大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
http://www.aboutyun.com/thread-6855-1-1.html
个人观点:大数据我们都知道hadoop,但并不都是hadoop.我们该如何构建大数据库项目。对于离线处理,hadoop还是比较适合的,但是对于实时性比较强的,数据量比较大的,我们可以采用Storm,那么Storm和什么技术搭配,才能够做一个适合自己的项目。下面给大家可以参考。
可以带着下面问题来阅读本文章:
1.一个好的项目架构应该具备什么特点?
2.本项目架构是如何保证数据准确性的?
3.什么是Kafka?
4.flume+kafka如何整合?
5.使用什么脚本可以查看flume有没有往Kafka传输数据
做软件开发的都知道模块化思想,这样设计的原因有两方面:
一方面是可以模块化,功能划分更加清晰,从“数据采集--数据接入--流失计算--数据输出/存储”
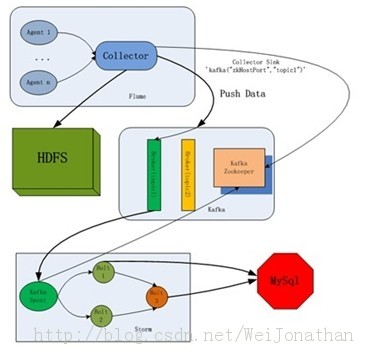
Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。在我们系统中由kafka来接收。
- $tar zxvf apache-flume-1.4.0-bin.tar.gz/usr/local
复制代码
Flume启动命令:
- $bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console
复制代码
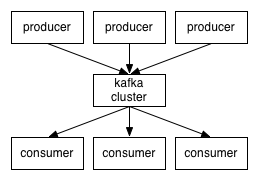
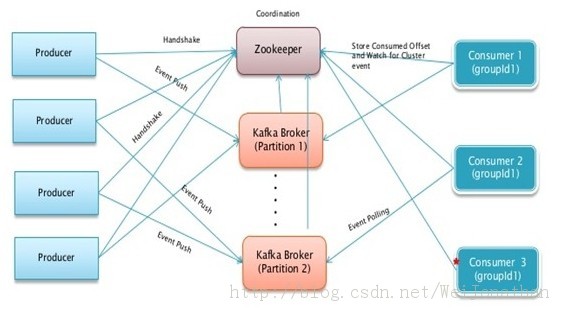
Kafka
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
- > tar xzf kafka-<VERSION>.tgz
- > cd kafka-<VERSION>
- > ./sbt update
- > ./sbt package
- > ./sbt assembly-package-dependency
复制代码
- > bin/zookeeper-server-start.shconfig/zookeeper.properties
- > bin/kafka-server-start.shconfig/server.properties
复制代码
这里是官网上的教程,kafka本身有内置zookeeper,但是我自己在实际部署中是使用单独的zookeeper集群,所以第一行命令我就没执行,这里只是些出来给大家看下。
- zookeeper.connect=nutch1:2181
复制代码
(2)Create a topic
- > bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
- > bin/kafka-list-topic.sh --zookeeperlocalhost:2181
复制代码
(3)Send some messages
- > bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test
复制代码
(4)Start a consumer
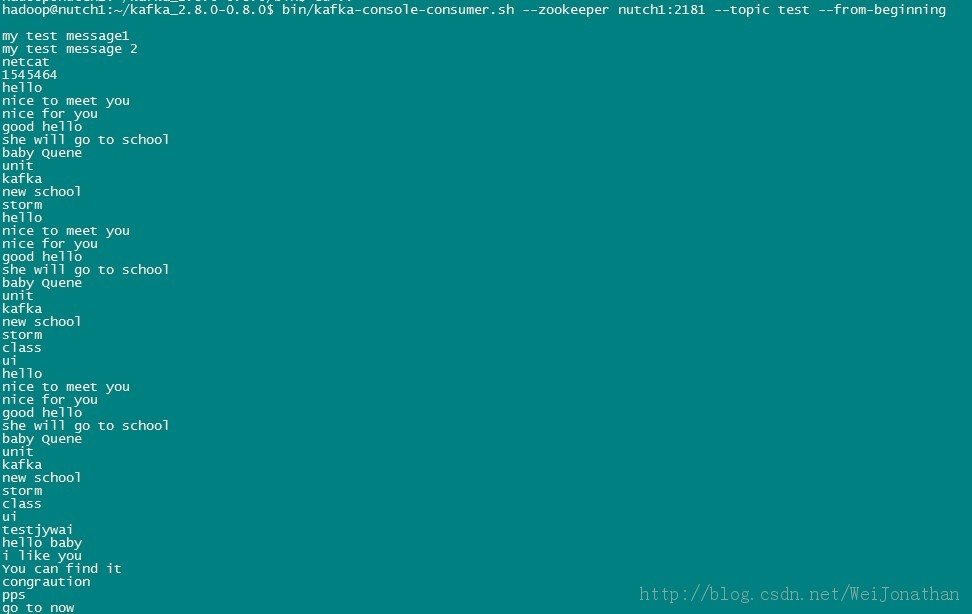
- > bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning
复制代码
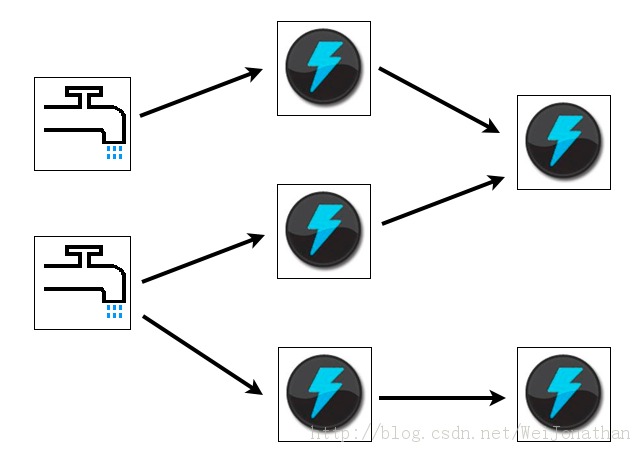
- 简单的编程模型。类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性。
- 可以使用各种编程语言。你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
- 容错性。Storm会管理工作进程和节点的故障。
- 水平扩展。计算是在多个线程、进程和服务器之间并行进行的。
- 可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
- 快速。系统的设计保证了消息能得到快速的处理,使用ØMQ作为其底层消息队列。(0.9.0.1版本支持ØMQ和netty两种模式)
- 本地模式。Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c


- #2个channel和2个sink的配置文件 这里我们可以设置两个sink,一个是kafka的,一个是hdfs的;
- a1.sources = r1
- a1.sinks = k1 k2
- a1.channels = c1 c2
复制代码
具体配置大伙根据自己的需求去设置,这里就不具体举例了


- storm-0.9.0.1/bin/storm jar storm-start-demo-0.0.1-SNAPSHOT.jar com.storm.topology.MyTopology
复制代码
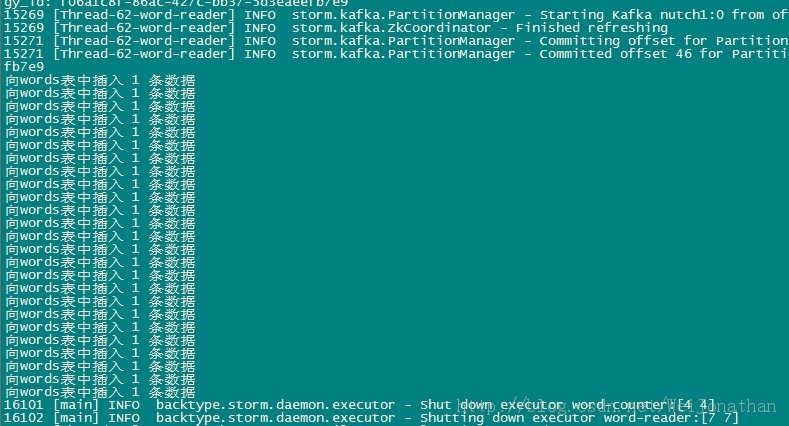
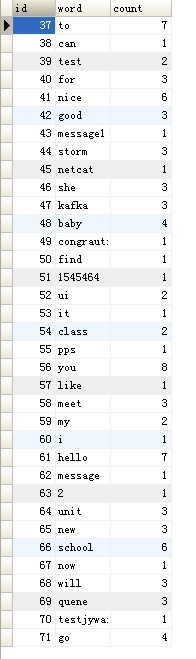
到这里我们的整个整合就完成了!
大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合的更多相关文章
- 转:大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
虽然比较久,但是这套架构已经很成熟了,记录一下 一般数据流向,从“数据采集--数据接入--流失计算--数据输出/存储”<ignore_js_op> 1).数据采集 负责从各节点上实时采集数 ...
- flume-ng+Kafka+Storm+HDFS 实时系统组合
http://www.aboutyun.com/thread-6855-1-1.html
- flume-ng+Kafka+Storm+HDFS 实时系统搭建
转自:http://www.tuicool.com/articles/mMrQnu7 一 直以来都想接触Storm实时计算这块的东西,最近在群里看到上海一哥们罗宝写的Flume+Kafka+Storm ...
- [转]flume-ng+Kafka+Storm+HDFS 实时系统搭建
http://blog.csdn.net/weijonathan/article/details/18301321 一直以来都想接触Storm实时计算这块的东西,最近在群里看到上海一哥们罗宝写的Flu ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
- 大数据入门第十八天——kafka整合flume、storm
一.实时业务指标分析 1.业务 业务: 订单系统---->MQ---->Kakfa--->Storm 数据:订单编号.订单时间.支付编号.支付时间.商品编号.商家名称.商品价格.优惠 ...
- 大数据学习——kafka+storm+hdfs整合
1 需求 kafka,storm,hdfs整合是流式数据常用的一套框架组合,现在 根据需求使用代码实现该需求 需求:应用所学技术实现,kafka接收随机句子,对接到storm中:使用storm集群统计 ...
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
随机推荐
- Django – vicalloy's trac
Django – vicalloy's trac Search:
- berserkJS(大名:狂暴JS / 昵称:疯子JS)
极分享:高质分享+专业互助=没有难做的软件+没有不得已的加班 http://www.finalshares.com/read-6763?f=g-20
- homework01
第一眼看到这个题目的时候就意识到这道题应该使用动态规划来解决,但因代码能力有限,因此从一维的问题开始解决,用C语言编写,代码如下: int maxsum(int *p,int size){ int i ...
- Modbus Poll :Byte Missing Error或CRC Error
原因: 1.通信线路受干扰或是路线接触不良: 用显示器测量物理电平信号 2.从机工作不正常: 检测电源不正常或查程序bug 3.PC主机串口不正常: PC串口2.3脚答短接用串口调试器测 ...
- java图片处理
import java.awt.image.BufferedImage; import java.io.File; import java.io.FileOutputStream; import ja ...
- Aizu 2302 On or Off dfs/贪心
On or Off Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://acm.hust.edu.cn/vjudge/contest/view.act ...
- Aizu 2309 Sleeping Time DFS
Sleeping Time Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://acm.hust.edu.cn/vjudge/contest/view ...
- Nginx+tomcat 做负载均衡
架构描述 前端一台nginx服务器做负载均衡器,后端放N台tomcat组成集群处理服务,通过nginx转发到后面(注:没做动静分离,静态动态全部都转给tomcat) 优点:实现了可弹性化的架构,在压力 ...
- maven配置编译路径
在build标签下添加 <build> <sourceDirectory>src/main/java</sourceDirectory> <resources ...
- android Animation 动画效果介绍
Android的animation由四种类型组成 XML中 alpha 渐变透明度动画效果 scale 渐变尺寸伸缩动画效果 translate 画面转换位置移动动画效果 rotate 画面转移旋转动 ...