深入理解:Linear Regression及其正则方法
这是最近看到的一个平时一直忽略但深入研究后发现这里面的门道还是很多,Linear Regression及其正则方法(主要是Lasso,Ridge, Elastic Net)这一套理论的建立花了很长一段时间,是很多很多人的论文一点点堆起来的一套理论体系.如果你只停留在知道简单的Linear Regression,Lasso, Ridge, Elastic Net的原理,没有深入了解这套理论背后的故事,希望你能从这篇博客中有所收获,当然博主水平有限,也只是稍微深入了一些,如果你是主要做这方面的工作,还望你找一些相关论文来深入学习.
对于常见的Linear Regression我们刚学机器学习的时候会感觉这套理论很简单,损失函数是一个均方误差损失,然后用梯度下降来找最优的系数w即可.无论是数学公式的推到还是代码实现都非常简答.于是很多人都开始了学习下一章,.对于Lasso和Ridge也就是常用的L1正则和L2正则可能有部分人理解起来稍微麻烦一点,网上的教程也很多有的写的也非常好.大家可以取参考一下.这里假设大家对于L1正则是为了让一些相关度低的特征系数变为0从而达到select variable的目的,L2正则是对特征进行shrankage从而让模型更加balance(模型中个特征的系数都很小,因此模型不会受到某几个strong feature的影响)都有所了解,对于Elastic Net估计大家都停留在知道其是L1和L2正则的综合,但是究竟其背后的原理估计没人去深究.这里我来讲讲这套理论的发展历史.从理论一步步建立的过程来让大家对这几个算法有更深入的理解,做到知其然,知其所以然.
首先Linear Regression刚出来的时候效果很好(因为当时数据量不大,计算机性能也不好,Linear Regression已经是比较好的模型)因此被广泛使用,但是基于均方误差损失函数的Linear Regression有一个致命问题就会预测结果l地偏差高方差这个是均方误差损失函数的问题同时模型的解释性会很差,在小规模数据集上还能忍受,但是随着时间的推移,数据量在急剧增大,面对大数据集情况下出现高方差.模型的泛化能力弱如何解决,人们为了解决这个问题提出了L2正则,我们都知道,均方误差损失函数下对于那种噪点的loss会很大(y因为有个平方项),如果噪点恰好在strong featrue上那个loss大家可以脑补一下.为此人们想到了shrankage就是压缩权重系数,这样不论数据偏差多大,每个特征的贡献都会很小,模型整体对于单个特征的依赖就会减弱,这样模型整体的方差就不会很大,但是压缩意味着强特征的效果弱化,自然而然使得bias有所增大,但是就像机器学习模型的经典理论trade off biase and variance一样在这两者中找到一个平衡就好.而压缩权重系数的重任就交给了L2正则,这也是L2正则的特点.因此Ridge Regression理论就建立起来了.参数调好的情况下,其效过确实优于Linear Regression当然也是有前提条件的,对于特征较多,且大部分特征的影响较少的数据集上表现会非常好(Ridge只是L2正则中一个非常经典的算法,后来人们也对其进行了一系列的扩展来让它适应其他情况比如group Ridge就是对特征分组然后压缩等).anyway L2解决了模型的准确率的问题但是可解释性依然没有得到解决,而且当时的计算机算力不行,特征多了计算起来非常费时间,于是人们又开始了新算法的研究之路,这个研究的目的很明确就是来完成L2正则未完成的任务将一些特征压缩到0,这样模型实际用到的特征会很少可解释性得到满足同时计算速度也会大幅提高,当然其具体过程也是一波三折,大家可以仔细研究研究相关论文,最后提出来了L1正则,其思路是尽量把一些特征压缩到0,这样很显然模型的预测biase会变大一些,但是模型的variance会降低,同时计算速度会提高很多而且最重要的是模型的解释性能会变得很强(因为特征少了).因此在一些情况下也广泛使用(使用条件:小到中等数量的特征中等大小影响的数据集上表现比较好).这里说点题外话,在这两个算法提出来之前,人们进行特征选择是用subset selection来做的,就是暴力搜索,找出K个最优特征的组合,这种方法计算起来非常慢(当时人们提出来贪心来加速找近似最优解).所以我们从这个算法的发展过程可以看出来,算法的发展一定是在解决实际问题的基础上一步步演变的,非常有趣.
最后就是L1和L2正则结合的elastic net了,这个算法克服了Lasso在一些场景的限制:
(1)当P>>N(p是特征N是数据量)时Lasso最多只能选N(为什么是N需要用矩阵的知识来简单证明一下)个个特征这显然不是非常合理.
(2)当某些特征的相关性非常高,也就是所谓的组变量,Lasso一般倾向于只选择其中的一个也不关心究竟要选哪一个
(3)对于一般N>P的情况,如果某些特征与预测值之间的相关性很高,经验证明预测的最终性能是Lasso占主导地位相比于Ridge
对于上述三个缺陷,人们就提出来Elastic Net.其思想还是建立在L1正则上面的,其目的是在保证Lasso的优良特性的情况下,克服其缺项.Elastic Net既能select variable同时也能shrankage.他能同时选择相关度很高的组变量.论文上的一个比喻很形象:Elastic Net像一个可伸缩的渔网,可以网住所有的大鱼.这个算法的优化也有一些门道,传统的思路其实比较容易想到对于一个加了L1和L2正则的均方误差损失函数,我们先固定λ2(L2正则项的系数)对所有的权重进行压缩,完成L2正则,然后用Lasso进行压缩,进行特征选择.但是这种方法有一个很致命的缺陷就是很慢,相当于要进行两次正则计算非常耗时.同时这种两次压缩并没有根本减少方差同时还引入了额外的偏差所以这种方法也叫作naive Elastic Net.后来为了优化这个算法又提出了最终我们目前使用的Elastic Net,其思想也很简单,但是很巧,就是将L2正则项同均方误差项进行合并,这样L2正则这一步就直接去掉相当于变成一个权重系数的缩减,因此这个新的表达式就可以近似看成一个Lasso Regression了.这样整个算法的计算时间跟Lasso一样,同时也避免了两次shrankage带来的额外偏差.当然整个算法具体实现细节需要大量的数学证明.这里就一一略过,需要深入了解的可以看看论文,写的很详细.
这里我对Linear Regression及其正则的实际使用发展历史及每个算法要解决的问题进行了一一阐述,可能有些粗糙.但是相信大家对于整个算法的发展过程有了了解后也明白什么样的情况使用什么样的算法,以及各个算法的局限性.下面我来做几个简单的实验demo来看看上面几个算法的效果,主要使用sklearn.
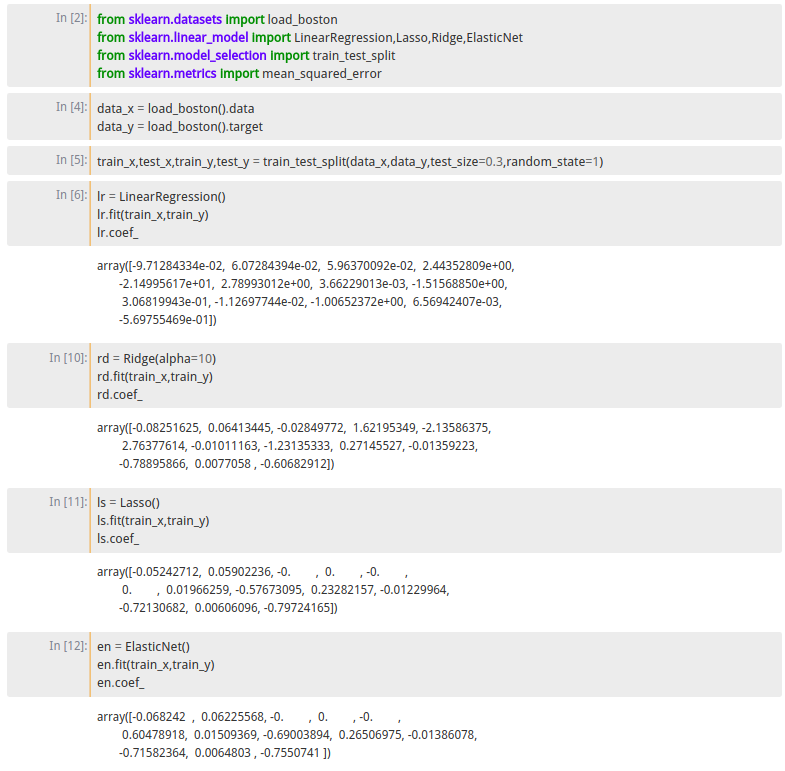
这里的数据集直接使用的是sklearn自带的boston房价数据集,其中特征较少,效果可能没那么明显,但整体来看还是有明显区别,其中lr是LinearRegression模型,其训练模型的系数差异很大,系数的大小代表个特征的权重,特征的强弱关系非常明显.有些特征很强有些很弱.接下来是rd表示Ridge模型(我把惩罚因子alpha稍微调大了一点效果更加明显),可以看出来相比如lr模型其系数都不同程度的进行了压缩,如果我们把alpha继续调大效果会更加明显,当然我这里没有管最终的预测结果,只是让大家感受一下这几个正则的效果.接着看ls表示Lasso模型相比如lr模型其及进行的shrankage同时也进行了变量选择.因为有四个特征的系数变为了0.最后我们看Elastic Net模型相比如Lasso模型其压缩幅度没有那么大,因此只有三个变量被压缩为0.这里看Elastic Net可能效果很差,但是不代表Elastic Net没有用,使用时我们一定要搞清楚自己的数据集的特点,每种数据集主要面对的是什么问题,才能找到最合适的方法.
通过上面的一个简单例子我们可以感受一下各种正则压缩的效果,当然如果纯粹从性能角度来看,我们需要用大量不同数据集来测试,如果大家有兴趣可以找一些数据集来测试一下各种算法的具体效果.这里对于Linear regresion及其正则方法有了一个全面的介绍,也给出了各种算法适合的条件和个算法解决的问题.实际问题中如何使用这些算法,还需要根据具体数据具体问题来分析选取.希望这篇简短的介绍能给大家对Linear regression更深刻的认识.
深入理解:Linear Regression及其正则方法的更多相关文章
- [ML] Bayesian Linear Regression
热身预览 1.1.10. Bayesian Regression 1.1.10.1. Bayesian Ridge Regression 1.1.10.2. Automatic Relevance D ...
- 多重线性回归 (multiple linear regression) | 变量选择 | 最佳模型 | 基本假设的诊断方法
P133,这是第二次作业,考察多重线性回归.这个youtube频道真是精品,用R做统计.这里是R代码的总结. 连续变量和类别型变量总要分开讨论: 多重线性回归可以写成矩阵形式的一元一次回归:相当于把多 ...
- Python 线性回归(Linear Regression) 基本理解
背景 学习 Linear Regression in Python – Real Python,对线性回归理论上的理解做个回顾,文章是前天读完,今天凭着记忆和理解写一遍,再回温更正. 线性回归(Lin ...
- 通俗理解线性回归(Linear Regression)
线性回归, 最简单的机器学习算法, 当你看完这篇文章, 你就会发现, 线性回归是多么的简单. 首先, 什么是线性回归. 简单的说, 就是在坐标系中有很多点, 线性回归的目的就是找到一条线使得这些点都在 ...
- 机器学习方法:回归(一):线性回归Linear regression
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 开一个机器学习方法科普系列:做基础回顾之用,学而时习之:也拿出来与大家分享.数学水平有限,只求易懂,学习与工 ...
- 【模式识别与机器学习】——PART2 机器学习——统计学习基础——Regularized Linear Regression
来源:https://www.cnblogs.com/jianxinzhou/p/4083921.html 1. The Problem of Overfitting (1) 还是来看预测房价的这个例 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- Matlab实现线性回归和逻辑回归: Linear Regression & Logistic Regression
原文:http://blog.csdn.net/abcjennifer/article/details/7732417 本文为Maching Learning 栏目补充内容,为上几章中所提到单参数线性 ...
- Machine Learning – 第2周(Linear Regression with Multiple Variables、Octave/Matlab Tutorial)
Machine Learning – Coursera Octave for Microsoft Windows GNU Octave官网 GNU Octave帮助文档 (有900页的pdf版本) O ...
随机推荐
- Fiddler中设置断点修改Request和Response
Fiddler中设置断点修改Request Fiddler最强大的功能莫过于设置断点了,设置好断点后,你可以修改httpRequest 的任何信息包括host, cookie或者表单中的数据.设置断点 ...
- JS 实现图片的预加载(转载)
图片预加载是web开发中一种应用相当广泛的技术,比如我们在做图片翻转显示等特效的时候,为了让图片在转换的时候不出现等待,我们最好是先让图片下载到本地,然后在继续执行后续的操作. 下面的函数实现了一个我 ...
- java 数据格式验证类
作为一个前端,懂一点java,php之类的,甚好. 我所在的项目前端采用的就是java的spring mvc框架,所以我们也写java,掐指一算,也快一年了. 前端而言,验证是一个坎,绕不过去的,前面 ...
- 再见乱码:5分钟读懂MySQL字符集设置
一.内容概述 在MySQL的使用过程中,了解字符集.字符序的概念,以及不同设置对数据存储.比较的影响非常重要.不少同学在日常工作中遇到的"乱码"问题,很有可能就是因为对字符集与字符 ...
- 老铁,这年头不会点Git真不行!!!
版本控制 说到版本控制,脑海里总会浮现大学毕业是写毕业论文的场景,你电脑上的毕业论文一定出现过这番景象! 毕业论文_初稿.doc 毕业论文_修改1.doc 毕业论文_修改2.doc 毕业论文_修改3. ...
- eclipse导入工程时,出现Some projects cannot be imported because they already exist in the workspace
前提条件: 1.将eclipse中现有的工程javatraining删除,如下图所示, 该复选框不要勾选,点击ok steps: 1.本次打开Eclipse想要把已删除的javatraining工程再 ...
- ssh框架实现员工部门增删改查源码
http://pan.baidu.com/s/1qYLspDM 备注:IDE是eclipse,前端使用bootstrap,数据库是mysql
- mydumper
Mydumper介绍 Mydumper是一个针对MySQL和Drizzle的高性能多线程备份和恢复工具.开发人员主要来自MySQL,Facebook,SkySQL公司.目前已经在一些线上使用了Mydu ...
- 在React中你真的用对了Ajax吗?
通过AJAX加载初始数据 通过AJAX加载数据是一个很普遍的场景.在React组件中如何通过AJAX请求来加载数据呢?首先,AJAX请求的源URL应该通过props传入:其次,最好在component ...
- Git的使用-如何将本地项目上传到Github
默认你的电脑上已经安装了git. 第一步:我们需要先创建一个本地的版本库(其实也就是一个文件夹). 你可以直接右击新建文件夹,也可以右击打开Git bash命令行窗口通过命令来创建. 现在我通过命令行 ...