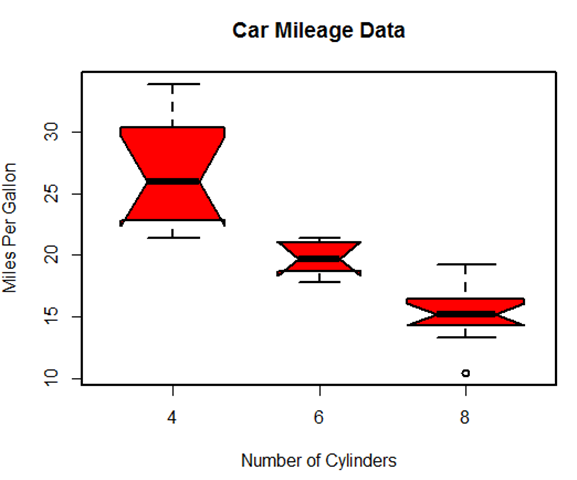
话说多图的目的在于更好地体现数据的信息,那么图形的各种属性是可以反应数据的特点的,比如 notch = TRUE在中位数的地方加一个凹槽,可以明显看出中位数的差别,而宽度varwidth = TRUE 表示宽度与样本量平方根成正比,可以看出样本量的大小关系。
下面又一个例子:
mtc <- mtcars
mtc$cyl.f <- factor(mtcars$cyl,levels = c(,,),
labels = c("","",""))
mtc$am.f <- factor(mtcars$am,levels = c(,),
labels = c("auto","standard"))
boxplot(mpg~cyl.f*am.f,data = mtc,
varwidth = TRUE,
col = c("gold","darkgreen"),
main = "Mpg Distribution by Auto Types",
xlab = "Auto Types")
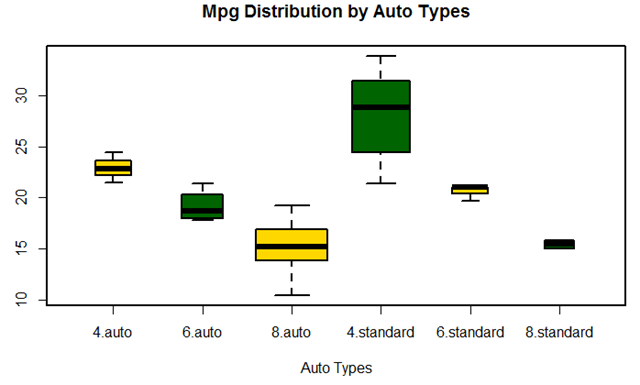
上面的图形中,可以看出cyl越小,并且为standard时,耗油最少。可以很好的反应y的影响因素。同时,由宽度大小,可以看出8.auto和4.standard数量最多。
6.5.2小提琴图
作为箱线图和核密度图的结合,小提琴图名字还是第一次听过。vioplot包中vioplot函数可以绘制此图。函数vioplot:
vioplot( x, ..., range=1.5, h, ylim, names, horizontal=FALSE,
col="magenta", border="black", lty=, lwd=, rectCol="black",
colMed="white", pchMed=, at, add=FALSE, wex=,
drawRect=TRUE)
例子:
library("vioplot")
x1 <- mtcars$mpg[mtcars$cyl == ]
x2 <- mtcars$mpg[mtcars$cyl == ]
x3 <- mtcars$mpg[mtcars$cyl == ]
vioplot(x1,x2,x3,
names = c("","",""),
col = "gold")
title("Violin Plot of Miles Per Gallon")
#值得注意的是,必须将每一个想画小提琴图的向量分别列出来,不能用数据框……
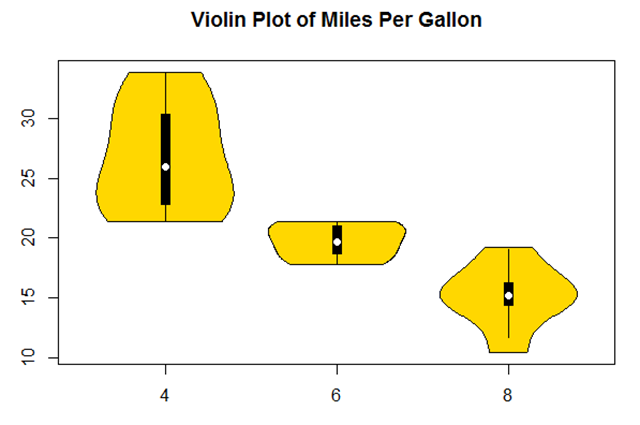
图中,中间的白点和黑线是中位数和分位数等箱线图元素,而周边曲线是核密度图。关于小提琴图,书上说,时间会证明一切。
6.6点图
dotchart函数:
dotchart(x, labels = NULL, groups = NULL, gdata = NULL,
cex = par("cex"), pch = , gpch = , bg = par("bg"),
color = par("fg"), gcolor = par("fg"), lcolor = "gray",
xlim = range(x[is.finite(x)]),
main = NULL, xlab = NULL, ylab = NULL, ...)
#这里x是一个数值向量或者矩阵,labels是每个值的标签组成的向量,groups是对向量x进行分组,
#gdata是分组数据的量,比如均值、中位数等 其他参数比较平凡
下面是例子:
dotchart(mtcars$mpg,labels = row.names(mtcars),cex = .)
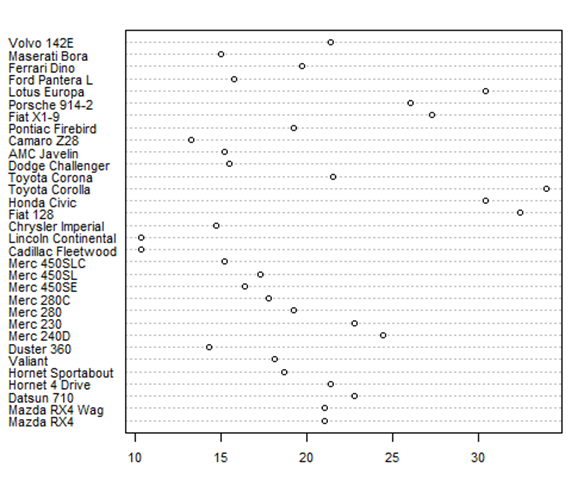
一般而言,点图经过排序,并且将分组分别涂色表示以后才更有用。
下面的例子:
mtc <- mtcars[order(mtcars$mpg),] #mtcars一种排序
mtc$cyl <- factor(mtc$cyl)
mtc$color[mtc$cyl == ] <- "red"
mtc$color[mtc$cyl == ] <- "blue"
mtc$color[mtc$cyl == ] <- "darkgreen" dotchart(mtc$mpg,
labels = row.names(mtc),
cex = .,
groups = mtc$cyl,
gcolor = "black", #这个语句是设置labels的显示颜色,就是图中的4、6、8
color = mtc$color,
pch = ,
main = "Gas Mileage for Car Models\ngrouded by cylinder",
xlab = "Miles Per Gallon")
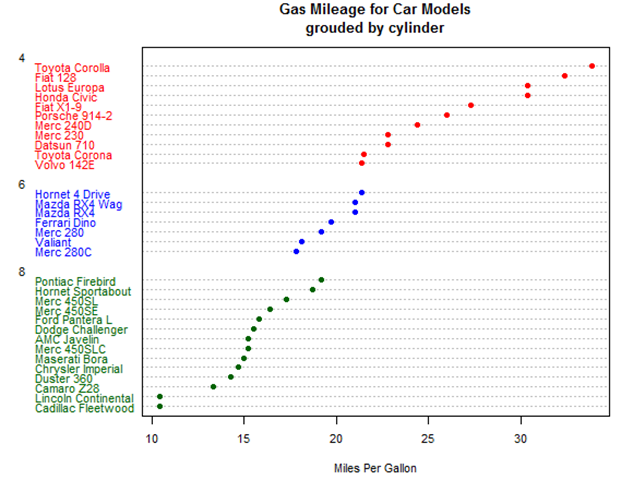
从上图中可以看出,随着缸数的增加,每加仑英里数在减少~但是也有特殊点和离群点,特殊点是最上面的两个绿点,离群点是最下面两个绿点。
注意,Himsc中有dotchart2函数,提供更丰富的点图选项。
下一章用于描述分布和二元关系的定量统计方法和一类推断方法,需要看一遍统计了。
《R语言实战》读书笔记-- 第六章 基本图形的更多相关文章
- R语言实战读书笔记(二)创建数据集
2.2.2 矩阵 matrix(vector,nrow,ncol,byrow,dimnames,char_vector_rownames,char_vector_colnames) 其中: byrow ...
- R语言实战读书笔记(三)图形初阶
这篇简直是白写了,写到后面发现ggplot明显更好用 3.1 使用图形 attach(mtcars)plot(wt, mpg) #x轴wt,y轴pgabline(lm(mpg ~ wt)) #画线拟合 ...
- R语言实战读书笔记(六)基本图形
#安装vcd包,数据集在vcd包中 library(vcd) counts <- table(Arthritis$Improved)counts # 垂直barplot(counts, main ...
- R语言实战读书笔记1—语言介绍
第一章 语言介绍 1.1 典型的数据分析步骤 1.2 获取帮助 help.start() help("which") help.search("which") ...
- R语言实战读书笔记2—创建数据集(上)
第二章 创建数据集 2.1 数据集的概念 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和变量(variable) ,数据库分析师则称其为记录(record)和字 ...
- R语言实战读书笔记(八)回归
简单线性:用一个量化验的解释变量预测一个量化的响应变量 多项式:用一个量化的解决变量预测一个量化的响应变量,模型的关系是n阶多项式 多元线性:用两个或多个量化的解释变量预测一个量化的响应变量 多变量: ...
- R语言实战读书笔记(五)高级数据管理
5.2.1 数据函数 abs: sqrt: ceiling:求不小于x的最小整数 floor:求不大于x的最大整数 trunc:向0的方向截取x中的整数部分 round:将x舍入为指定位的小数 sig ...
- R语言实战读书笔记(四)基本数据管理
4.2 创建新变量 几个运算符: ^或**:求幂 x%%y:求余 x%/%y:整数除 4.3 变量的重编码 with(): within():可以修改数据框 4.4 变量重命名 包reshape中有个 ...
- R语言实战读书笔记(一)R语言介绍
1.3.3 工作空间 getwd():显示当前工作目录 setwd():设置当前工作目录 ls():列出当前工作空间中的对象 rm():删除对象 1.3.4 输入与输出 source():执行脚本
随机推荐
- log4net 添加自定义日志到数据库
添加操作日志到数据库举例: (一)建立数据库的操作日志表,如下我建立了一个简单的日志表 (二)配置文件中的配置如下 <log4net> <!--错误日志记录数据库--> < ...
- 记录下ECharts的一些功能
用到ECharts记录下一些功能免得以后找文档找不到. 这个博客对ECharts讲解很全面 http://www.stepday.com/my.stepday/?echarts // 使用 requi ...
- apache本地域名ip重定向vhosts
apache本地域名ip重定向,使本机通过指定域名访问到指定ip路径. 1.apache配置apache/conf/httpd.conf : 开启配置 Include conf/extra/http ...
- 让你的网站秒开 为IIS启用“内容过期”
让你的网站秒开,为IIS启用“内容过期” 什么是内容过期? 当用户第一次访问你的网站,浏览器从你的网站主机下载内容,如果用户第二次访问你的网站,浏览器从缓存读取内容.你知道浏览器从缓存读取网页有多快吗 ...
- python关于列表转为字典的两个小方法
1.现在有两个列表,list1 = ['key1','key2','key3']和list2 = ['1','2','3'],把他们转为这样的字典:{'key1':'1','key2':'2','ke ...
- html中select只读显示
因为Select下拉框只支持disabled属性,不支持readOnly属性,而在提交时,disabled的控件,又是不提交值的.现提供以下几种解决方案: 1.在html中使用以下代码,在select ...
- python 安装mysql-python模块
方式一 使用yum安装 # yum install MySQL-python 方式二 使用pip 安装 # pip install mysql-python 使用pip方式安装需要提前安装如下依赖 m ...
- 给RecyclerView实现的GridView加上HeaderView和FooterView
给RecyclerView设置布局管理器 GridLayoutManager gridLayoutManager = new GridLayoutManager(this, 3); 写适配器,添加子项 ...
- 20145209&20145309信息安全系统设计基础实验报告 (3)
实验内容.步骤与体会: 实验过程的理解,实验指导书中知识点的理解. (1)为什么在双击了GIVEIO和JTAG驱动安装文件后还需要手动进行配置? 因为安装文件只是将驱动文件释放了出来,并没有在系统中将 ...
- only for equality comparisons Hash Index Characteristics
http://dev.mysql.com/doc/refman/5.7/en/index-btree-hash.html Hash Index Characteristics Hash indexes ...