标准输入输出 stdio 流缓冲
**From : http://www.pixelbeat.org/programming/stdio_buffering/ **
**译者:李秋豪**
我发现找出标准流用的是什么缓冲是一件困难的事。
例如下面这个使用unix shell 管道的例子:
$ command1 | command2
下图显示了shell fork了两个进程并通过一个管道将他们联系起来。在这个连接中移动使用了三个缓冲.
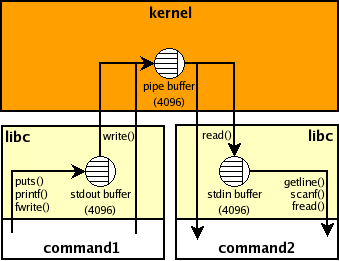
内核中的缓冲区室友pipe系统函数生成的,它的大小取决于操作系统的页大小。我们无法也没必要控制这个缓冲区的大小,因为它会立即转送数据(至少在linux上是这样)。[更新:这个pipe buffer 已经变化为 circular buffers (16 x 4KiB)并且有一个新的 proposed patch 使得它的大小是动态的]
另外两个缓冲是关于流的,为了提高效率,仅仅在第一次使用流的时候申请缓冲区空间。三个标准流(stdin, stdout, stderr)会在几乎所有的unix GNU C程序开始执行自动被创建,新的流也可以被创建用来连接文件、套接字、管道等等。你可以通过控制缓冲策略(无缓冲,行缓冲,满缓冲)来控制数据的读写方法。我使用这个程序来确定标准流的默认缓冲区的特性:
/* Output info about the default buffering parameters
* applied by libc to stdin, stdout and stderr.
* Note the info is sent to stderr, as redirecting it
* makes no difference to its buffering parameters.
* Note gnulib has fbufmode() to make this portable.
*/
#include <stdio_ext.h>
#include <unistd.h>
#include <stdlib.h>
FILE* fileno2FILE(int fileno){
switch(fileno) {
case 0: return stdin;
case 1: return stdout;
case 2: return stderr;
default: return NULL;
}
}
const char* fileno2name(int fileno){
switch(fileno) {
case 0: return "stdin";
case 1: return "stdout";
case 2: return "stderr";
default: return NULL;
}
}
int main(void)
{
if (isatty(0)) {
fprintf(stderr,"Hit Ctrl-d to initialise stdin\n");
} else {
fprintf(stderr,"Initialising stdin\n");
}
char data[4096];
fread(data,sizeof(data),1,stdin);
if (isatty(1)) {
fprintf(stdout,"Initialising stdout\n");
} else {
fprintf(stdout,"Initialising stdout\n");
fprintf(stderr,"Initialising stdout\n");
}
fprintf(stderr,"Initialising stderr\n"); //redundant
int i;
for (i=0; i<3; i++) {
fprintf(stderr,"%6s: tty=%d, lb=%d, size=%d\n",
fileno2name(i),
isatty(i),
__flbf(fileno2FILE(i))?1:0,
__fbufsize(fileno2FILE(i)));
}
return EXIT_SUCCESS;
}
默认缓冲策略:
- stdin总是缓冲的
- stderr总是无缓冲的
- 如果stdout是终端的话缓冲是行缓冲的,否则是满缓冲的。(补充一下,GNU里面定义的可交互设备,显然终端是可交互设备)
默认缓冲大小:
- 缓冲大小只会直接影响缓冲策略
- 内核的pipe buffer 已经变化为 circular buffers (16 x 4KiB)并且有一个新的 proposed patch 使得它的大小是动态的
- 如果stdin/stdout 连接的是交互设备那么默认大小是1024,否则是4096
stdio 输出缓冲的问题
现在来考虑一个问题:数据源的信息是间隔发送的,并且接受者希望立即收到新产生的数据。
例如,一个人想要过滤 tcpdump -l 或者 tail -f 的输出等等(注意有一些过滤器比如sort要求一次缓存所有数据到内部,所以这里不能使用)。
考虑下面这个操作,从动态网络日志终端数据中过滤出不一样的IP地址:
$ tail -f access.log | cut -d' ' -f1 | uniq
问题在于,如果按照上面这个命令,我们将不能实时的看到增加的主机IP,示例图如下:
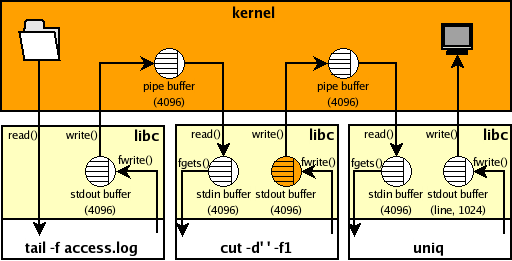
高亮的缓冲区导致了问题的发生。由于该缓存区连接了一个管道缓冲区,他会等到数据达到4096字节后再作为一个块传送给uniq。注意到tail的标准输出也有这个问题,但是tail -f调用会自动清除缓冲区当有新的数据输入时,所以这里不会产生影响( tcpdump -l, grep --line-buffered sed --unbuffered 也是这样)。另外,由于uniq标准输出连接的是一个可交互设备,所以当有新的一行数据到达时也会自动清除缓冲区,不会产生影响。
stdio 输入缓冲问题
正如向stdout一样,stdin也使用缓冲区以增加效率。
如果一个一个字节的读入显然会有更多控制的空间,但是这样是不实际的。
考虑以下命令:
$ printf "one\ntwo\nthree\n" | ( sed 1q ; sed 1q ; sed 1q )
one
(译者注:这里的q是sed流编辑器的退出命令,1q表示当输出到达第一行结束时退出。参考The q or quit command)
正如你所见到的,第一个sed进程读取了所有数据,导致后面的sed没办法读入数据。注意仅仅将stdin缓冲区设置为行缓冲是没有用的,因为只有当输出缓冲区被清除的时候才会产生控制效果(译者注,如果没有输出的话,第一个sed还是会”一行一行的把输入数据读完)。以上的sed标准输入都是行缓冲Reading lines from stdin.通常你只能控制一个进程能否从stdin读入数据,或者读入特定规模的数据然后禁止读入。以下是这样的一个例子:
$ printf "one\ntwo\nthree\n" | ( ssh localhost printf 'zero\\n' ; cat )
zero
(译者注:后面的cat命令用于从stdin中读取数据输出到屏幕,防止printf的输出存储在缓冲区中。)
这个远程printf命令并不会从stdin读取数据(译者注:'zero\n'是参数),但是ssh client并不知道这个,所以他会读取前面printf传入的数据即stdin中读取数据。为了告诉ssh远程命令不需要读入数据,可以加上-n这个参数:
$ printf "one\ntwo\nthree\n" | ( ssh -n localhost printf 'zero\n' ; cat )
zero
one
two
three
常见的经历是你想要吧ssh放在后台当你知道远程命令不会读取数据的时候(利于常见的图像化程序),设置ssh client阻止读入数据可以防止远程应用程序停滞。你可以通过-f参数告诉ssh忽略stdin并且fork到后台。例如:ssh -fY localhost xterm(译者注:-Y Enables trusted X11 forwarding)。
stdio 缓冲控制
省略...(关键词:stdbuf, BUF_X_=Y where X = 0 (stdin), 1 (stdout), 2 (stderr) )
标准输入输出 stdio 流缓冲的更多相关文章
- 标准输入输出 stdio 流缓冲 buffering in standard streams
From : http://www.pixelbeat.org/programming/stdio_buffering/ 译者:李秋豪 我发现找出标准流用的是什么缓冲是一件困难的事. 例如下面这个使用 ...
- 标准输入输出() & 打印流 &配置文件
public static void main(String[] args) { //System 类 的 public final static InputStream in = null; // ...
- stdio - 标准输入输出库函数
SYNOPSIS 总览 #include <stdio.h> FILE *stdin; FILE *stdout; FILE *stderr; DESCRIPTION 描述 标注 I/O ...
- C语言的标准输入输出
1. 标准输入输出 标准输入.输出主要由缓冲区和操作方法两部分组.缓冲区实际上可以看做内存中的字符串数组,而操作方法主要是指printf.scanf.puts.gets,getcha.putcahr等 ...
- C 标准库 - <stdio.h>
一般地,在C语言或C++中,会把用来#include的文件的扩展名叫 .h,称其为头文件. #include文件的目的就是把多个编译单元(也就是c或者cpp文件)公用的内容,单独放在一个文件里减少整体 ...
- c++流缓冲学习---rdbuf()
我们使用STL编程的时候有时候会想到把一个流对象指向的内容用另一个流对象来输出,比如想把一个文件的内容输出到显示器上,我们可以用简单的两行代码就可以完成: ifstream infile(" ...
- UNIX环境编程学习笔记(13)——文件I/O之标准I/O流
lienhua342014-09-29 1 标准 I/O 流 之前学习的都是不带缓冲的 I/O 操作函数,直接针对文件描述符的,每调用一次函数可能都会触发一次系统调用,单次调用可能比较快捷.但是,对于 ...
- Python学习笔记015——文件file的常规操作之三(标准输入输出文件)
1 标准输入输出文件 在Python中,模块sys中含有标准的输入输出文件 sys.stdin 标准输入方法(一般是键盘) sys.stdout 标准输出方法(到显示器的缓冲输出) sys ...
- 《Unix环境高级编程》读书笔记 第5章-标准I/O流
1. 引言 标准I/O库由ISO C标准说明,由各个操作系统实现 标准I/O库处理很多细节,如缓冲区分配.以优化的块长度执行I/O等.这些处理使用户不必担心如何使用正确的块长度,这使得它便于用于使用, ...
随机推荐
- STEP 7-MicroWIN SMART 西门子PLC再次安装问题
我的电脑第一次安装s7(STEP 7-MicroWIN SMART 西门子PLC)是没有问题的,有一次不小心删除,再次安装却怎么也安装不上.猫那个咪的!Why! 网上各种查资料,完全不能解决问题,有的 ...
- 【1414软工助教】团队作业3——需求改进&系统设计 得分榜
题目 团队作业3--需求改进&系统设计 作业提交情况情况 本次作业所有团队都按时提交作业. 往期成绩 个人作业1:四则运算控制台 结对项目1:GUI 个人作业2:案例分析 结对项目2:单元测试 ...
- 201521123068《Java程序设计》第2周学习总结
1.本周学习总结 认识了各种类型与变量的使用 学习运算符的基本使用 变量命名不可以使用数字和一些特殊字符(如*.&.%等)作为开头: 变量名称不可以与Java关键词同名 学习了类与对象的区别 ...
- 201521123036 《Java程序设计》第1周学习总结
本周学习总结 本周的课是Java的入门.了解了Java的发展过程,运用平台,可跨平台的便利性.懂得jdk,jre,jvm的概念及区别.熟悉Java开发工具,掌握java程序的编译执行的详细过程. 书面 ...
- 201521123040《Java程序设计》第1周学习总结
1.本周学习总结 -初步接触JAVA,安装了JDK和eclipse,注册了码云,PTA,博客. -还没能熟悉eclipse,不能熟练把ec上的代码同步到码云. -不会编写程序,不了解JAVA的编写规则 ...
- Linux 安装 mysql 并配置
1.下载 下载地址:http://dev.mysql.com/downloads/mysql/5.6.html#downloads 下载版本:我这里选择的5.6.33,通用版,linux下64位 也可 ...
- phoenix
phoenix(直译做凤凰)的操作sql是通过jdbc发送到HBase的.phoenix的查询语句会转化为hbase的scan操作和服务器端的过滤器.如果我们手工使用HBase的api去写这些代码,也 ...
- gephi安装后无法打开
具体解决的方法是找到gephi.conf文件(在“gephi安装目录\etc”中)文件,添加下面的一行,指定jdkhome的路径. jdkhome="C:\Program Files (x8 ...
- 使用gc、objgraph干掉python内存泄露与循环引用!
Python使用引用计数和垃圾回收来做内存管理,前面也写过一遍文章<Python内存优化>,介绍了在python中,如何profile内存使用情况,并做出相应的优化.本文介绍两个更致命的问 ...
- 如何用kaldi做孤立词识别-初版
---------------------------------------------------------------------------------------------------- ...