CHECKDB内部:什么是BlobEater?
DBCC CHECKDB注意到有关数据文件页面。一旦整个表的所有页(或一组表,如果配料已启用-看到同样的博客文章我上面提到的),所有的事实都聚集在一起,他们都应该相互抵消。当有额外的事实(在索引B树都指向同一个页面在一个较低的水平如两页),或丢失的事实(如LOB片段没有任何其他LOB片段或数据/索引记录指向它),则DBCC CHECKDB可以告诉有一个腐败。
由于DBCC CHECKDB正在生成数据库基本上是随机页面所有这些因素(它读取物理顺序表中的页面,而不是逻辑顺序),必须有前聚集可以发生的事实的一些排序。这是使用查询处理器的所有驱动。在每个线程DBCC CHECKDB读取页面,生成的事实,并让他们给查询处理器进行排序和汇总。一旦所有的阅读完毕之后,事实再返还给内部并行线程DBCC CHECKDB找出损坏是否存在。
表明这一机制的画面看起来如下:
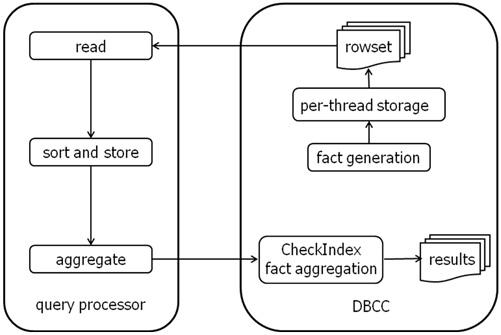
如果你正在做的任何跟踪或分析而DBCC CHECKDB正在运行时,你会看到下面的查询:
DECLARE @BlobEater VARBINARY(8000);
选择@BlobEater = CheckIndex(ROWSET_COLUMN_FACT_BLOB)
FROM <其实行集的内存地址>
GROUP BY ROWSET_COLUMN_FACT_KEY
>>带有ORDER BY
ROWSET_COLUMN_FACT_KEY,
ROWSET_COLUMN_SLOT_ID,
ROWSET_COLUMN_COMBINED_ID,
ROWSET_COLUMN_FACT_BLOB
OPTION(ORDER GROUP);
这个查询的部分的解释里面的SQL Server 2008中记录和即将里面的SQL Server 2012的书,我已经从我的DBCC内幕章下面引用它:
该查询带来的查询处理器和DBCC CHECKDB代码一起执行事实生成,事实排序,事实存储和事实聚集算法。是查询的部分如下:
- @BlobEater这是一个没有以外的其他使用来自任何输出目的的虚拟变量CheckIndex功能(永远不应该有任何,但语法要求的话)。
- CheckIndex(ROWSET_COLUMN_FACT_BLOB)这里面自定义聚合函数DBCC CHECKDB,查询处理器排序和分组的事实为整个事实聚集算法的一部分调用。
- <其实行集的内存地址>这是OLEDB行集的内存地址DBCC CHECKDB提供给查询处理器。查询处理器查询此行集行(包含生成的事实)作为整个事实生成算法的一部分。
- GROUP BY ROWSET_COLUMN_FACT_KEY这触发了查询处理器的聚集。
- >>带有ORDER BY <字段列表>这是仅供内部使用,提供了有序的聚合,凝聚工序语法。正如我先前所解释的,DBCC CHECKDB聚合代码是基于这样的假设,从查询处理器事实的凝集流的顺序被强制(即,它要求每个组内的键的排列顺序是顺序在查询中的四个键)。
- OPTION(订单组)这是一个查询优化器暗示的力量流聚集。它迫使查询优化器进行排序分组列,避免哈希聚集。
CHECKDB内部:什么是BlobEater?的更多相关文章
- sqlserver和Oracle内部的错误数据修复(DBCC、DBMS_REPAIR)
数据库长时间运行后,因断电.操作系统.物理存储等的原因可能会造成数据库内部的逻辑或物理错误,我们可以使用一般的方式尝试修复. 对于sqlserver 我们可以使用DBCC命令: -- sqlserve ...
- 如何在大型的并且有表分区的数据库中进行DBCC CHECKDB操作
如何在大型的并且有表分区的数据库中进行DBCC CHECKDB操作 其实这个问题已经在<SQLSERVER企业级平台管理实践>里徐老师已经讲过了,不过我想用自己的语言再讲详细一些 笔记链接 ...
- 通过ProGet搭建一个内部的Nuget服务器
.NET Core项目完全使用Nuget 管理组件之间的依赖关系,Nuget已经成为.NET 生态系统中不可或缺的一个组件,从项目角度,将项目中各种组件的引用统统交给NuGet,添加组件/删除组件/以 ...
- 微软Azure 经典模式下创建内部负载均衡(ILB)
微软Azure 经典模式下创建内部负载均衡(ILB) 使用之前一定要注意自己的Azure的模式,老版的为cloud service模式,新版为ARM模式(资源组模式) 本文适用于cloud servi ...
- 简单搭建 nuget 内部服务器
搭建 nuget 内部服务器,最好的方式是使用 ProGet,参考博文<用 ProGet 搭建内部的 NuGet 服务器>,好处非常多,但需要使用 SQL Server 数据库,如果不想使 ...
- 用ProGet搭建内部的NuGet服务器
最近团队内部用的一个很简陋的NuGet服务器出问题了,nuget push发包,客户端显示发布成功,服务器上就是没有.懶得再去排查这个问题,早就想换掉这个过于简陋的NuGet服务器,借此机会直接弃旧迎 ...
- topshelf和quartz内部分享
阅读目录: 介绍 基础用法 调试及安装 可选配置 多实例支持及相关资料 quartz.net 上月在公司内部的一次分享,现把PPT及部分交流内容整理成博客. 介绍 topshelf是创建windows ...
- Storm内部的消息传递机制
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 一个Storm拓扑,就是一个复杂的多阶段的流式计算.Storm中的组件 ...
- 如何开发一款堪比APP的微信小程序(腾讯内部团队分享)
一夜之间,微信小程序刷爆了行业网站和朋友圈,小程序真的能如张小龙所说让用户"即用即走"吗? 其功能能和动辄几十兆安装文件的APP相比吗? 开发小程序,是不是意味着移动应用开发的一次 ...
随机推荐
- 移动端H5制作安卓和IOS的坑 持续更新...
移动端H5制作安卓和IOS的坑 持续更新... 前言:最近参加公司的H5页面创意竞赛,又遇到不少页面在不同系统上的坑.踩坑之余,觉得很多之前遇到的知识点都忘了,索性开一篇博文,把这些坑都统一归纳起来, ...
- Android 常见 Memory Leak 原因及解决办法总结
待整理: http://geek.csdn.net/news/detail/50692 背景 在Android开发过程中,我们经常碰到的情况就是在我们不清楚为什么情况下,程序突然出现Crash了.其中 ...
- Codeforces 869C The Intriguing Obsession
题意:有三种颜色的岛屿各a,b,c座,你可以在上面建桥.联通的点必须满足以下条件:1.颜色不同.2.颜色相同且联通的两个点之间的最短路径为3 其实之用考虑两种颜色的即可,状态转移方程也不难推出:F[i ...
- Hashtable 小记
Hashtable 是 JDK 中较早的数据结构了,目前已不再推荐使用了.但抱着学习的目的,还是看了下它的实现. 简介 Hashtable,顾名思义即哈希表,是一种经典的数据结构.其基本结构是一个数组 ...
- Android 跨进程启动Activity黑屏(白屏)的三种解决方案
原文链接:http://www.cnblogs.com/feidu/p/8057012.html 当Android跨进程启动Activity时,过程界面很黑屏(白屏)短暂时间(几百毫秒?).当然从桌面 ...
- EasyARM i.mx287学习笔记——通过modbus tcp控制GPIO
0 前言 本文使用freemodbus协议栈,在EasyARM i.mx287上实现了modbus tcp从机. 在该从机中定义了线圈寄存器.当中线圈寄存器地址较低的4位和EasyARM的P2 ...
- hdu 1885 Key Task(bfs)
http://acm.hdu.edu.cn/showproblem.php?pid=1885 再贴一个链接http://blog.csdn.net/u013081425/article/details ...
- POJ 3616 Milking Time DP题解
典型的给出区间任务和效益值,然后求最大效益值的任务取法. 属于一维DP了. 一维table记录的数据含义:到当前任务的截止时间前的最大效益值是多少. 注意. 这表示当前任务一定要选择,可是终于结果是不 ...
- hdu 1233 还是畅通project(kruskal求最小生成树)
还是畅通project Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Tota ...
- redmine工作流程总结
1.需求调研员和測试员新建问题,问题跟踪为支持,指派给产品经理 2.产品经理对收到的问题进行分类处理,功能类型的,改动跟踪状态为功能,指派给自己.是bug类型的,将跟踪类型改动错误类型,指派给技术经理 ...