HDFS源码分析之NameNode(2)————Format
在Hadoop的HDFS部署好了之后并不能马上使用,而是先要对配置的文件系统进行格式化。在这里要注意两个概念,一个是文件系统,此时的文件系统在物理上还不存在,或许是网络磁盘来描述会更加合适;二就是格式化,此处的格式化并不是指传统意义上的本地磁盘格式化,而是一些清除与准备工作。本文接下来将主要讨论NameNode节点上的格式化。
我们都知道,NameNode主要被用来管理整个分布式文件系统的命名空间(实际上就是目录和文件)的元数据信息,同时为了保证数据的可靠性,还加入了操作日志,所以,NameNode会持久化这些数据(保存到本地的文件系统中)。对于第一次使用HDFS,在启动NameNode时,需要先执行-format命令,然后才能正常启动NameNode节点的服务。那么,NameNode的fromat命令到底做了什么事情呢?
hadoop namenode -format
在NameNode节点上,有两个最重要的路径,分别被用来存储元数据信息和操作日志,而这两个路径来自于配置文件,它们对应的属性分别是dfs.name.dir和dfs.name.edits.dir,同时,它们默认的路径均是/tmp/hadoop/dfs/name。格式化时,NameNode会清空两个目录下的所有文件,之后,会在目录dfs.name.dir下创建文件:
{dfs.name.dir}/current/fsimage
{dfs.name.dir}/current/fstime
{dfs.name.dir}/current/VERSION
{dfs.name.dir}/image/fsimage
会在目录dfs.name.edits.dir下创建文件:
{dfs.name.edits.dir}/current/edits
{dfs.name.edits.dir}/current/fstime
{dfs.name.edits.dir}/current/VERSION
{dfs.name.edits.dir}/image/fsimage
那么这些文件又是用来干什么的呢?
在介绍这文件的用途之前,我们可以将dfs.name.dir和dfs.name.edits.dir配置成相同的目录,这样的话,NameNode执行格式化之后,会产生如下的文件:{dfs.name.dir}/current/fsimage、{dfs.name.dir}/current/edits、{dfs.name.dir}/current/fstime、{dfs.name.dir}/current/VERSION、{dfs.name.dir}/image/fsimage,由此可以看出上面名字相同的文件实际是一样的,所以在这里,我建议把dfs.name.dir和dfs.name.edits.dir配置成相同的值,以来提高NameNode的效率。ok,现在就来重点的介绍一下这些文件的用途吧。
fsimage:存储命名空间(实际上就是目录和文件)的元数据信息,文件结构如下:

edits:用来存储对命名空间操作的日志信息,实现NameNode节点的恢复;
fstime:用来存储元数据上一次check point 的时间;
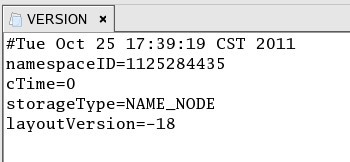
VERSION:用来存储NameNode版本信息,命名空间ID(版本号),内容如下:
/image/fsimage: 上一次提交前的/current/fsimage文件;
源码分析
执行源码位于NameNode类
case FORMAT: {
boolean aborted = format(conf, startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid javac warning
}
.....
}
获取配置路径,执行初始化
具体的实现format的功能是在 org.apache.hadoop.hdfs.server.namenode.FSImage 这个类的format(StorageDirectory sd)方法中
FSImage fsImage = new FSImage(conf, nameDirsToFormat, editDirsToFormat);
try {
FSNamesystem fsn = new FSNamesystem(conf, fsImage);
fsImage.getEditLog().initJournalsForWrite(); if (!fsImage.confirmFormat(force, isInteractive)) {
return true; // aborted
} fsImage.format(fsn, clusterId);
} catch (IOException ioe) {
LOG.warn("Encountered exception during format: ", ioe);
fsImage.close();
throw ioe;
}
元数据的格式化
storage.format(ns);//执行下面的方法进行格式化
private void format(StorageDirectory sd) throws IOException {
sd.clearDirectory(); // create currrent dir
writeProperties(sd);
writeTransactionIdFile(sd, 0);
LOG.info("Storage directory " + sd.getRoot()
+ " has been successfully formatted.");
}
配置项
dfs.namenode.support.allow.format 是否允许进行Namenode format,默认是true
dfs.namenode.name.dir 元数据存储路径,这个参数用于确定将HDFS文件系统的元信息保存在什么目录下。
如果这个参数设置为多个目录,那么这些目录下都保存着元信息的多个备份,使用逗号分割,源码分隔符\\s*,\\s*。
dfs.namenode.edits.dir 操作日志存储路径
HDFS源码分析之NameNode(2)————Format的更多相关文章
- HDFS源码分析之NameNode(1)————启动过程
源码:2.8.0 入口类:org.apache.hadoop.hdfs.server.namenode.NameNode main方法会调用createNameNode 创建 NameNode 实例, ...
- HDFS源码分析:NameNode相关的数据结构
本文主要基于Hadoop1.1.2分析HDFS中的关键数据结构. 1 NameNode 首先从NameNode开始.NameNode的主要数据结构如下: NameNode管理着两张很重要的表: 1) ...
- HDFS源码分析之NameNode(3)————RpcServer
NameNodeRpcServer implements NamenodeProtocols NameNode支持核心即NameNodeRpcServer 实现ClientProtocol 支持客户 ...
- HDFS源码分析二-NameNode实现
2. NameNode 实现( 未完待续 )
- HDFS源码分析EditLog之读取操作符
在<HDFS源码分析EditLog之获取编辑日志输入流>一文中,我们详细了解了如何获取编辑日志输入流EditLogInputStream.在我们得到编辑日志输入流后,是不是就该从输入流中获 ...
- HDFS源码分析心跳汇报之数据块汇报
在<HDFS源码分析心跳汇报之数据块增量汇报>一文中,我们详细介绍了数据块增量汇报的内容,了解到它是时间间隔更长的正常数据块汇报周期内一个smaller的数据块汇报,它负责将DataNod ...
- HDFS源码分析之UnderReplicatedBlocks(一)
http://blog.csdn.net/lipeng_bigdata/article/details/51160359 UnderReplicatedBlocks是HDFS中关于块复制的一个重要数据 ...
- HDFS源码分析数据块校验之DataBlockScanner
DataBlockScanner是运行在数据节点DataNode上的一个后台线程.它为所有的块池管理块扫描.针对每个块池,一个BlockPoolSliceScanner对象将会被创建,其运行在一个单独 ...
- HDFS源码分析数据块复制监控线程ReplicationMonitor(一)
ReplicationMonitor是HDFS中关于数据块复制的监控线程,它的主要作用就是计算DataNode工作,并将复制请求超时的块重新加入到待调度队列.其定义及作为线程核心的run()方法如下: ...
随机推荐
- .NET Core多平台开发体验[1]: Windows
微软在千禧年推出 .NET战略,并在两年后推出第一个版本的.NET Framework和IDE(Visual Studio.NET 2002,后来改名为Visual Studio),如果你是一个资深的 ...
- js,jQuery实现可关闭悬浮框广告特效,兼容(谷歌,火狐,Ie)
注意不能直接用close()命名关闭广告函数,避免冲突. javascript实现方法: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Tr ...
- Day-3: Python基础
数据类型和变量 Python中直接处理的数据类型主要有以下几种: 整数:Python可以直接处理任意大小的整数,无论正负,都可以直接输入处理: 浮点数:浮点数也叫做小数.有普通写法,如:1.1,也有描 ...
- 多线程编程学习四(Lock 的使用).
一.前言 本文要介绍使用Java5中 Lock 对象,同样也能实现同步的效果,而且在使用上更加方便.灵活,主要包括 ReentrantLock 类的使用和ReentrantReadWriteLock ...
- poj 3592 缩点+SPFA
题意:给出一个矩阵,其中#代表墙,不可走,0-9代表权值,*代表可以选择传送.求从0,0点开始出发能获得最大权值. 思路:因为*的出现会有环的情况,先建图连边,将环进行Tarjan缩点,之后再从0,0 ...
- JavaScript中你所不知道的Object(二)--Function篇
上一篇(JavaScript中你所不知道的Object(一))说到,Object对象有大量的内部属性,而其中多数和外部属性的操作有关.最后留了个悬念,就是Boolean.Date.Number.Str ...
- NHibernate教程(7)--并发控制
本节内容 什么是并发控制? 悲观并发控制(Pessimistic Concurrency) 乐观并发控制(Optimistic Concurrency) NHibernate支持乐观并发控制 实例分析 ...
- 原生的AJAX
var XHR=null; if (window.XMLHttpRequest) { // 非IE内核 XHR = new XMLHttpRequest(); } else if (window.Ac ...
- 团队作业8——第二次项目冲刺(Beta阶段)--第六天
一.Daily Scrum Meeting照片 二.燃尽图 三.项目进展 学号 成员 贡献比 201421123001 廖婷婷 16% 201421123002 翁珊 16% 201421123004 ...
- Java学习9——面向对象
(重点:内存分析) 类的定义 //用class关键字定义一个类 class Person { //成员变量定义 private int id; private int age = 20; //方法定义 ...