浅析文本挖掘(jieba模块的应用)
一,文本挖掘
1.1 什么是文本挖掘
文本挖掘是指从大量文本数据中抽取事先未知的,可理解的,最终可用的知识的过程,同时运用这些知识更好的组织信息以便将来参考。
简单的说,文本挖掘是从大量文本中,比如微博评论,知乎评论,淘宝评论等文本数据中抽取出有价值的知识,并利用这些知识创造出价值。
1.2,文本挖掘基本流程
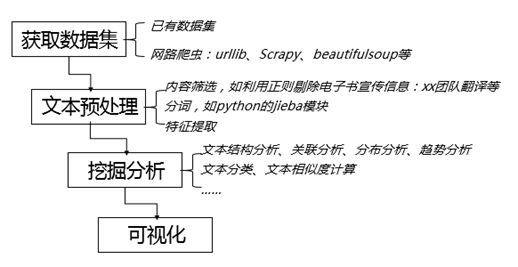
- 收集数据
- 数据集。如果是已经被人做成数据集了,这就省去了很多麻烦事
- 抓取。这个是 Python 做得最好的事情,优秀的包有很多,比如 scrapy,beautifulsoup等等。
- 预处理(对这里的高质量讨论结果的修改,下面的顺序仅限英文)
- 去掉抓来的数据中不需要的部分,比如 HTML TAG,只保留文本。结合 beautifulsoup 和正则表达式就可以了。pattern.web 也有相关功能。
- 处理编码问题。没错,即使是英文也需要处理编码问题!由于 Python2 的历史原因,不得不在编程的时候自己处理。英文也存在 unicode 和 utf-8 转换的问题,中文以及其他语言就更不用提了。这里有一个讨论,可以参考,当然网上也有很多方案,找到一个适用于自己的最好。
- 将文档分割成句子。
- 将句子分割成词。专业的叫法是 tokenize。
- 拼写错误纠正。pyenchant可以帮你!
- POS Tagging。nltk 是不二选择,还可以使用 pattern。
- 去掉标点符号。使用正则表达式就可以。
- 去掉长度过小的单词。len<3 的是通常选择。
- 去掉 non-alpha 词。同样,可以用正则表达式完成 \W 就可以。
- 转换成小写。
- 去掉停用词。Matthew L. Jockers 提供了一份比机器学习和自然语言处理中常用的停词表更长的停词表。中文的词停表 可以参考这个。
- lemmatization/stemming。nltk 里面提供了好多种方式,推荐用 wordnet 的方式,这样不会出现把词过分精简,导致词丢掉原型的结果,如果实在不行,也用 snowball 吧,别用 porter,porter 的结果我个人太难接受了,弄出结果之后都根本不知道是啥词了。MBSP也有相关功能。
- 重新去掉长度过小的词。是的,再来一遍。
- 重新去停词。上面这两部完全是为了更干净。
- 到这里拿到的基本上是非常干净的文本了。如果还有进一步需求,还可以根据 POS 的结果继续选择某一种或者几种词性的词。
1.3,文本挖掘的应用
- 基于内容的推荐,例如基于小说内容相似度的小说的推荐
- 信息自动分类
- 信息自动抽取
- 自动问答、机器翻译
二,jieba模块
jieba中文分词:做最好的Python中文分词组件
2.1,jieba模块的安装
安装在cmd中直接输入如下内容,即可安装
pip install jieba
2.2,文件结构与解析情况
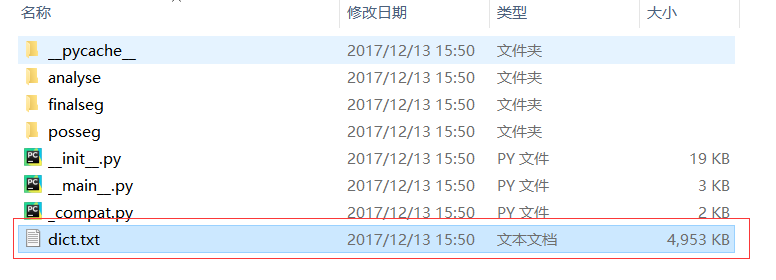
我们可以打开jieba模块的安装包,然后注意到上面的图片,里面有一个dict.txt文件,这个就是jieba模块的基础字典,也就是其分词的基础,打开字典后有如下图,分别表示词语,词频,词性:

其中对于词性的对照具体参考:http://www.360doc.cn/article/597197_346584378.html
2.3,分词模式
在jieba分词中支持三种分词模式(其中默认模式为精准模式)
————2.3.1精准模式:试图将句子最精确的切开,适合文本分析
import jieba
sentence = "李飞非常喜欢古城西安"
#精准模式
words1 = jieba.cut(sentence,cut_all=False)
for item in words1:
print(item)
print(words1)
print("----------------------------")
结果:
李飞
非常
喜欢
古城
西安
<generator object Tokenizer.cut at 0x000001A006AB2FC0>
----------------------------
————2.3.2全模式:把句子中所有的可能成词语都扫描出来,速度非常快,但是不能解决歧义
#开启全模式
words = jieba.cut(sentence,cut_all=True)
for item in words:
print(item)
print(words)
print("----------------------------")
结果:
李
飞
非常
喜欢
古城
城西
西安
<generator object Tokenizer.cut at 0x000001A00697B620>
----------------------------
————2.3.3搜索引擎模式 :在精准模式的基础上,对长词再次切分,提高招呼率,适合用于搜索引擎分词
#搜索引擎模式
words3 = jieba.cut_for_search(sentence)
for item in words3:
print(item)
print("----------------------------")
结果:
李飞
非常
喜欢
古城
西安
<generator object Tokenizer.cut at 0x000001A006AB2FC0>
----------------------------
————默认情况下,支持的是精确模式(下面举个例子)
#默认的话 是使用精准模式
words4 = jieba.cut(sentence)
for item in words4:
print(item)
print("----------------------------")
结果:
李飞
非常
喜欢
古城
西安
<generator object Tokenizer.cut at 0x000001A006AB2FC0>
----------------------------
2.4,查看词性(词性标注)
常见的词性如下:
a:形容词
c:连词
d:副词
e:叹词
f:方位词
i:成语
m:数词
n:名词
nr:人名
ns:地名
nt:机构团体
nz:其他专有名词
p:介词
r:代词
t:时间
u:助词
v:动词
vn:名动词
w:标点符号
un:未知词语
下面举个例子:
print("----------------------------")
sentence2 = "西安交通大学是一个很好的大学"
words6 =jieba.posseg.cut(sentence2)
for item in words6:
print(item.flag+"---------"+item.word)
结果:
----------------------------
nt---------西安交通大学
v---------是
m---------一个
a---------很好
uj---------的
n---------大学
2.5,词典加载(即自定义添加词典)
在分词过程中我们会遇到一些jieba自带的词典中没有的词这时候我们需要不断完善dict.txt中的内容,比如随意构造“仲英学院是一个宿舍的名称”
我们在添加字典的时候注意将txtx文档保存为utf-8编码格式,

不然会出现错误如下:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
raise ValueError('dictionary file %s must be utf-8' % f_name)
ValueError: dictionary file D:\python3\Lib\site-packages\jieba/dict2.txt must be utf-8
举个例子
import jieba.posseg sentences = "仲英学院是一个宿舍的名称"
print("------------------------------")
words7 =jieba.posseg.cut(sentences)
for item in words7:
print(item.flag+"---------"+item.word) jieba.load_userdict("D:\python3\Lib\site-packages\jieba/dict2.txt")
print("------------------------------")
words7 =jieba.posseg.cut(sentences)
for item in words7:
print(item.flag+"---------"+item.word)
结果:
nr---------仲英
n---------学院
v---------是
m---------一个
n---------宿舍
uj---------的
n---------名称
------------------------------
ns---------仲英
n---------学院
v---------是
m---------一个
n---------宿舍
uj---------的
n---------名称
2.6,更改词频
——2.6.1只能调高词频,不能调低词频
格式如下:
add_word(word, freq=None, tag=None)
suggest_freq(segment, tune=True)
举个例子:
#更改词频
import jieba
sentence8 = "我喜欢上海东方明珠"
words8 = jieba.cut(sentence8)
for item in words8:
print(item)
print("----------------")
jieba.add_word("上海东方")
words9 = jieba.cut(sentence8)
for item in words9:
print(item)
print("----------------")
jieba.suggest_freq("上海东方",tune = True)
words10 = jieba.cut(sentence8)
for item in words10:
print(item)
结果:
我
喜欢
上海
东方明珠
----------------
我
喜欢
上海
东方明珠
----------------
我
喜欢
上海
东方明珠
————2.6.2只能降低词频,不能调高词频
格式:
del_word(word)
suggest_freq(("segmentPart1","segmentPart2"),True)
举个例子:
print("----------------")
jieba.suggest_freq(("东方","明珠"),True)
words11 = jieba.cut(sentence8)
for item in words11:
print(item)
结果:
----------------
我
喜欢
上海东方
明珠
2.7,分词分析
进一步我们需要对文本信息进行相关分析,如返回词语所在位置、返回关键词等等。
————2.7.1提取文本中的关键词
其结果是结合文中出现的词频与字典中的词频进行排序
举个例子:
import jieba.analyse
sentence8 = "我喜欢上海东方明珠"
sentence9 = "我非常喜欢上海东方明珠" tag1 = jieba.analyse.extract_tags(sentence8,)
tag2 = jieba.analyse.extract_tags(sentence9,)
print(tag1)
print(tag2)
结果:
['东方明珠', '喜欢', '上海']
['东方明珠', '喜欢', '非常']
————2.7.2返回词语的所在位置
举个例子:
#返回词语的位置
import jieba.analyse sentence8 = "我喜欢上海东方明珠"
words10 = jieba.tokenize(sentence8)
for item in words10:
print(item)
words11 = jieba.tokenize(sentence8,mode="search")
for item in words11:
print(item)
结果:
('我', , )
('喜欢', , )
('上海', , )
('东方明珠', , )
----------------
('我', , )
('喜欢', , )
('上海', , )
('东方', , )
('方明', , )
('明珠', , )
('东方明珠', , )
返回的数据格式为:[('词语',开始位置,结束位置),...,()]
三,实战
————3.1我们先做一个小例子,分析一下血尸的词频
血尸的txt文件内容我传到下面:
50年前,长沙镖子岭。 四个土夫子正蹲在一个土丘上,所有人都不说话,直勾勾地盯着地上那把洛阳铲。 铲子头上带着刚从地下带出的旧土,离奇的是,这一坏土正不停地向外渗着鲜红的液体,就像刚刚在血液里蘸过一样。http://seputu.com/ “这下子麻烦大喽。”老烟头把他的旱烟在地上敲了敲,接着道,“下面是个血尸嘎,弄不好我们这点儿当当,都要撂在下面噢。” “下不下去喃?要得要不得,一句话,莫七里八里的!”独眼的小伙子说,“你说你个老人家腿脚不方便,就莫下去了,我和我弟两个下去,管他什么东西,直接给他来一梭子。” 老烟头不怒反笑,对边上的一个大胡子说:“你屋里二伢子海式撩天的,指不定什么时候就给翻盖子了,你得多教育教育,咱这买卖,不是有只匣子炮就能喔荷西天。” 那大胡子瞪了那年轻人一眼:“你崽子,怎么这么跟老太爷讲话,老太爷淘土的时候你他妈的还在你娘肚子里吃屎咧。” “我咋说……说错了,老祖宗不说了嘛,那血尸就是个好东西,下面宝贝肯定不少,不下去,走嘎一炉锅汤。” “你还敢顶嘴!”大胡子举手就打,被老烟头用烟枪挡了回去。 “打不得,你做伢那时候不还是一样,这叫上梁不正下梁歪!” 那独眼的小伙子看他老爸被数落了,低下头偷笑,老烟头咳嗽了一声,又敲了那独眼的少年一记头棍:“你笑个啥?碰到血尸,可大可小,上次你二公就是在洛阳挖到这东西,结果现在还疯疯癫癫的,都不知道着了什么道。等一下我先下去,你跟在我后面,二伢子你带个土耗子殿后,三伢子你就别下去了,四个人都下去,想退都来不及退,你就拉着土耗子的尾巴,我们在里面一吆喝你就把东西拉出来。” 年纪最小的那少年不服气了:“我不依,你们偏心,我告诉我娘去!” 老烟头大笑:“你看你看,三伢子还怯不得子了,别闹,等一下给你摸把金刀刀。” “我不要你摸,我自己会摸。” 那独眼老二就火了,一把揪住老三的耳朵:“你这杂家伙跟我寻事觅缝啰,招呼老子发宝气喃?!” 那年纪最小的少年看样子平日挨过不少揍,一看他二哥真火了,就吓得不敢吭声了,直望着他爹求救,怎料他爹已经去收拾家伙去了。他二哥这下得意了:“你何什咯样不带爱相啰,这次老头子也不帮你,你要再吆喝,我拧你个花麻鸡吧!” 老烟头拍拍老二的肩膀,大叫一声:“小子们,操家伙啰!”说完一把旋风铲已经舞开了。 半个小时候后,盗洞已经打得见不到底了,除了老二不时上来透气,洞里连声音都听不清楚了,老三等得不耐烦起来,就朝洞里大叫:“大爷爷,挖穿没有?” 隔了有好几秒,里面才传来一阵模糊的声音:“不……知道,你……待在上面,拉好……好绳子!” 是他二哥的声音,然后听到他那老烟头咳嗽了一声:“轻点声……听!有动静!” 然后就是死一般的沉寂。 老三知道下面肯定有什么变故,吓得也不敢说话了,突然他听到一阵让人毛骨悚然的咯咯声,好像蛤蟆叫一样的从洞里发出来。 然后他二哥在下面大吼了一声:“三伢子,拉!” 他不敢怠慢,一蹬地猛地拽住土耗子的尾巴,就往外拉,刚拉了几下,突然下面好像有什么东西咬住了,竟然有一股反力把绳子向盗洞里拉去,老三根本没想过还会有这种情况,差点就被拉到洞里去,他急中生智,一下子把尾巴绑在自己腰上,然后全身向后倒去,后背几乎和地面成了30度角,这个是他在村里和别的男孩子拔河的时候用的招数,这样一来他的体重就全部吃在绳子上,就算是匹骡子,他也能顶一顶。 果然,这样一来他就和洞里的东西对峙住了,双方都各自吃力,但是都拉不动分毫,僵持了有十几秒,就听到洞里一声盒子炮响,然后听到他爹大叫:“三伢子,快跑!!!!!!”就觉得绳子一松,土耗子嗖一声从洞里弹了出来,好像上面还挂了什么东西!那时候老三也顾不得那么多了,他知道下面肯定出了事情了,一把接住土耗子,扭头就跑! 他一口七跑出有二里多地,才敢停下来,掏出他怀里的土耗子一看,吓得大叫了一声,原来土耗子上勾着一只血淋淋的断手。他认得那手的模样,不由哭了出来,这手是分明是他二哥的。看样子他二哥就算不死也残废了。想到这里,他不由一咬牙,想回去救他二哥和老爹,刚一回头,却看见背后蹲着个血红血红的东西,正直勾勾地看着他。 这老三也不是个二流货色,平日里跟着他老爹大浪淘沙,离奇的事情见过不少,知道这地底下的,什么事情都有可能发生,最重要的不是大惊小怪,而是随机应变,要知道再凶险的鬼也强不过一活人,这什么黑凶白凶的,也得遵守物理定律,一梭子子弹打过去,打烂了也就没什么好怕的了。 想到这里,他把心一横,一边后退,一边腰上别着的一支匣子炮已经拽在手里,开了连发,只要那血红的东西有什么动静,就先给他劈头来个暴雨梨花。谁知道这时候那血红的东西竟然站起来了,老三仔细一看,顿觉得头皮发麻,胃里一阵翻腾,那分明是一个被剥了皮的人!混身上下血淋淋的,好像是自己整个儿从人皮里挤了出来一样。可是这样的一个人,竟然还能走动,那真是奇迹了,难道这就是血尸的真面目? 想着,那血尸一个弓身,突然就扑了过来,一下子老三就和他对上眼了,那血淋淋的脸一下子就贴着他的鼻子,一股酸气扑面而来,老三顺势向后一倒,同时匣子炮整一梭子子弹全部近距离打在了那东西胸膛上,距离过近,子弹全部都穿了过去,把那东西打的血花四溅,向后退了好几步。老三心中暗喜,再一回手对准那东西的脑袋就一扣扳机,就听喀嚓一声,枪竟然卡壳了! 这把老匣子炮是当年他二爷爷从一个军阀墓里挖出来的,想来也没用了多少年月,可惜这几年跟着他爹爹到处跑,也没工夫保养,平时候开枪的机会也少之又少,谁知道竟然在这节骨眼上卡壳了。那老三也真不简单,一看枪不好使唤,轮圆了胳膊用吃奶的力气把枪给砸了过去,也不管砸没砸到,扭头就跑。这次他连头也不敢回,看准前面一颗大树就奔了过去,寻思着怎么着它也不会爬树吧,突然脚下一绊,他一个狗吃屎,整张脸磕在一树墩上,顿时鼻子嘴巴里全是血。 老三狠狠一巴掌拍在地上,心里那个气啊,妈的怎么就这么背。 这时候听到后面风声响起,知道阎王爷来点名了,心一横,死就死吧,索性就趴在地上不起来了。没成想,那具血尸好像没看到他一样,竟然从他身上踩了过去,那血淋淋的脚板马上在他背后印下一个印子,这血尸出奇的重,一脚下去,老三就觉得嗓子一甜,只觉胆汁都被像踩吐了出来,而且背上那被踩过地方马上一阵奇痒,眼前马上朦胧起来,他马上意识到自己可能中毒了,而且毒性还非常的猛烈,恍惚间他看到不远处的地方,他二哥的那只手里好像还握着什么东西。 他用力眨了眨眼睛,仔细一看,原来是一块古帛片。他心想,自家二哥拼了命都要带出来的东西,肯定不是寻常东西,现在又不知道他们怎么样了,我好歹得把东西收好,万一我真的死了,他们找到我的尸体,也能从我身上找得着,那二哥的这只手也不算白断了,我也不至于白死。他一边这么想着,一边艰难地爬过去,用力掰开二哥紧握的手把那帛片从掌心里拿出来,塞进了自己袖子里。 这个时候他的耳朵也开始蜂鸣了,眼睛就像蒙了一层纱一样,手脚都开始凉起来。按他以往的经验,现在他裤裆里肯定大小便一大堆,中尸毒的人都死得很难看,他现在最希望的是不要给隔壁村的二丫头看见自己这个样子。 他就这么混混着胡想,脑子已经不怎么听他使唤了,这时候他又开始隐隐约约地听到他在盗洞口听到的那种咯咯怪声。www.seputu.com 老三隐约觉得一丝不对,刚才和血尸搏斗了这么些时候,也没听它叫过一声,现在怎么又叫起来了?难道刚才的那只并不是血尸?那刚才看到的又是什么东西呢?可惜这个时候他已经基本无法做思考了,他条件反射地抬起头看了一下,只见一张巨大的怪脸正俯下身子看着他,两只没有瞳孔的眼睛里空荡荡地毫无生气。
代码:
#分析血尸的词频
import jieba.analyse data = open("D:/pycode/血尸.txt").read()
tag = jieba.analyse.extract_tags(data,)
print(tag)
结果:
['老三', '二哥', '东西', '伢子', '烟头', '耗子', '血尸', '洞里', '下面', '独眼', '一声', '听到', '知道', '下去', '时候']
————3.2盗墓笔记实战
代码:
#盗墓笔记的关键词提取
import jieba.analyse data = open("D:/pycode/盗墓笔记.TXT").read()
tag = jieba.analyse.extract_tags(data,)
然后会出现如下错误:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xbf in position 2: illegal multibyte sequence
这时候我们对盗墓笔记文件做如下修改:

代码也做如下操作:
#盗墓笔记的关键词提取
import jieba.analyse data = open("D:/pycode/盗墓笔记.txt",encoding = 'utf-8').read()
tag = jieba.analyse.extract_tags(data,)
这时候就得到如下结果:
['三叔', '我们', '胖子', '油瓶', '潘子', '什么', '东西', '知道', '这里', '但是', '没有', '一个', '看到', '老痒', '事情', '时候', '一下', '感觉', '阿宁', '已经']
浅析文本挖掘(jieba模块的应用)的更多相关文章
- #19 re&jieba模块
前言 在Python中,需要对字符串进行大量的操作,有时需要从一个字符串中提取到特定的信息,用切片肯定是不行的,所有这一节记录两个强大的文本处理模块,一个是正则表达式re模块,另一个是中文处理模块ji ...
- jieba模块
jieba模块 下载 pip install jieba 使用 import jieba 精确模式 jieba.cut() 直接打印出的是单个文字 转换成列表-->jieba.lcut() im ...
- python从入门到大神---Python的jieba模块简介
python从入门到大神---Python的jieba模块简介 一.总结 一句话总结: jieba包是分词技术,也就是将一句话分成多个词,有多种分词模型可选 1.分词模块包一般有哪些分词模式(比如py ...
- python jieba模块详解
借鉴于 [jieba 模块文档] 用于自己学习和记录! jieba 模块是一个用于中文分词的模块 此模块支持三种分词模式 精确模式(试图将句子最精确的切开,适合文本分析) 全模式(把句子在所有可以成词 ...
- Python的jieba模块简介
现如今,词云技术遍地都是,分词模块除了jieba也有很多,主要介绍一下jieba的基本使用 import jieba import jieba.posseg as psg from os import ...
- python基础===jieba模块,Python 中文分词组件
api参考地址:https://github.com/fxsjy/jieba/blob/master/README.md 安装自行百度 基本用法: import jieba #全模式 word = j ...
- python成长之路【第十篇】:浅析python select模块
一.select介绍 select()的机制中提供一fd_set的数据结构,实际上是一long类型的数组, 每一个数组元素都能与一打开的文件句柄(不管是Socket句柄,还是其他文件或命名管道或设备句 ...
- jieba结巴分词
pip install jieba安装jieba模块 如果网速比较慢,可以使用豆瓣的Python源:pip install -i https://pypi.douban.com/simple/ jie ...
- Python基于jieba的中文词云
今日学习了python的词云技术 from os import path from wordcloud import WordCloud import matplotlib.pyplot as plt ...
随机推荐
- Appium python自动化测试系列之自动化截图(十一)
11.1 截图函数的正常使用 11.1.1 截图方法 无论是在手动测试还是自动化测试中场景复现永远是一个很重要的事情,有时候一些问题可能很难复现,这个都需要测试人员对bug有很高的敏感度,在一般的情况 ...
- Lua中metatable和__index的联系
Lua中metatable和__index的联系 可以参考 http://blog.csdn.net/xenyinzen/article/details/3536708 来源 http://blog. ...
- poj 3662 Telephone Lines
Telephone Lines Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 7115 Accepted: 2603 D ...
- input 密码框调出手机的数字键盘
对于某些密码,想要在手机上调出数字键盘,同时要隐藏文字.可结合type=tel和 text-security属性达到目的. input{ -webkit-text-security:disc; tex ...
- css媒体查询:响应式网站
css媒体查询:响应式网站 媒体查询 包含了一个媒体类型和至少一个使用如宽度.高度和颜色等媒体属性来限制样式表范围的表达式.CSS3加入的媒体查询使得无需修改内容便可以使样式应用于某些特定的设备范围. ...
- Python爬虫小实践:寻找失踪人口,爬取失踪儿童信息并写成csv文件,方便存入数据库
前两天有人私信我,让我爬这个网站,http://bbs.baobeihuijia.com/forum-191-1.html上的失踪儿童信息,准备根据失踪儿童的失踪时的地理位置来更好的寻找失踪儿童,这种 ...
- Celery 源码解析四: 定时任务的实现
在系列中的第二篇我们已经看过了 Celery 中的执行引擎是如何执行任务的,并且在第三篇中也介绍了任务的对象,但是,目前我们看到的都是被动的任务执行,也就是说目前执行的任务都是第三方调用发送过来的.可 ...
- 百度统计的JS脚本原理分析
首先,百度统计会要求我们在要统计的页面中嵌入一段js语句,类似如下: <script type="text/javascript">var _bdhmProtocol ...
- Spring的IOC容器第一辑
一.Spring的IOC容器概述 Spring的IOC的过程也被称为依赖注入(DI),那么对象可以通过构造函数参数,工厂方法的参数或在工厂方法构造或返回的对象实例上设置的属性来定义它们的依赖关系,然后 ...
- [转载] 红黑树(Red Black Tree)- 对于 JDK TreeMap的实现
转载自http://blog.csdn.net/yangjun2/article/details/6542321 介绍另一种平衡二叉树:红黑树(Red Black Tree),红黑树由Rudolf B ...