Self-Taught Learning to Deep Networks
In this section, we describe how you can fine-tune and further improve the learned features using labeled data. When you have a large amount of labeled training data, this can significantly improve your classifier's performance.
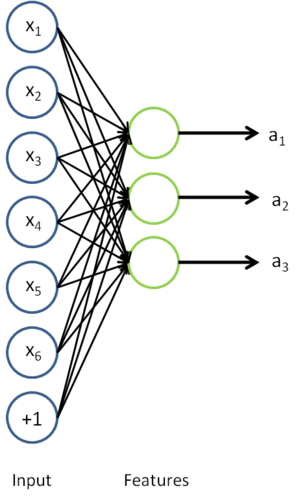
In self-taught learning, we first trained a sparse autoencoder on the unlabeled data. Then, given a new example
, we used the hidden layer to extract features
. This is illustrated in the following diagram:
We are interested in solving a classification task, where our goal is to predict labels
. We have a labeled training set
of
labeled examples. We showed previously that we can replace the original features
with features
computed by the sparse autoencoder (the "replacement" representation). This gives us a training set
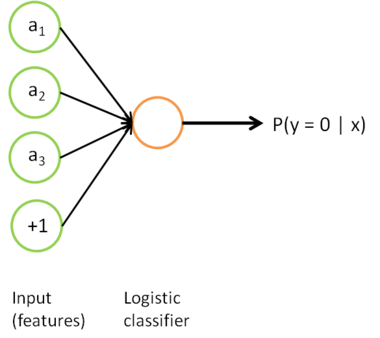
. Finally, we train a logistic classifier to map from the features
to the classification label
.
we can draw our logistic regression unit (shown in orange) as follows:
Now, consider the overall classifier (i.e., the input-output mapping) that we have learned using this method. In particular, let us examine the function that our classifier uses to map from from a new test example
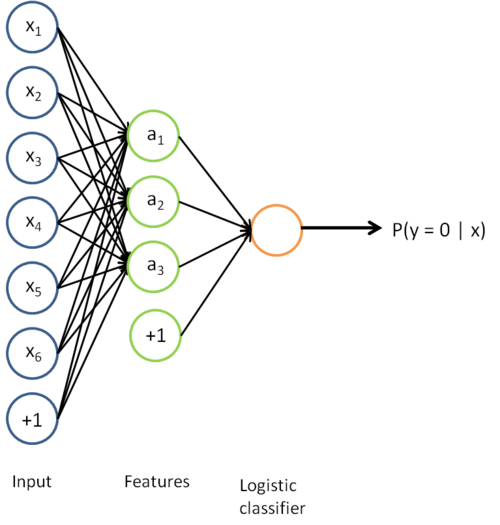
The parameters of this model were trained in two stages: The first layer of weights 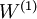 mapping from the input to the hidden unit activations were trained as part of the sparse autoencoder training process. The second layer of weights
mapping from the input to the hidden unit activations were trained as part of the sparse autoencoder training process. The second layer of weights 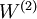 mapping from the activations to the output was trained using logistic regression (or softmax regression).
mapping from the activations to the output was trained using logistic regression (or softmax regression).
But the form of our overall/final classifier is clearly just a whole big neural network. So, having trained up an initial set of parameters for our model (training the first layer using an autoencoder, and the second layer via logistic/softmax regression), we can further modify all the parameters in our model to try to further reduce the training error. In particular, we can fine-tune the parameters, meaning perform gradient descent (or use L-BFGS) from the current setting of the parameters to try to reduce the training error on our labeled training set .
When fine-tuning is used, sometimes the original unsupervised feature learning steps (i.e., training the autoencoder and the logistic classifier) are called pre-training. The effect of fine-tuning is that the labeled data can be used to modify the weights W(1) as well, so that adjustments can be made to the features a extracted by the layer of hidden units.
if we are using fine-tuning usually we will do so with a network built using the replacement representation. (If you are not using fine-tuning however, then sometimes the concatenation representation can give much better performance.)
When should we use fine-tuning? It is typically used only if you have a large labeled training set; in this setting, fine-tuning can significantly improve the performance of your classifier. However, if you have a large unlabeled dataset (for unsupervised feature learning/pre-training) and only a relatively small labeled training set, then fine-tuning is significantly less likely to help.
Self-Taught Learning to Deep Networks的更多相关文章
- 【论文考古】联邦学习开山之作 Communication-Efficient Learning of Deep Networks from Decentralized Data
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, "Communication-Efficient Learni ...
- Communication-Efficient Learning of Deep Networks from Decentralized Data
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Proceedings of the 20th International Conference on Artificial Intell ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
- (转)Understanding, generalisation, and transfer learning in deep neural networks
Understanding, generalisation, and transfer learning in deep neural networks FEBRUARY 27, 2017 Thi ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- 深度学习材料:从感知机到深度网络A Deep Learning Tutorial: From Perceptrons to Deep Networks
In recent years, there’s been a resurgence in the field of Artificial Intelligence. It’s spread beyo ...
- This instability is a fundamental problem for gradient-based learning in deep neural networks. vanishing exploding gradient problem
The unstable gradient problem: The fundamental problem here isn't so much the vanishing gradient pro ...
- [译]深度神经网络的多任务学习概览(An Overview of Multi-task Learning in Deep Neural Networks)
译自:http://sebastianruder.com/multi-task/ 1. 前言 在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI.为了达到这个目标,我 ...
- Learning Combinatorial Embedding Networks for Deep Graph Matching(基于图嵌入的深度图匹配)
1. 文献信息 题目: Learning Combinatorial Embedding Networks for Deep Graph Matching(基于图嵌入的深度图匹配) 作者:上海交通大学 ...
随机推荐
- <Sicily>Prime Palindromes
一.题目描述 The number 151 is a prime palindrome because it is both a prime number and a palindrome (it i ...
- echarts如何修改数据视图dataView中的样式
原文链接:点我 做了一个现实折线图的图表,通过右上角icon可以自由切换成柱状图,表格.在表格中遇到的一点小问题,解决方案如下: 1.场景重现 这是一个显示两个折线图的图表,一切看起来都很顺利.但是点 ...
- 题解 P3372 【【模板】线段树1 】
看了一下题解里的zkw线段树,感觉讲的不是很清楚啊(可能有清楚的但是我没翻到,望大佬勿怪). 决定自己写一篇...希望大家能看明白... zkw线段树是一种优秀的非递归线段树,速度比普通线段树快两道三 ...
- Opencv 三次样条曲线(Cubic Spline)插值
本系列文章由 @YhL_Leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/47707679 1.样条曲线简介 样条曲 ...
- Mysql 锁表 for update (引擎/事务)
因为之前用过oracle,知道利用select * for update 可以锁表.所以很自然就想到在mysql中能不能适应for update来锁表呢. 学习参考如下 由于InnoDB预设是Row- ...
- MySQL auttoReconnect
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: The last packet successfully received from ...
- 洛谷——P3368 【模板】树状数组 2
https://www.luogu.org/problem/show?pid=3368 题目描述 如题,已知一个数列,你需要进行下面两种操作: 1.将某区间每一个数数加上x 2.求出某一个数的和 输入 ...
- Varnish 缓存加速, Varnish 菜鸟看过来,Varnish实战
Varnish可以有效降低web服务器的负载,提升访问速度.按照HTTP协议的处理过程,web服务器接受请求并且返回处理结果,理想情况下服务器要在不做额外处理的情况下,立即返回结果,但实际情况并非如此 ...
- Android调用camera错误setParameters failed深层解析
1. Camera Camera是Android framework里面支持的,同意你拍照和拍摄视频的设备,那么,在使用camera开发中总是会遇到一些问题,比例如以下面这样子的: E/Android ...
- Spring MVC学习------------WebApplicationContext
父子上下文(WebApplicationContext) 假设你使用了listener监听器来载入配置.一般在Struts+Spring+Hibernate的项目中都是使用listener监听器的. ...