【DDD】领域驱动设计实践 —— 限界上下文识别
本文从战略层面街上DDD中关于限界上下文的相关知识,并以ECO系统为例子,介绍如何识别上下文。限界上下文(Bounded Context)定义了每个模型的应用范围,在每个Bounded Context中确保领域模型的一致性;上下文图(Context Map)表示各个系统之间关系的总体视图;通过持续集成(Continous Integration)确保多个限界上下文的模型统一。
限界上下文(Bounded Context)
限界上下文(Bounded Context)定义了每个模型的应用范围,在每个Bounded Context中确保领域模型的一致性。不同的限界上下文中,领域模型可以不用保证一致性。通常我们根据团队的组织、软件系统的每个部分的用法及物理表现(如组件划分,数据库模式)来设置模型的边界。
上下文图(Context Map)
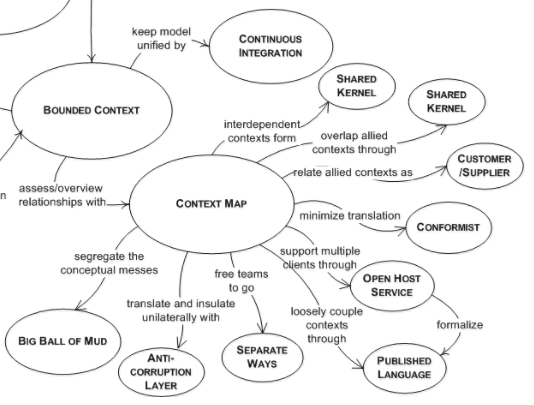
多个系统之间会发生关系,存在交互,这也必然会在各自的Bounded Context上有所表现。上下文图(Context Map)便是表示各个系统之间关系的总体视图。在Context Map中可以有如下几种形式来表征限界上下文之间的关系,他们分别是:
共享内核(Shared Kernel)
当不同团队开发一些紧密相关的应用程序时,团队之间需要进行协调,通常可以将两个团队共享的子集剥离出来形成共享内核(Shared Kernel),双方进行持续集成(Continuous Integration)。由此可见共享内核(Shared Kernel)是业务领域中公共的部分,同时也是团队间容易达成且必须达成共识的领域部分。
客户/供应商(Customer/Supplier)
不同系统之间存在依赖关系时,下游系统依赖上游系统,下游系统是客户,上游系统是供应商,双方协定好需求,由上游系统完成模型的构建和开发,并交付给下游系统使用,之后进行联调、测试。这种模式建立在团队之间友好合作和支持的情况下。
Conformist(追随者)
如果上游系统不合作,这时候“客户/供应商”模式就不凑效了,那么下游系统只能去追随上游系统,下游系统严格遵从上游系统的模型,简化集成。
例如在ECO系统中,社区服务的打赏记录来源于支付系统,支付系统的打赏记录这一模型设计较为友好,且社区服务只是一个简单的查询模型,可以直接追随支付系统的打赏记录模型,集成简单快速。
防腐层(Anticorruption Layer)
如果上游系统的模型不友好,不适合下游系统的场景,但是下游系统又必须依赖于这些模型,这时候我们需要使用防腐层(Anticorruption Layer)模式将上游系统的影响降低。这种模式也是非常常见的,通常出现在系统间对接时,使用trasport+resolver的方式完成服务调用和协议转换。其中的resovler便承担了防腐的作用。
公开主机服务(Open Host Service)
公开主机服务(Open Host Service)能够允许系统将一组service公开出去公其他系统访问,在互通模型的同时,减少了系统间的耦合。
此类模式是使用最多的。系统之间的交互通常是使用该模式来完成的,而且现在很火的微服务架构也可以理解为此类模式的实现形式。
各行其道(Separate Way)
当两个系统之间的关系并非必不可少时,两者完全可以彼此独立,各自独立建模,独立发展,互不影响。
模式图谱
思考
综合上述模式,由上而下耦合越来越低,模型的共享程度也越来越低,在实践中,使用得最多的应当是:防腐层 + 公开主机服务的搭配使用。实际开发中,一个上游系统会面对多个下游系统做过多定制化的建模,且由于团队组织和管理上的天然隔离,团队合作的紧密度通常并不会那么高,因此,要做到“共享内核”和“客户/供应商”模式是比较困难的。我认为如今发展的如火如荼的微服务架构便是“防腐层 + 公开主机服务”的实现形式,使用RESTful契约公开主机服务,在业务模型上使用防腐层完成隔离和适配,达到共享模型和降低耦合的平衡。
“共享内核”模式在通用业务领域较为常见,在细分业务领域中,通常由几家厂商抽象出通用的业务模型,并产品化,售卖给各个甲方企业,在实施集成过程中,根据甲方的个性化诉求,在“共享内核”上做二次开发。比如在网上银行这一细分的业务领域中,大小银行的网银系统基本上被科蓝和宇信两家公司承包,且两家公司都已经产品化,具体项目实施时,只需要做一些二次开发,便可快速集成上线。
“客户/供应商”模式个人觉得实施起来会比较困难,毕竟是跨团队协作,及时领头上司是一个,如果这个关键人物不去把控系统设计,那么业务模型上的一致性是很难保证的,最后估计会演变为“防腐层”模式;如果这个关键人物会实际参与到系统建模和设计中,那实际上编程了一个大的团队了,也就无所谓“客户/供应商”模式了,都是自己了。
在ECO系统中的实践
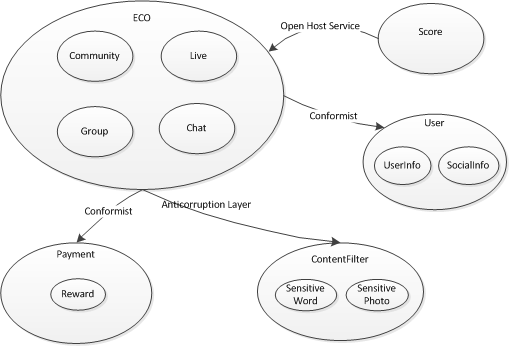
结合上述理论知识,及实际实践,我们发现ECO系统中主要使用到了:“追随者”、“防腐层”、“公开主机服务”三种模式,他们的使用场景分别为:
- ECO直接使用支付系统的“打赏记录”模型作为其查询模型,使用到了“追随者”模式;
- ECO访问内容过滤服务,对内容过滤服务的访问模型进行了适配,这里使用到了“防腐层”模式;
- ECO系统通过RESTful服务提供内网服务供其他业务系统内网访问,比如积分系统获取用户的发帖/评论情况等,使用到了“公开主机服务”模式;
综上,我们可以画出ECO系统的Content Map,如下:
【DDD】领域驱动设计实践 —— 限界上下文识别的更多相关文章
- DDD领域驱动设计和实践(转载)
-->目录导航 一. DDD领域驱动设计介绍 1. 什么是领域驱动设计(DDD) 2. 领域驱动设计的特点 3. 如果不使用DDD? 4. 领域驱动设计的分层架构和构成要素 5. 事务脚本和领域 ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(3)
上一篇:<DDD 领域驱动设计-谈谈 Repository.IUnitOfWork 和 IDbContext 的实践(2)> 这篇文章主要是对 DDD.Sample 框架增加 Transa ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(2)
上一篇:<DDD 领域驱动设计-谈谈 Repository.IUnitOfWork 和 IDbContext 的实践(1)> 阅读目录: 抽离 IRepository 并改造 Reposi ...
- DDD领域驱动设计落地实践(十分钟看完,半小时落地)
一.引子 不知今年吹了什么风,忽然DDD领域驱动设计进入大家视野.该思想源于2003年 Eric Evans编写的"Domain-Driven Design领域驱动设计"简称DDD ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(1)
好久没写 DDD 领域驱动设计相关的文章了,嘎嘎!!! 这几天在开发一个新的项目,虽然不是基于领域驱动设计的,但我想把 DDD 架构设计的一些东西运用在上面,但发现了很多问题,这些在之前的短消息项目中 ...
- DDD 领域驱动设计-谈谈 Repository、IUnitOfWork 和 IDbContext 的实践(转)
http://www.cnblogs.com/xishuai/p/ddd-repository-iunitofwork-and-idbcontext.html 好久没写 DDD 领域驱动设计相关的文章 ...
- 【DDD】领域驱动设计实践 —— UI层实现
前面几篇blog主要介绍了DDD落地架构及业务建模战术,后续几篇blog会在此基础上,讲解具体的架构实现,通过完整代码demo的形式,更好地将DDD的落地方案呈现出来.本文是架构实现讲解的第一篇,主要 ...
- 浅谈我对DDD领域驱动设计的理解
从遇到问题开始 当人们要做一个软件系统时,一般总是因为遇到了什么问题,然后希望通过一个软件系统来解决. 比如,我是一家企业,然后我觉得我现在线下销售自己的产品还不够,我希望能够在线上也能销售自己的产品 ...
- DDD 领域驱动设计-商品建模之路
最近在做电商业务中,有关商品业务改版的一些东西,后端的架构设计采用现在很流行的微服务,有关微服务的简单概念: 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成.系统中的各个微服务可被独 ...
随机推荐
- python-插入排序
所谓插入排序,就是检查第i个数字,若比它的左边的数字小,则进行交换,一直持续这个动作,直到它的左边的数字比它还要小,则停止. #coding:utf-8def insertion_sort(nums) ...
- 剑指offer---包含min的栈
思路:该题主要是补充栈的min方法,例如:栈有pop.push.peek等内置方法,每次调用这些方法就能返回个结果或者有个响应,本题意在补充min方法,使得每次调用min方法都能得到栈中最小值,保证每 ...
- Eclipse错误:Implicit super constructor ClassName is undefined for default constructor. Must define an explicit constructor
public class Test01 { private String name; private int age; public Test01(String name){ this.name = ...
- string::npos,一个很大的数
string::npos,这是一个很大的数 npos 是这样定义的: static const size_type npos = -1; 因为 string::size_type (由字符串配置器 a ...
- Java常用文件操作-2
上篇文章记录了常用的文件操作,这里记录下通过SSH服务器操作Linux服务器的指定路径下的文件. 这里用到了第三方jar包 jsch-0.1.53.jar, jsch-api 1.删除服务器上指定路径 ...
- Code:Blocks中文输出乱码解决方法
0x01 问题描述 将CB的编码格式设置为UTF-8之后,在CMD窗口输出中文乱码. 0x02 解决办法 控制台显示的时候缺省的是使用系统默认的字符集,比如windows下用的是GBk,但是默认情况下 ...
- shell 变量的使用
变量定义 name="xiaoming"; age=12: 变量名和等号之间不能有空格,否则会报错,同时变量名的命名和其他语言的命名规则基本一样 首个字符必须为字母(a-z,A-Z ...
- C++ Socket学习记录 -1
1.IP的转换 1)正转换 结构 sockaddr_in 在C++ 中表明一个IP地址结构,包含地址家,端口以及IP地址等信息 如: sockaddr_in addr; addr.sin_family ...
- vue插件编写与实战
关于 微信公众号:前端呼啦圈(Love-FED) 我的博客:劳卜的博客 知乎专栏:前端呼啦圈 前言 热爱vue开发的同学肯定知道awesome-vue 这个github地址,里面包含了数以千计的vue ...
- Python下的OpenCV学习 02 —— 图像的读取与保存
OpenCV提供了众多对图片操作的函数,其中最基本的就是图片的读取与输出了. 一.读取图片 利用OpenCV读取一张图片是非常容易的,只需要用到 imread() 函数,打开shell或者cmd,进入 ...