Peeking into Apache Flink's Engine Room
http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html
Join Processing in Apache Flink
In this blog post, we cut through Apache Flink’s layered architecture and take a look at its internals with a focus on how it handles joins. Specifically, I will
- show how easy it is to join data sets using Flink’s fluent APIs,
- discuss basic distributed join strategies, Flink’s join implementations, and its memory management,
- talk about Flink’s optimizer that automatically chooses join strategies,
- show some performance numbers for joining data sets of different sizes, and finally
- briefly discuss joining of co-located and pre-sorted data sets
这篇blog会从flink内部详细看看是如何处理join的,尤其,
如何用Flink API,简单的实现join
讨论基本的join策略,flink join的实现和内存管理
讨论flink的优化器,如何自动选择join策略
显示不同数据size上的性能数据,
最后简单讨论一下co-located和预排序的数据集的join问题
How do I join with Flink?
Flink provides fluent APIs in Java and Scala to write data flow programs.
// define your data types
case class PageVisit(url: String, ip: String, userId: Long)
case class User(id: Long, name: String, email: String, country: String) // get your data from somewhere
val visits: DataSet[PageVisit] = ...
val users: DataSet[User] = ... // filter the users data set
val germanUsers = users.filter((u) => u.country.equals("de"))
// join data sets
val germanVisits: DataSet[(PageVisit, User)] =
// equi-join condition (PageVisit.userId = User.id)
visits.join(germanUsers).where("userId").equalTo("id")
可以看到用flink api实现join还是比较简单的
How does Flink join my data?
Flink如何做join,分两个阶段,
Ship Strategy
Local Strategy
Ship Strategy
对于分布式数据,数据是散落在各个partition中的,要做join,首先要把相同join key的数据放到一起,这个过程称为Ship Strategy
Flink的Ship Strategy有两种,
Repartition-Repartition strategy (RR)
The Repartition-Repartition strategy partitions both inputs, R and S, on their join key attributes using the same partitioning function.
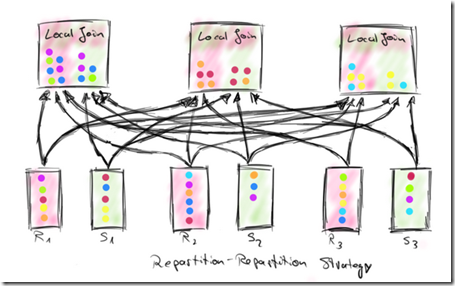
比如,R,S做join,我们就用一个相同partition函数,按join key,把R,S的所有分区,shuffle到3个local join上
这样做需要把full shuffle of both data sets over the network
Broadcast-Forward strategy (BF)
The Broadcast-Forward strategy sends one complete data set (R) to each parallel instance that holds a partition of the other data set (S)
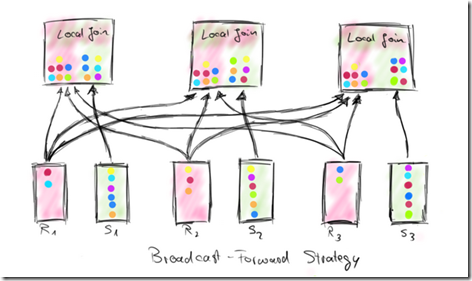
S不动,把R广播到所有的join实例上;显然如果R足够小,这样做是很有效的
Flink’s Memory Management
对join的场景,很容易想到,在ship阶段,需要shuffle大量的数据,内存是否会OutOfMemoryException,或是否会发生full gc
Flink handles this challenge by actively managing its memory.
When a worker node (TaskManager) is started, it allocates a fixed portion (70% by default) of the JVM’s heap memory that is available after initialization as 32KB byte arrays.
This design has several nice properties.
First, the number of data objects on the JVM heap is much lower resulting in less garbage collection pressure.
Second, objects on the heap have a certain space overhead and the binary representation is more compact. Especially data sets of many small elements benefit from that.
Third, an algorithm knows exactly when the input data exceeds its working memory and can react by writing some of its filled byte arrays to the worker’s local filesystem. After the content of a byte array is written to disk, it can be reused to process more data. Reading data back into memory is as simple as reading the binary data from the local filesystem.
The following figure illustrates Flink’s memory management.
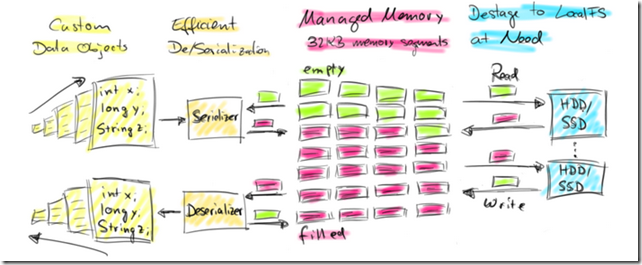
Flink是主动管理JVM的heap内存的,会申请一组32KB的memory segments,给各种算法用
好处就是,这样减少GC的压力;而且数据是序列化成binary后存储,overhead很小;自己管理内存,内存不够的时候,可以知道并写磁盘文件
Local Strategies
After the data has been distributed across all parallel join instances using either a Repartition-Repartition or Broadcast-Forward ship strategy, each instance runs a local join algorithm to join the elements of its local partition.
Flink’s runtime features two common join strategies to perform these local joins:
- the Sort-Merge-Join strategy (SM) and
- the Hybrid-Hash-Join strategy (HH).
在ship strategy,我们已经把相同join key的数据,放到同一个local partition上,现在要做的只是run一个local join算法
Flink有两种local join算法,
The Sort-Merge-Join works by first sorting both input data sets on their join key attributes (Sort Phase) and merging the sorted data sets as a second step (Merge Phase).
The sort is done in-memory if the local partition of a data set is small enough.
Otherwise, an external merge-sort is done by collecting data until the working memory is filled, sorting it, writing the sorted data to the local filesystem, and starting over by filling the working memory again with more incoming data. After all input data has been received, sorted, and written as sorted runs to the local file system, a fully sorted stream can be obtained. This is done by reading the partially sorted runs from the local filesystem and sort-merging the records on the fly. Once the sorted streams of both inputs are available, both streams are sequentially read and merge-joined in a zig-zag fashion by comparing the sorted join key attributes, building join element pairs for matching keys, and advancing the sorted stream with the lower join key. The figure below shows how the Sort-Merge-Join strategy works.
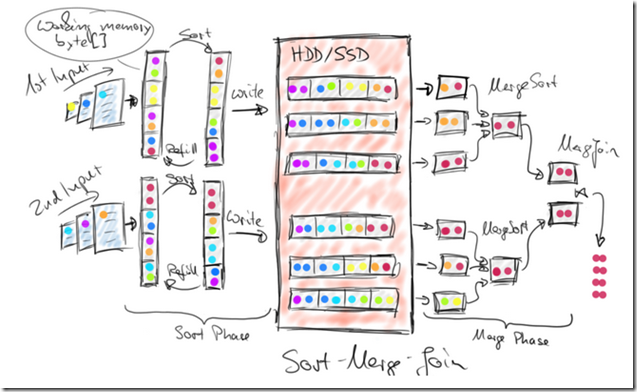
这个算法,如其名,两个过程,sort,merge
首先是,sort,如果数据足够小,在内存中直接sort,这个比较简单
如果数据比较大,需要用到外排算法,比如内存可以排序1G数据,而我有3G数据,那就每次只读1G,排序,存入一个文件,这样最终会产生3个已局部排序的文件,如图
读的时候,同时打开3个文件,边读边merge就可以产生一个全局有序的stream
然后是,merge,对于两个已排序的inputs,做join很简单
The Hybrid-Hash-Join distinguishes its inputs as build-side and probe-side input and works in two phases, a build phase followed by a probe phase.
In the build phase, the algorithm reads the build-side input and inserts all data elements into an in-memory hash table indexed by their join key attributes. If the hash table outgrows the algorithm’s working memory, parts of the hash table (ranges of hash indexes) are written to the local filesystem. The build phase ends after the build-side input has been fully consumed.
In the probe phase, the algorithm reads the probe-side input and probes the hash table for each element using its join key attribute. If the element falls into a hash index range that was spilled to disk, the element is also written to disk. Otherwise, the element is immediately joined with all matching elements from the hash table. If the hash table completely fits into the working memory, the join is finished after the probe-side input has been fully consumed. Otherwise, the current hash table is dropped and a new hash table is built using spilled parts of the build-side input.
This hash table is probed by the corresponding parts of the spilled probe-side input. Eventually, all data is joined. Hybrid-Hash-Joins perform best if the hash table completely fits into the working memory because an arbitrarily large the probe-side input can be processed on-the-fly without materializing it. However even if build-side input does not fit into memory, the the Hybrid-Hash-Join has very nice properties. In this case, in-memory processing is partially preserved and only a fraction of the build-side and probe-side data needs to be written to and read from the local filesystem. The next figure illustrates how the Hybrid-Hash-Join works.
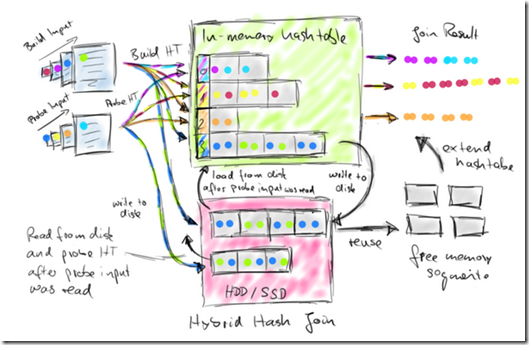
这个算法会把两个input,分成bulid input和probe input
其中build input会用于以join key来build一个hash table,如果这个hash table足够小,那么很简单
当build完hash table后,我们只需要遍历probe input,如果落在hash table中,就做join
这个方法,如果build input足够小,会非常高效,因为我们不需要在内存中存probe input,只需要读一条处理一条即可
但如果build input比较大,内存放不下整个hash table怎么办?
也很简单,内存不够的时候,把部分hash table,以hash index range,存入磁盘
这样当遍历probe input的时候,如果对应的hash table在磁盘,那么暂时把这部分probe input也存入磁盘
最后,当遍历完probe input后,内存中的hash table已经完成join,删掉,载入磁盘中的hash table完成最后的join
How does Flink choose join strategies?
Ship and local strategies do not depend on each other and can be independently chosen.
Therefore, Flink can execute a join of two data sets R and S in nine different ways by combining any of the three ship strategies (RR, BF with R being broadcasted, BF with S being broadcasted) with any of the three local strategies (SM, HH with R being build-side, HH with S being build-side).
Flink features a cost-based optimizer which automatically chooses the execution strategies for all operators including joins.
Without going into the details of cost-based optimization, this is done by computing cost estimates for execution plans with different strategies and picking the plan with the least estimated costs.
Thereby, the optimizer estimates the amount of data which is shipped over the the network and written to disk.
If no reliable size estimates for the input data can be obtained, the optimizer falls back to robust default choices.
A key feature of the optimizer is to reason about existing data properties.
For example, if the data of one input is already partitioned in a suitable way, the generated candidate plans will not repartition this input. Hence, the choice of a RR ship strategy becomes more likely. The same applies for previously sorted data and the Sort-Merge-Join strategy. Flink programs can help the optimizer to reason about existing data properties by providing semantic information about user-defined functions [4].
While the optimizer is a killer feature of Flink, it can happen that a user knows better than the optimizer how to execute a specific join. Similar to relational database systems, Flink offers optimizer hints to tell the optimizer which join strategies to pick [5].
总的来说,Ship和local的策略可以分开选择;
Flink的optimizer会自动选择策略,根据就是,optimizer会对每个策略进行cost estimates,选择cost相对较小的策略
Peeking into Apache Flink's Engine Room的更多相关文章
- Stream Processing for Everyone with SQL and Apache Flink
Where did we come from? With the 0.9.0-milestone1 release, Apache Flink added an API to process rela ...
- 腾讯大数据平台Oceanus: A one-stop platform for real time stream processing powered by Apache Flink
January 25, 2019Use Cases, Apache Flink The Big Data Team at Tencent In recent years, the increa ...
- Blink: How Alibaba Uses Apache Flink
This is a guest post from Xiaowei Jiang, Senior Director of Alibaba’s search infrastructure team. Th ...
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- Building real-time dashboard applications with Apache Flink, Elasticsearch, and Kibana
https://www.elastic.co/cn/blog/building-real-time-dashboard-applications-with-apache-flink-elasticse ...
- 终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
摘要: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里妹导 ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿 Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目.是当前最 ...
随机推荐
- 微信聊天测试脚本 wx_sample.php
<?php </FuncFlag> </xml>); curl_setopt($ch, CURLO ...
- 修改ViewPager调用setCurrentItem时,滑屏的速度
原文摘自: 修改ViewPager调用setCurrentItem时,滑屏的速度 在使用ViewPager的过程中,有需要直接跳转到某一个页面的情况,这个时候就需要用到ViewPager的setCur ...
- CC2540开发板学习笔记(九)—— BLE协议简介
一.BLE协议简介 1.协议是什么? 协议是一系列的通信标准,双方需要共同按照这进行正常数据 协议是一系列的通信标准,双方需要共同按照这进行正常数据发射和 接收.协议栈是的具体实现形式,通俗点来理解就 ...
- Github排行榜
http://githubranking.com/ 中国区开发者排行榜: http://githubrank.com/ 也可以在官网查询: https://github.com/search?q=st ...
- Java的锁优化
高效并发是从JDK 1.5到JDK 1.6的一个重要改进,HotSpot虚拟机开发团队在这个版本上花费了大量的精力去实现各种锁优化技术,如适应性自旋(Adaptive Spinning).锁消除(Lo ...
- 关于用了SSH连接之后,但是Chrome中访问stackoverflow超慢的原因
FQ条件如下: SSH + Chrome + ProxySwitchySharp 其中ProxySwitchySharp已经设置了通配符: 但是打开 www.stackoverflow.com还是奇慢 ...
- BZOJ3838 : [Pa2013]Raper
将选取的$A$看成左括号,$B$看成右括号,那么答案是一个合法的括号序列. 那么只要重复取出$k$对价值最小的左右括号,保证每时每刻都是一个合法的括号序列即可. 将$($看成$1$,$)$看成$-1$ ...
- NOIP 2002过河卒 Label:dp
题目描述 如图,A 点有一个过河卒,需要走到目标 B 点.卒行走规则:可以向下.或者向右.同时在棋盘上的任一点有一个对方的马(如上图的C点),该马所在的点和所有跳跃一步可达的点称为对方马的控制点.例如 ...
- Chromium源码--视频播放流程分析(WebMediaPlayerImpl解析)
转载请注明出处:http://www.cnblogs.com/fangkm/p/3797278.html 承接上一篇文章.媒体播放,需要指定一个源文件,html5用URL格式来指定视频源文件地址,可以 ...
- 【C语言】10-字符和字符串常用处理函数
一.字符处理函数 下面介绍的两个字符处理函数都是在stdio.h头文件中声明的. 1.字符输出函数putchar putchar(65); // A putchar('A'); // A int a ...